


Alle Blog-Codes sind diese Version
2. Systemumgebung: Win7 64-Bit-System
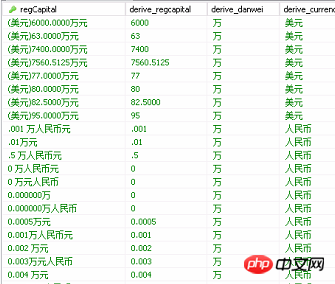
Einige Daten-Screenshots sind wie folgt: Das erste Feld ist das Originalfeld, und die nächsten drei sind die bereinigten Felder in der Datenbank. Auf den ersten Blick sind die Daten relativ regulär, ähnlich wie (Währungsbetrag Zehntausend Yuan) Auf diese Weise habe ich darüber nachgedacht, SQL zu verwenden, um bedingte Urteile zu schreiben und sie einheitlich in die Einheit „Zehntausend Yuan“ umzuwandeln. Allerdings könnte ich ein SQL-Skript verwenden, um die Zeichenfolge abzufangen Später stellte ich fest, dass die Daten unregelmäßig waren und es zu viele bedingte Beurteilungen gab und die Reinigungsqualität nicht gut war. Natürlich haben einige keine Klammern davor, einige Felder enthalten keine Währung, einige Zahlen schon keine Ganzzahlen, und einige haben keine 10.000 Zeichen. Wenn die beiden Felder als Zahlen und in der Einheit „10.000 Yuan“ gespeichert werden, wird es kompliziert, das SQL-Skript zu schreiben Kann Zahlen aus Text extrahieren. Reguläre Ausdrücke werden häufig in Where-Bedingungen verwendet. Wenn jemand weiß, dass MySQL eine Funktion hat, die dem Filtern von Text ähnelt, um Zahlen aus Text zu extrahieren, können Sie mir sagen, dass Sie nicht so viel Geld ausgeben müssen . Für viel Aufwand nutzen Sie einfach Kettle als Werkzeug. Am besten erlernen und nutzen Sie das Werkzeug flexibel.
In Kombination mit der Erfahrung mit Python verfügt Python über viele Funktionen zum Filtern von Zeichenfolgen. Diese Methode wird im späteren Code zum Filtern von Text verwendet.
Beeilen Sie sich nicht, zuerst den Code zu schreiben. Dies ist sehr wichtig In die richtige Richtung erhalten Sie mit halbem Aufwand das doppelte Ergebnis. Der Rest der Zeit ist Code. Der Prozess der Implementierung von Logik und des Debuggens von Code.
Die letzte Datenbereinigung, die ich erreichen möchte, besteht darin, das Fondsfeld in eine Kombination aus [Betrag + Einheit + jede Währung] oder [Betrag + Einheit] umzuwandeln ] + Einheitliche RMB-Währung] (Wechselkursumrechnung), dies kann in zwei oder drei Schritten erfolgen
(Einheiten sind unterteilt in Zehntausende und ohne Zehntausende, und Währungen werden in RMB und bestimmte Fremdwährungen unterteilt)
Die Einheit in der ersten Schritt ist nicht Der digitale Teil von Zehntausend/10000, der digitale Teil von Zehntausend bleibt unverändert
Die Währung ist RMB, die ersten beiden Felder bleiben erhalten unverändert, nein Der numerische Teil wird in eine Zahl geändert * Der Wechselkurs jeder Fremdwährung zu RMB, die Einheit bleibt unverändert und ist im zweiten Schritt immer noch der einheitliche „Zehntausend“
Daraus haben wir begonnen, ihn Schritt für Schritt zu zerlegen und zunächst den Reinigungslogikteil zu klären
① Feldwert = „2000 Yuan“, die erste Reinigung 2000 不含万 人民币
② Feldwert = „20 Millionen Yuan“, die erste Reinigung 2000 万 人民币
③ Feldwert = „20 Millionen Yuan“ Fremdwährung“, die erste Reinigung 2000 万 外币
#二次处理条件case when 单位=‘万’ then 金额 else 金额/10000 end as 第二次金额
①Feldwert = „2000 Yuan RMB“0.2 万 人民币
②Feldwert = „20 Millionen RMB“2000 万 人民币
③Feldwert = „20 Millionen Fremdwährung“2000 万 外币
Hinweis: Wenn die oben genannten Anforderungen erfüllt sind, ist die Reinigung abgeschlossen. Wenn Sie das Gerät in RMB umrechnen möchten, führen Sie die folgenden drei Reinigungen durch
Wenn die letzte Anforderung darin besteht, die Währung in einheitliche RMB umzuwandeln, können wir einfach die Bedingungen schreiben basierend auf der zweiten Reinigung,
#三次处理条件case when 币种=‘人民币’ then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额
①Feldwert = „2000 Yuan RMB“0.2 万 人民币
②Feldwert = „20 Millionen RMB“2000 万 人民币
③Feld Wert = „20 Millionen Fremdwährung“2000*外币兑换人民币汇率 万 人民币
Währung und Einheit sind nur zwei Situationen, die leicht zu schreiben sind
Diese Bedingung ist einfach. Wenn der Wert der Währung im Zeichen erscheint, stellen Sie einfach das neue Feld auf den Wert dieser Währung ein.
Diese Bedingung ist ebenfalls einfach. Wenn das Wort zehntausend vorkommt, ist die Einheitsvariable = „zehntausend“. nicht erscheint, soll die Einheitsvariable gleich „zehntausend ausschließen“ sein. Dies wurde geschrieben, um das Schreiben bedingter Urteile bei der sekundären Verarbeitung von Zahlen im nächsten Schritt zu erleichtern.
Stellen Sie sicher, dass der logische Wert nach der Reinigung mit dem ursprünglichen Wert übereinstimmt Das heißt, wenn es ein solches Feld gibt, werden aus 300,01 Millionen nach der Reinigung auch 10.000 Yuan.
filter(str.isdigit,字段的值)Das erste, was ich über diesen Code weiß, ist, dass er die Zahlen aus dem Text extrahieren kann, indem er die Felder gruppiert und aggregiert. Die extrahierten Werte sind nicht vorhanden haben mehr Dezimalpunkte, wie zum Beispiel „200.100“. Die herausgenommene Zahl ist 2001. Offensichtlich ist diese Zahl falsch, daher müssen Sie überlegen, ob es einen Dezimalpunkt gibt Identisch mit dem Originalfeldfilter(str.isdigit,‘20.01万’)
#带小数点的以小数点分割 取出小数点前后部分进行拼接if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)#单位 以万和不含万 为统一if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万' #币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'#coding:utf-8from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_datafor data in data_tuple:
item={}#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])if data[-2]:if len(data[-2]) >0 :
info=data[-2].encode('utf-8')else:
info=''if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万'if '美元' in info:
derive_currency='美元'elif '港币' in info:
derive_currency = '港币'elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'elif '澳元' in info:
derive_currency = '澳元'elif '英镑' in info:
derive_currency = '英镑'elif '加拿大元' in info:
derive_currency = '加拿大元'elif '日元' in info:
derive_currency = '日元'elif '港币' in info:
derive_currency = '港币'elif '法郎' in info:
derive_currency = '法郎'elif '欧元' in info:
derive_currency = '欧元'elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)#print len(old_data)for i in range(len(old_data)):if not old_data[i] :
old_data[i]=''else:pass
data2=old_data[i].replace('"','')
item[i+1]=data2print item[1] #插入测试环境 的表
project2.insert(item=item,db='local_db')
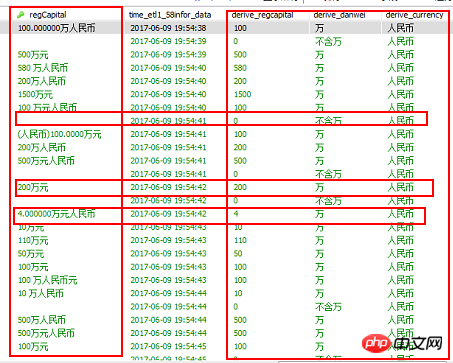
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestodayDas obige ist der detaillierte Inhalt vonPython-Verarbeitungsbeispiele für unordentliche Textdaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



