


In diesem Artikel wird hauptsächlich die in Python entworfene und implementierte Taschenrechnerfunktion vorgestellt. Er analysiert die regulären, Zeichenfolgen- und numerischen Operationen sowie andere verwandte Operationsfähigkeiten von Python3.5, um die Taschenrechnerfunktion in Form eines vollständigen Beispiels zu implementieren kann darauf verweisen
Das Beispiel in diesem Artikel beschreibt die in Python entworfene und implementierte Taschenrechnerfunktion. Teilen Sie es als Referenz mit allen. Die Details lauten wie folgt:
Durch die Verwendung von PYTHON zum Entwerfen und Verarbeiten der Funktionen des Rechners, wie zum Beispiel:
1 - 2 * ( (60- 30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3)/(16-3*2) )
Meine Grundidee bei der Verarbeitung von Berechnungen ist:
Die Idee zur Lösung des Problems besteht darin, dass die inneren Klammeroperationen durchgeführt werden müssen Zuerst werden die Operationen mit den äußeren Klammern verarbeitet - zuerst das Prinzip der Multiplikation und Division, dann die Addition und Subtraktion:
1. Regularisieren Sie die vom Benutzer eingegebene Zeichenfolge und beurteilen Sie sie dann, um festzustellen, ob die Berechnungsformel Klammern enthält. Wenn ja, regulieren Sie zunächst die Berechnungsformel, rufen Sie zunächst alle Daten in der innersten Schicht ab und berechnen Sie sie dann einzeln.
Die zu verwendenden regulären Regeln sind:
inner = re.search("\([^()]*\)", calc_input)2. Ersetzen Sie das durch die Berechnungsformel in Klammern berechnete Ergebnis durch das Original. Die Position der ursprünglichen Formel, die wiederholten Operatoren werden vor der Berechnung separat verarbeitet
Die Funktion wiederholter Vorgänge, die verarbeitet werden müssen, ist
def del_double(str):
str = str.replace("++", "+")
str = str.replace("--", "-")
str = str.replace("+-","-")
str = str.replace("- -","-")
str = str.replace("+ +","+")
return str3, und dann nacheinander Entfernen Sie die Klammern von innen nach außen und führen Sie die Berechnung durch, und Ersetzen Sie die Positionen
calc_input = calc_input.replace(inner.group(), str(ret))
durch die berechneten Ergebnisse bzw. ersetzen Sie die ursprüngliche Berechnungsformel
4. Holen Sie sich abschließend die Formel ohne Klammern und rufen Sie die Berechnungssteuerung auf Was bei der Berechnung beachtet werden muss, ist die Verarbeitung von negativen Vorzeichen und Zahlen zusammen mit *.
Das spezifische Logikdiagramm lautet:
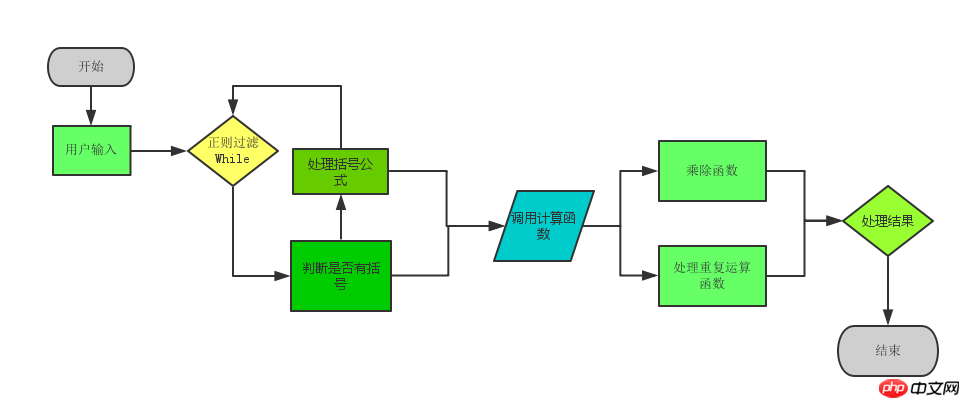
Das Folgende ist der vollständige Code:
#!/usr/bin/env python3.5
# -*-coding:utf8-*-
import re
a =r'1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3)/(16-3*2))'
# */运算函数
def shengchu(str):
calc = re.split("[*/]",str) #用*/分割公式
OP = re.findall("[*/]",str) #找出所有*和/号
ret = None
for index,i in enumerate(calc):
if ret:
if OP[index-1] == "*":
ret *= float(i)
elif OP[index-1] == "/":
ret /= float(i)
else:
ret = float(i)
return ret
# 去掉重复运算,和处理特列+-符号
def del_double(str):
str = str.replace("++", "+")
str = str.replace("--", "-")
str = str.replace("+-","-")
str = str.replace("- -","-")
str = str.replace("+ +","+")
return str
# 计算主控制函数
def calc_contrl(str):
tag = False
str = str.strip("()") # 去掉最外面的括号
str = del_double(str) # 调用函数处理重复运算
find_ = re.findall("[+-]",str) # 获取所有+- 操作符
split_ = re.split("[+-]",str) #正则处理 以+-操作符进行分割,分割后 只剩*/运算符
if len(split_[0].strip()) == 0: # 特殊处理
split_[1] = find_[0] + split_[1] # 处理第一个数字前有“-”的情况,得到新的带符号的数字
# 处理第一个数字前为负数“-",时的情况,可能后面的操作符为“-”则进行标记
if len(split_) == 3 and len(find_) ==2:
tag =True
del split_[0] # 删除原分割数字
del find_[0]
else:
del split_[0] # 删除原分割数字
del find_[0] # 删除原分割运算符
for index, i in enumerate(split_):
# 去除以*或/结尾的运算数字
if i.endswith("* ") or i.endswith("/ "):
split_[index] = split_[index] + find_[index] + split_[index+1]
del split_[index+1]
del find_[index]
for index, i in enumerate(split_):
if re.search("[*/]",i): # 先计算含*/的公式
sub_res = shengchu(i) #调用剩除函数
split_[index] = sub_res
# 再计算加减
res = None
for index, i in enumerate(split_):
if res:
if find_[index-1] == "+":
res += float(i)
elif find_[index-1] == "-":
# 如果是两个负数相减则将其相加,否则相减
if tag == True:
res += float(i)
else:
res -= float(i)
else:
# 处理没有括号时会出现i 为空的情况
if i != "":
res = float(i)
return res
if __name__ == '__main__':
calc_input = input("请输入计算公式,默认为:%s:" %a).strip()
try:
if len(calc_input) ==0:
calc_input = a
calc_input = r'%s'%calc_input # 做特殊处理,保持字符原形
flag = True # 初始化标志位
result = None # 初始化计算结果
# 循环处理去括号
while flag:
inner = re.search("\([^()]*\)", calc_input)# 先获取最里层括号内的单一内容
#print(inner.group())
# 有括号时计算
if inner:
ret = calc_contrl(inner.group()) # 调用计算控制函数
calc_input = calc_input.replace(inner.group(), str(ret)) # 将运算结果,替换原处理索引值处对应的字符串
print("处理括号内的运算[%s]结果是:%s" % (inner.group(),str(ret)))
#flag = True
# 没有括号时计算
else:
ret = calc_contrl(calc_input)
print("最终计算结果为:%s"% ret)
#结束计算标志
flag = False
except:
print("你输入的公式有误请重新输入!")Ergänzung:
Liste der regulären PYTHON-Ausdrücke:
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| w | 匹配字母数字 |
| W | 匹配非字母数字 |
| s | 匹配任意空白字符,等价于 [tnrf]. |
| S | 匹配任意非空字符 |
| d | 匹配任意数字,等价于 [0-9]. |
| D | 匹配任意非数字 |
| A | 匹配字符串开始 |
| Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| z | 匹配字符串结束 |
| G | 匹配最后匹配完成的位置。 |
| b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'erb' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| B | 匹配非单词边界。'erB' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| n, t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| 1...9 | 匹配第n个分组的子表达式。 |
| 10 | 匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
Das obige ist der detaillierte Inhalt vonVollständige Beispielfreigabe der Funktionsimplementierung des Python-Designrechners. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



