


In diesem Artikel werden hauptsächlich die Baumstruktur und das DOM-Dokumentobjektmodell in XML vorgestellt. Der Artikel enthält Beispiele für das Parsen von DOM-Objekten in JavaScript >XML-Dokumente sind immer beschreibend. Baumstrukturen, oft auch XML-Bäume genannt, spielen eine wichtige Rolle bei der Beschreibung von XML-Dokumenten.
Diese Baumstruktur enthält das Stammelement (übergeordnetes Element), untergeordnete Elemente usw. Durch die Verwendung einer Baumstruktur können wir alle nachfolgenden Zweige und Unterzweige verstehen, die vom Wurzelelement ausgehen. Das Parsen beginnt beim Stammelement und geht dann nach unten zum ersten Zweig, der auf ein Element zeigt, von wo aus der erste Zweig und seine untergeordneten Elemente verarbeitet werden.
BeispielDas folgende Beispiel zeigt eine einfache XML-Baumstruktur:
Die folgende Baumstruktur stellt das obige XML-Dokument dar:
<?xml version="1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>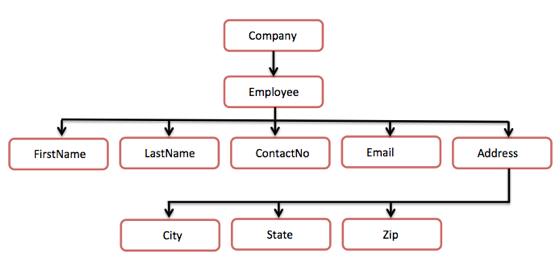 DOM Document Object Model
DOM Document Object Model
Das Document Object Model (DOM) ist die Basis von XML. XML-Dokumente verfügen über eine hierarchische Informationseinheit, die als Knoten bezeichnet wird. Das DOM ist eine Möglichkeit, diese Knoten und die Beziehungen zwischen ihnen zu beschreiben.
Ein DOM-Dokument ist eine Sammlung von Knoten oder Informationsblöcken, die in einer hierarchischen Struktur organisiert sind. Diese Hierarchie ermöglicht es Entwicklern, durch diesen Knotenbaum zu navigieren, um bestimmte Informationen abzufragen. Da das DOM auf einer Informationshierarchie basiert, gilt es auch als knotenbaumbasiert.
Andererseits bietet XML DOM auch eine API, die es Entwicklern ermöglicht, Knoten an einer beliebigen Stelle im Knotenbaum hinzuzufügen, zu bearbeiten, zu verschieben oder zu entfernen, um Anwendungen zu erstellen.
Das folgende Beispiel (sample.htm) analysiert ein XML-Dokument („address.xml“) in ein XML-DOM-Objekt und extrahiert dann einige Informationen mithilfe von JavaScript:
Der Inhalt von address.xml lautet wie folgt:
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id="name"></span><br>
<b>Company:</b> <span id="company"></span><br>
<b>Phone:</b> <span id="phone"></span>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc=xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body
</html>Wir können diese beiden Dateien sample.htm und address.xml im selben Verzeichnis speichern / xml und führen Sie dann die Datei „sample.htm“ aus, indem Sie sie im Browser öffnen. Es sollte ein Ergebnis wie dieses ergeben:
<?xml version="1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>
Das obige ist der detaillierte Inhalt vonBeispielcode für eine Baumstruktur und ein DOM-Dokumentobjektmodell in XML (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So konvertieren Sie PDF in das XML-Format
So konvertieren Sie PDF in das XML-Format
 Der Unterschied zwischen einem offiziellen Ersatztelefon und einem brandneuen Telefon
Der Unterschied zwischen einem offiziellen Ersatztelefon und einem brandneuen Telefon
 Was soll ich tun, wenn meine Windows-Lizenz bald abläuft?
Was soll ich tun, wenn meine Windows-Lizenz bald abläuft?
 Verwendung der Schreibfunktion
Verwendung der Schreibfunktion
 Was ist j2ee
Was ist j2ee
 Was soll ich tun, wenn eDonkey Search keine Verbindung zum Server herstellen kann?
Was soll ich tun, wenn eDonkey Search keine Verbindung zum Server herstellen kann?
 Methode zum Löschen von Hiberfil-Dateien
Methode zum Löschen von Hiberfil-Dateien
 Was bedeutet Element?
Was bedeutet Element?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



