


In diesem Artikel werden hauptsächlich relevante Informationen für ein tieferes Verständnis der Implementierungsprinzipien von Map in Java vorgestellt. Freunde in Not können sich auf
1. Die Datenstruktur von HashMapumfasst Arrays und verknüpfte Listen zum Speichern von Daten, aber diese beiden sind im Grunde zwei Extreme.
ArrayDas Array-Speicherintervall ist kontinuierlich und beansprucht viel Speicher, sodass der Platz sehr komplex ist. Allerdings ist die zeitliche Komplexität der
binären Suchefür Arrays gering, O(1); die Eigenschaften von Arrays sind: einfach zu adressieren, schwer einzufügen und zu löschen; 🎜>Verknüpfte Liste
Das Speicherintervall der verknüpften Liste ist diskret und der belegte Speicher ist relativ locker, sodass die räumliche Komplexität sehr gering, die zeitliche Komplexität jedoch sehr groß ist und O erreicht (N).Die Merkmale verknüpfter Listen sind: schwer zu adressieren, einfach einzufügen und zu löschen.
Hash-Tabelle
Können wir also die Eigenschaften der beiden kombinieren und eine Datenstruktur erstellen, die leicht zu adressieren und leicht einzufügen und zu löschen ist? Die Antwort lautet: Ja, dies ist die Hash-Tabelle, die wir erwähnen werden. Hash-Tabelle (Hash-Tabelle) erfüllt nicht nur die Bequemlichkeit der Datensuche, sondern nimmt auch nicht zu viel Inhaltsraum ein und ist sehr bequem zu verwenden.Es gibt viele verschiedene Implementierungsmethoden für Hash-Tabellen Folgen Die Erklärung ist eine der am häufigsten verwendeten Methoden - die Reißverschlussmethode, die wir als „Array verknüpfter Listen
“ verstehen können, wie im Bild gezeigt:
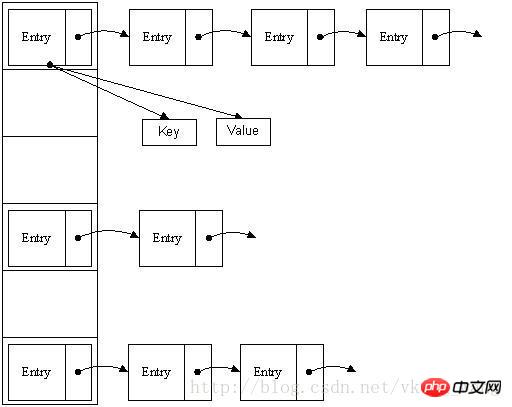
Array + verknüpfter Liste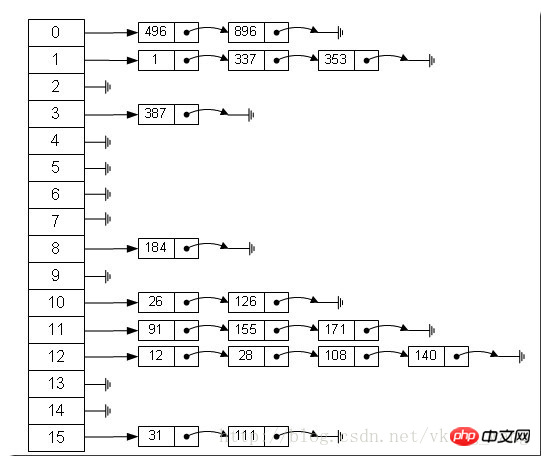 in einem Array mit einer Länge besteht 16, jedes Element speichert den Kopfknoten einer verknüpften Liste. Nach welchen Regeln werden diese Elemente im Allgemeinen durch hash(key)%len, dh den Hashwert des Elementschlüssels, gespeichert? In der obigen Hash-Tabelle werden beispielsweise 12%16=12, 28%16=12, 108%16=12, 140%16=12 gespeichert am Array-Index 12. 🎜>HashMap ist tatsächlich als lineares Array implementiert, sodass wir verstehen können, dass der Container zum Speichern von Daten ein lineares Array ist. Dies kann uns verwirren, wie ein lineares Array über einen Schlüsselwert auf Daten zugreifen kann Paare? HashMap führt zunächst einen
in einem Array mit einer Länge besteht 16, jedes Element speichert den Kopfknoten einer verknüpften Liste. Nach welchen Regeln werden diese Elemente im Allgemeinen durch hash(key)%len, dh den Hashwert des Elementschlüssels, gespeichert? In der obigen Hash-Tabelle werden beispielsweise 12%16=12, 28%16=12, 108%16=12, 140%16=12 gespeichert am Array-Index 12. 🎜>HashMap ist tatsächlich als lineares Array implementiert, sodass wir verstehen können, dass der Container zum Speichern von Daten ein lineares Array ist. Dies kann uns verwirren, wie ein lineares Array über einen Schlüsselwert auf Daten zugreifen kann Paare? HashMap führt zunächst einen
statischen
Attribute umfassen den Attributschlüssel und Wert können wir deutlich sehen, dass Entry eine grundlegende Bean für die Implementierung von HashMap-Schlüssel-Wert-Paaren ist. Wie wir oben erwähnt haben, ist die Basis von HashMap ein lineares Array. Dieses Array ist Entry[] und der Inhalt in der Map werden in Eintrag[] gespeichert
2. HashMap-ZugriffsimplementierungDa es sich um ein lineares Array handelt, warum kann HashMap hier verwendet werden? Grob wie folgt implementiert: 1) put
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;Frage: Wenn zwei Schlüssel den Index über hash%Entry[].length erhalten, ist das Gleiche, gibt es welche Gefahr des Überschreibens? Hier wird das Konzept der verketteten Datenstruktur in HashMap verwendet. Wir haben oben erwähnt, dass es in der Entry-Klasse ein next-Attribut gibt, das auf den nächsten Entry verweist. Wenn beispielsweise das erste Schlüssel-Wert-Paar A eintrifft, wird der durch die Berechnung des Hashs seines Schlüssels erhaltene Index=0 wie folgt aufgezeichnet: Eintrag[0] = A. Nach einer Weile kommt ein weiteres Schlüssel-Wert-Paar B und sein Index ist rechnerisch gleich 0. Was sollen wir jetzt tun? HashMap wird Folgendes tun:
B.next = A,Entry[0] = B. Wenn C erneut eintrifft, ist der Index ebenfalls gleich 0, dann
C.next = B// 存储时: int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value; // 取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
Das heißt, das zuletzt eingefügte Element wird im Array gespeichert. An diesem Punkt sollten wir ein klares Verständnis der allgemeinen Implementierung von HashMap haben.
Natürlich enthält HashMap auch einige Optimierungsimplementierungen, über die ich hier sprechen werde. Beispiel: Nachdem die Länge von Eintrag [] festgelegt wurde, wird die Kette desselben Index sehr lang, wenn die Daten in der Karte immer länger werden. Wird dies die Leistung beeinträchtigen? In HashMap wird ein Faktor festgelegt. Wenn die Größe der Karte immer größer wird, verlängert sich Entry[] nach bestimmten Regeln.2) get
3) Nullschlüsselzugriff public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}Nullschlüssel wird immer in Eintrag [] gespeichert Das erste Element des Arrays.
4) Bestimmen Sie den Array-Index: Hashcode % table.length modulo
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}Beim Zugriff auf HashMap müssen Sie berechnen, dass der aktuelle Schlüssel dem entsprechen sollte Eintrag[]-Array Welches Element wird zur Berechnung des Array-Index verwendet? Der Algorithmus lautet wie folgt:
Bitweise Vereinigung, was Modulo Mod oder Rest % entspricht. Dies bedeutet, dass die Array-Indizes gleich sind, aber es bedeutet nicht, dass der HashCode gleich ist. private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列) 再哈希法 链地址法 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}Das obige ist der detaillierte Inhalt vonVertiefendes Verständnis des Implementierungsprinzips von HashMap in Java (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



