


In diesem Artikel werden hauptsächlich relevante Informationen zu Java-E/A-Operationen und -Optimierung im Detail vorgestellt. Freunde, die sie benötigen, können sich auf die folgende
Zusammenfassung beziehen:
Stream ist Ein Satz aufeinanderfolgender Bytes mit einem Startpunkt und einem Endpunkt ist ein allgemeiner Begriff oder eine Abstraktion für die Datenübertragung. Das heißt, die Übertragung von Daten zwischen zwei Geräten wird als Stream bezeichnet. Das Wesentliche eines Streams ist die Datenübertragung. Der Stream wird entsprechend den Datenübertragungseigenschaften in verschiedene Kategorien unterteilt, um intuitivere Datenvorgänge zu ermöglichen.
Java I/O
I/O, die Abkürzung für Input/Output (Eingabe/Ausgabe). Was I/O betrifft, gibt es konzeptionell fünf Modelle: blockierende I/O, nicht blockierende I/O, I/O-Multiplexing (Auswahl und Abfrage), signalgesteuerte I/O (SIGIO), asynchrone I/O (die POSIX aio_functions). Verschiedene Betriebssysteme unterstützen die oben genannten Modelle unterschiedlich, und UNIX unterstützt IO-Multiplexing. Verschiedene Systeme haben unterschiedliche Namen. In FreeBSD heißt es kqueue und in Linux heißt es epoll. IOCP wurde in Windows 2000 geboren, um asynchrone E/A zu unterstützen.
Java ist eine plattformübergreifende Sprache. NIO1.0 wurde in Java 1.4 eingeführt und basiert auf der Wiederverwendung von E/A jede Plattform. Linux verwendet epoll, BSD verwendet kqueue und Windows verwendet überlappende E/A.
Die relevanten Methoden von Java I/O sind wie folgt:
Synchronisation und Blockierung (I/O-Methode): Der Server-Implementierungsmodus startet einen Thread für eine Verbindung , jedes Mal Ein Thread verarbeitet die E/A persönlich und wartet auf die E/A, bis sie abgeschlossen ist. Das heißt, wenn der Client eine Verbindungsanforderung hat, muss der Server einen Thread zur Verarbeitung starten. Wenn diese Verbindung jedoch nichts bewirkt, verursacht sie unnötigen Thread-Overhead. Dieser Mangel kann natürlich durch den Thread-Pool-Mechanismus behoben werden. Die Einschränkung von I/O besteht darin, dass es sich um einen stromorientierten, blockierenden und seriellen Prozess handelt. Für die Socket-Verbindungs-E/A jedes Clients ist ein Thread zur Verarbeitung erforderlich. Während dieser Zeit ist dieser Thread belegt, bis der Socket geschlossen wird. Während dieser Zeit sind TCP-Verbindungen, das Lesen von Daten und die Datenrückgabe blockiert. Mit anderen Worten: In diesem Zeitraum wurden viele CPU-Zeitscheiben und von Threads belegte Speicherressourcen verschwendet. Darüber hinaus wird jedes Mal, wenn eine Socket-Verbindung hergestellt wird, ein neuer Thread erstellt, der separat mit dem Socket kommuniziert (unter Verwendung blockierender Kommunikation). Diese Methode hat eine schnelle Reaktionsgeschwindigkeit und ist einfach zu steuern. Es ist sehr effektiv, wenn die Anzahl der Verbindungen gering ist, aber das Generieren eines Threads für jede Verbindung ist zweifellos eine Verschwendung von Systemressourcen. Wenn die Anzahl der Verbindungen groß ist, sind nicht genügend Ressourcen vorhanden Synchrones Nichtblockieren (NIO-Methode): Der Server-Implementierungsmodus startet einen Thread für eine Anfrage, und jeder Thread verarbeitet die E/A persönlich, aber andere Threads fragen ab, um zu prüfen, ob die E/A bereit ist, ohne auf die E/A zu warten. O bis zum Abschluss. Das heißt, die vom Client gesendeten Verbindungsanforderungen werden im Multiplexer registriert und der Multiplexer startet nur dann einen Thread zur Verarbeitung, wenn eine E/A-Anforderung für die Verbindung vorliegt. NIO ist pufferorientiert, nicht blockierend und selektorbasiert. Es verwendet einen Thread, um mehrere Datenübertragungskanäle abzufragen und zu überwachen, welcher Kanal verarbeitet werden kann . Der Server speichert eine Socket-Verbindungsliste und fragt diese Liste dann ab. Wenn festgestellt wird, dass an einem bestimmten Socket-Port Daten gelesen werden müssen, wird der entsprechende Lesevorgang der Socket-Verbindung aufgerufen Um auf einen bestimmten Socket-Port zu schreiben, wird der entsprechende Schreibvorgang der Socket-Verbindung aufgerufen. Wenn die Socket-Verbindung eines bestimmten Ports unterbrochen wurde, wird die entsprechende Destruktormethode aufgerufen, um den Port zu schließen. Dadurch können die Serverressourcen voll ausgenutzt und die Effizienz erheblich verbessert werden.
Asynchrone Nichtblockierung (AIO-Methode, JDK7-Version): Der Server-Implementierungsmodus startet einen Thread für eine gültige Anfrage und den I /O-Anforderung Das Betriebssystem schließt sie zuerst ab und benachrichtigt dann die Serveranwendung, den Thread zur Verarbeitung zu starten. Jeder Thread muss die E/A nicht persönlich verarbeiten, sondern delegiert sie an das Betriebssystem, und es besteht keine Notwendigkeit, zu warten bis die E/A abgeschlossen ist. Wenn der Vorgang abgeschlossen ist, werden Sie vom System später benachrichtigt. Dieser Modus verwendet das Epoll-Modell von Linux.
Wenn die Anzahl der Verbindungen gering ist, ist der herkömmliche E/A-Modus einfacher zu schreiben und einfacher zu verwenden. Da jedoch die Anzahl der Verbindungen weiter zunimmt, erfordert die herkömmliche E/A-Verarbeitung einen Thread für jede Verbindung. Wenn die Anzahl der Threads jedoch gering ist, steigt die Effizienz des Programms , Sie nimmt mit zunehmender Anzahl der Threads ab. Der Flaschenhals der herkömmlichen blockierenden E/A besteht also darin, dass sie nicht zu viele Verbindungen verarbeiten kann. Der Zweck der nicht blockierenden E/A besteht darin, diesen Engpass zu beheben. Es besteht kein Zusammenhang zwischen der Anzahl der Threads für nicht blockierende E/A-Verarbeitungsverbindungen und der Anzahl der Verbindungen. Wenn das System beispielsweise 10.000 Verbindungen verarbeitet, müssen nicht blockierende E/A nicht 10.000 Threads starten oder 2.000 Threads zur Verarbeitung. Da nicht blockierende E/A Verbindungen asynchron verarbeiten, behandelt der Server die Verbindungsanforderung als Anforderungs-„Ereignis“, wenn eine Verbindung eine Anforderung an den Server sendet, und weist dieses „Ereignis“ der entsprechenden Funktion zur Verarbeitung zu. Wir können diese Verarbeitungsfunktion zur Ausführung in einen Thread einfügen und den Thread nach der Ausführung zurückgeben, sodass ein Thread mehrere Ereignisse asynchron verarbeiten kann. Blockierende E/A-Threads verbringen die meiste Zeit damit, auf Anfragen zu warten.
Java NIO
Das Java.nio-Paket ist ein neues Paket, das nach Version 1.4 zu Java hinzugefügt wurde und speziell zur Verbesserung der Effizienz von E/A-Vorgängen verwendet wird.
Tabelle 1 zeigt den Vergleich zwischen I/O und NIO.
Tabelle 1. I/O VS NIO
| I/O | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞 IO | 非阻塞 IO |
| 无 | 选择器 |
NIO basiert auf Blöcken, die als Grundeinheit Daten in Blöcken verarbeiten. In NIO sind die beiden wichtigsten Komponenten Puffer und Kanal. Der Puffer ist ein kontinuierlicher Speicherblock und der Übertragungsort für NIO zum Lesen und Schreiben von Daten. Der Kanal identifiziert die Quelle oder das Ziel der gepufferten Daten. Er wird zum Lesen oder Schreiben von Daten in den Puffer verwendet und ist die Schnittstelle für den Zugriff auf den Puffer. Kanal ist ein bidirektionaler Kanal, der gelesen oder geschrieben werden kann. Stream ist unidirektional. Die Anwendung kann den Kanal nicht direkt lesen und schreiben, sondern muss dies über den Puffer tun, dh der Kanal liest und schreibt Daten über den Puffer.
Die Verwendung von Buffer zum Lesen und Schreiben von Daten erfolgt im Allgemeinen in den folgenden vier Schritten:
Daten in Buffer schreiben
Aufruf flip()-Methode;
liest Daten aus dem Puffer;
ruft die Methode „clear()“ oder „compact()“ auf.
Wenn Daten in den Puffer geschrieben werden, zeichnet der Puffer auf, wie viele Daten geschrieben werden. Sobald Sie Daten lesen möchten, müssen Sie den Puffer über die Methode flip() vom Schreibmodus in den Lesemodus umschalten. Im Lesemodus können alle zuvor in den Puffer geschriebenen Daten gelesen werden.
Sobald alle Daten gelesen wurden, muss der Puffer geleert werden, damit er erneut beschrieben werden kann. Es gibt zwei Möglichkeiten, den Puffer zu löschen: Aufruf der Methode clear() oder compact(). Die Methode clear() löscht den gesamten Puffer. Die Methode compact() löscht nur Daten, die bereits gelesen wurden. Alle ungelesenen Daten werden an den Anfang des Puffers verschoben und neu geschriebene Daten werden nach den ungelesenen Daten im Puffer platziert.
Es gibt viele Arten von Puffern, und verschiedene Puffer bieten unterschiedliche Möglichkeiten, die Daten im Puffer zu verarbeiten.
Abbildung 1 Pufferschnittstellen-Hierarchiediagramm
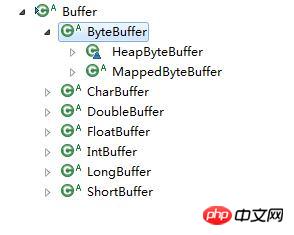
Es gibt zwei Situationen, in denen Buffer Daten schreibt:
Vom Kanal in den Puffer schreiben. Im Beispiel liest Channel Daten aus der Datei und schreibt sie in Channel.
ruft direkt die Put-Methode auf, um Daten hineinzuschreiben.
Es gibt zwei Möglichkeiten, Daten aus dem Puffer zu lesen:
Daten aus dem Puffer in den Kanal lesen;
Verwenden Sie die Methode get(), um Daten aus dem Puffer zu lesen.
Die Rewin-Methode von Buffer setzt die Position auf 0 zurück, sodass Sie alle Daten in Buffer erneut lesen können. Das Limit bleibt unverändert und gibt weiterhin an, wie viele Elemente (Byte, Zeichen usw.) aus dem Puffer gelesen werden können.
Methoden „clear()“ und „compact()“
Sobald die Daten im Puffer gelesen wurden, muss der Puffer zum erneuten Schreiben bereit sein. Dies kann über die Methoden „clear()“ oder „compact()“ erfolgen.
Wenn die Methode clear() aufgerufen wird, wird die Position auf 0 zurückgesetzt und das Limit auf den Wert der Kapazität gesetzt. Mit anderen Worten: Der Puffer wird gelöscht. Die Daten im Puffer werden nicht gelöscht, aber diese Markierungen sagen uns, wo wir mit dem Schreiben von Daten in den Puffer beginnen sollen.
Wenn sich im Puffer ungelesene Daten befinden und Sie die Methode clear() aufrufen, werden die Daten „vergessen“, was bedeutet, dass es keine Markierungen mehr gibt, die Ihnen sagen, welche Daten gelesen wurden und was nicht der Fall ist. Wenn sich noch ungelesene Daten im Puffer befinden und die Daten später benötigt werden, Sie aber zuerst einige Daten schreiben möchten, verwenden Sie die Methode compact(). Die Methode compact() kopiert alle ungelesenen Daten an den Anfang des Puffers. Stellen Sie dann die Position direkt nach dem letzten ungelesenen Element ein. Das Limit-Attribut ist weiterhin wie die Methode clear() auf Kapazität gesetzt. Jetzt ist der Puffer zum Schreiben von Daten bereit, ungelesene Daten werden jedoch nicht überschrieben.
Pufferparameter
Puffer hat drei wichtige Parameter: Position, Kapazität und Grenze.
Kapazität bezieht sich auf die Größe des Puffers, die bei der Erstellung des Puffers festgelegt wurde.
Limit Wenn sich der Puffer im Schreibmodus befindet, bezieht er sich darauf, wie viele Daten geschrieben werden können; im Lesemodus bezieht er sich darauf, wie viele Daten gelesen werden können.
Position Wenn sich der Puffer im Schreibmodus befindet, bezieht er sich auf die Position der nächsten zu schreibenden Daten; im Lesemodus bezieht er sich auf die Position der aktuell zu lesenden Daten. Jedes Mal, wenn ein Datenelement gelesen oder geschrieben wird, haben Position + 1, dh Grenzwert und Position, beim Lesen/Schreiben des Puffers unterschiedliche Bedeutungen. Wenn Sie die Flip-Methode von Buffer aufrufen und vom Schreibmodus in den Lesemodus wechseln, ist limit (read) = position (write), position (read) = 0.
Streuung und Aggregation
NIO bietet Methoden zur Verarbeitung strukturierter Daten, genannt Scattering und Gathering. Unter Streuung versteht man das Einlesen von Daten in eine Reihe von Puffern, nicht nur in einen. Bei der Aggregation hingegen werden Daten in einen Satz Puffer geschrieben. Die grundlegende Verwendung von Streuung und Aggregation ist der Verwendung beim Betrieb mit einem einzelnen Puffer ziemlich ähnlich. Bei einem Scatter-Read füllen die Kanäle nacheinander jeden Puffer. Sobald ein Puffer gefüllt ist, beginnt er, den nächsten zu füllen. In gewisser Weise ist das Puffer-Array wie ein großer Puffer. Wenn die spezifische Struktur der Datei bekannt ist, können mehrere Puffer erstellt werden, die der Dateistruktur entsprechen, sodass die Größe jedes Puffers genau der Größe jeder Segmentstruktur der Datei entspricht. Zu diesem Zeitpunkt kann der Inhalt durch Streulesen gleichzeitig in jedem entsprechenden Puffer zusammengestellt werden, wodurch der Vorgang vereinfacht wird. Wenn Sie eine Datei in einem bestimmten Format erstellen müssen, müssen Sie zunächst nur ein Pufferobjekt mit der entsprechenden Größe erstellen und dann die Aggregate-Write-Methode verwenden, um die Datei schnell zu erstellen. Listing 1 verwendet FileChannel als Beispiel, um zu zeigen, wie Streuung und Sammlung zum Lesen und Schreiben strukturierter Dateien verwendet werden.
Listing 1. Lesen und Schreiben strukturierter Dateien mithilfe von Streuung und Sammeln
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class NIOScatteringandGathering {
public void createFiles(String TPATH){
try {
ByteBuffer bookBuf = ByteBuffer.wrap("java 性能优化技巧".getBytes("utf-8"));
ByteBuffer autBuf = ByteBuffer.wrap("test".getBytes("utf-8"));
int booklen = bookBuf.limit();
int autlen = autBuf.limit();
ByteBuffer[] bufs = new ByteBuffer[]{bookBuf,autBuf};
File file = new File(TPATH);
if(!file.exists()){
try {
file.createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
try {
FileOutputStream fos = new FileOutputStream(file);
FileChannel fc = fos.getChannel();
fc.write(bufs);
fos.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
ByteBuffer b1 = ByteBuffer.allocate(booklen);
ByteBuffer b2 = ByteBuffer.allocate(autlen);
ByteBuffer[] bufs1 = new ByteBuffer[]{b1,b2};
File file1 = new File(TPATH);
try {
FileInputStream fis = new FileInputStream(file);
FileChannel fc = fis.getChannel();
fc.read(bufs1);
String bookname = new String(bufs1[0].array(),"utf-8");
String autname = new String(bufs1[1].array(),"utf-8");
System.out.println(bookname+" "+autname);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args){
NIOScatteringandGathering nio = new NIOScatteringandGathering();
nio.createFiles("C://1.TXT");
}
}Die Ausgabe ist in Listing 2 unten dargestellt .
Listing 2. Laufergebnisse
java 性能优化技巧 test
Der in Listing 3 gezeigte Code gilt für herkömmliche I/O- und Byte- Basierend auf NIO Die Leistung von drei auf Speicherzuordnung basierenden NIO-Methoden wurde verglichen, wobei die zeitaufwändigen Lese- und Schreibvorgänge einer Datei mit 4 Millionen Daten als Bewertungsbasis verwendet wurden.
Listing 3. Vergleichstest von drei I/O-Methoden
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class NIOComparator {
public void IOMethod(String TPATH){
long start = System.currentTimeMillis();
try {
DataOutputStream dos = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream(new File(TPATH))));
for(int i=0;i<4000000;i++){
dos.writeInt(i);//写入 4000000 个整数
}
if(dos!=null){
dos.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
try {
DataInputStream dis = new DataInputStream(
new BufferedInputStream(new FileInputStream(new File(TPATH))));
for(int i=0;i<4000000;i++){
dis.readInt();
}
if(dis!=null){
dis.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
public void ByteMethod(String TPATH){
long start = System.currentTimeMillis();
try {
FileOutputStream fout = new FileOutputStream(new File(TPATH));
FileChannel fc = fout.getChannel();//得到文件通道
ByteBuffer byteBuffer = ByteBuffer.allocate(4000000*4);//分配 Buffer
for(int i=0;i<4000000;i++){
byteBuffer.put(int2byte(i));//将整数转为数组
}
byteBuffer.flip();//准备写
fc.write(byteBuffer);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
FileInputStream fin;
try {
fin = new FileInputStream(new File(TPATH));
FileChannel fc = fin.getChannel();//取得文件通道
ByteBuffer byteBuffer = ByteBuffer.allocate(4000000*4);//分配 Buffer
fc.read(byteBuffer);//读取文件数据
fc.close();
byteBuffer.flip();//准备读取数据
while(byteBuffer.hasRemaining()){
byte2int(byteBuffer.get(),byteBuffer.get(),byteBuffer.get(),byteBuffer.get());//将 byte 转为整数
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
public void mapMethod(String TPATH){
long start = System.currentTimeMillis();
//将文件直接映射到内存的方法
try {
FileChannel fc = new RandomAccessFile(TPATH,"rw").getChannel();
IntBuffer ib = fc.map(FileChannel.MapMode.READ_WRITE, 0, 4000000*4).asIntBuffer();
for(int i=0;i<4000000;i++){
ib.put(i);
}
if(fc!=null){
fc.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
try {
FileChannel fc = new FileInputStream(TPATH).getChannel();
MappedByteBuffer lib = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());
lib.asIntBuffer();
while(lib.hasRemaining()){
lib.get();
}
if(fc!=null){
fc.close();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
public static byte[] int2byte(int res){
byte[] targets = new byte[4];
targets[3] = (byte)(res & 0xff);//最低位
targets[2] = (byte)((res>>8)&0xff);//次低位
targets[1] = (byte)((res>>16)&0xff);//次高位
targets[0] = (byte)((res>>>24));//最高位,无符号右移
return targets;
}
public static int byte2int(byte b1,byte b2,byte b3,byte b4){
return ((b1 & 0xff)<<24)|((b2 & 0xff)<<16)|((b3 & 0xff)<<8)|(b4 & 0xff);
}
public static void main(String[] args){
NIOComparator nio = new NIOComparator();
nio.IOMethod("c://1.txt");
nio.ByteMethod("c://2.txt");
nio.ByteMethod("c://3.txt");
}
}Die laufende Ausgabe von Listing 3 ist wie folgt siehe Listing 4 Show.
Listing 4. Ausgabe ausführen
1139 906 296 157 234 125
Zusätzlich zur obigen Beschreibung und dem in Listing 3 gezeigten Code, NIOs Buffer stellt außerdem eine Klasse DirectBuffer bereit, die direkt auf den physischen Speicher des Systems zugreifen kann. DirectBuffer erbt von ByteBuffer, unterscheidet sich jedoch vom gewöhnlichen ByteBuffer. Gewöhnlicher ByteBuffer weist weiterhin Speicherplatz auf dem JVM-Heap zu, und sein maximaler Speicher ist durch den maximalen Heap begrenzt, während DirectBuffer direkt dem physischen Speicher zugewiesen wird und keinen Heap-Speicherplatz belegt. Beim Zugriff auf einen normalen ByteBuffer verwendet das System für indirekte Operationen immer einen „Kernel-Puffer“. Der Speicherort von DirectrBuffer entspricht diesem „Kernel-Puffer“. Daher ist die Verwendung von DirectBuffer eine Methode, die näher am unteren Rand des Systems liegt und daher schneller als gewöhnlicher ByteBuffer ist. Im Vergleich zu ByteBuffer bietet DirectBuffer viel schnellere Lese- und Schreibzugriffsgeschwindigkeiten, aber die Kosten für die Erstellung und Zerstörung von DirectrBuffer sind höher als bei ByteBuffer. Code, der DirectBuffer mit ByteBuffer vergleicht, ist in Listing 5 dargestellt.
Listing 5. DirectBuffer VS ByteBuffer
import java.nio.ByteBuffer;
public class DirectBuffervsByteBuffer {
public void DirectBufferPerform(){
long start = System.currentTimeMillis();
ByteBuffer bb = ByteBuffer.allocateDirect(500);//分配 DirectBuffer
for(int i=0;i<100000;i++){
for(int j=0;j<99;j++){
bb.putInt(j);
}
bb.flip();
for(int j=0;j<99;j++){
bb.getInt(j);
}
}
bb.clear();
long end = System.currentTimeMillis();
System.out.println(end-start);
start = System.currentTimeMillis();
for(int i=0;i<20000;i++){
ByteBuffer b = ByteBuffer.allocateDirect(10000);//创建 DirectBuffer
}
end = System.currentTimeMillis();
System.out.println(end-start);
}
public void ByteBufferPerform(){
long start = System.currentTimeMillis();
ByteBuffer bb = ByteBuffer.allocate(500);//分配 DirectBuffer
for(int i=0;i<100000;i++){
for(int j=0;j<99;j++){
bb.putInt(j);
}
bb.flip();
for(int j=0;j<99;j++){
bb.getInt(j);
}
}
bb.clear();
long end = System.currentTimeMillis();
System.out.println(end-start);
start = System.currentTimeMillis();
for(int i=0;i<20000;i++){
ByteBuffer b = ByteBuffer.allocate(10000);//创建 ByteBuffer
}
end = System.currentTimeMillis();
System.out.println(end-start);
}
public static void main(String[] args){
DirectBuffervsByteBuffer db = new DirectBuffervsByteBuffer();
db.ByteBufferPerform();
db.DirectBufferPerform();
}
}Die laufende Ausgabe ist in Listing 6 dargestellt.
Listing 6. Ausgabe ausführen
920 110 531 390
Wie aus Listing 6 ersichtlich ist, sind die Kosten für häufiges Erstellen und Zerstören DirectBuffer ist weitaus größer als Allocate Speicherplatz auf dem Heap. Verwenden Sie die Parameter -XX:MaxDirectMemorySize=200M –Xmx200M, um den maximalen DirectBuffer und den maximalen Heap-Speicherplatz in VM-Argumenten zu konfigurieren. Wenn der festgelegte Heap-Speicherplatz zu klein ist, beispielsweise 1 MB, wird ein Fehler ausgegeben wie in Listing 7 gezeigt.
Listing 7. Ausführungsfehler
Error occurred during initialization of VM Too small initial heap for new size specified
DirectBuffer-Informationen werden nicht im GC gedruckt, da der GC nur aufzeichnet Speicherrückgewinnung von Heap-Speicherplatz. Es ist ersichtlich, dass das GC-Array relativ häufig ist, da ByteBuffer Speicherplatz auf dem Heap zuweist. In Situationen, in denen Buffer häufig erstellt werden muss, sollte DirectBuffer nicht verwendet werden, da der Code zum Erstellen und Zerstören von DirectBuffer relativ teuer ist. Wenn DirectBuffer jedoch wiederverwendet werden kann, kann die Systemleistung erheblich verbessert werden. Listing 8 ist ein Code zur Überwachung von DirectBuffer.
Listing 8. Das Ausführen des DirectBuffer-Überwachungscodes
import java.lang.reflect.Field;
public class monDirectBuffer {
public static void main(String[] args){
try {
Class c = Class.forName("java.nio.Bits");//通过反射取得私有数据
Field maxMemory = c.getDeclaredField("maxMemory");
maxMemory.setAccessible(true);
Field reservedMemory = c.getDeclaredField("reservedMemory");
reservedMemory.setAccessible(true);
synchronized(c){
Long maxMemoryValue = (Long)maxMemory.get(null);
Long reservedMemoryValue = (Long)reservedMemory.get(null);
System.out.println("maxMemoryValue="+maxMemoryValue);
System.out.println("reservedMemoryValue="+reservedMemoryValue);
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (NoSuchFieldException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}wird in Listing 9 gezeigt.
Listing 9. Ausgabe ausführen
maxMemoryValue=67108864 reservedMemoryValue=0
Da NIO schwierig zu verwenden ist, haben viele Unternehmen ihr eigenes JDK-Paket auf den Markt gebracht NIO-Frameworks wie Apaches Mina, JBosss Netty, Suns Grizzly usw. Diese Frameworks kapseln direkt das TCP- oder UDP-Protokoll der Transportschicht. Es ist keine zusätzliche Unterstützung durch den Webcontainer erforderlich Das heißt, der Webcontainer ist nicht begrenzt.
Java AIO
AIO-bezogene Klassen und Schnittstellen:
java.nio.channels.AsynchronousChannel:标记一个 Channel 支持异步 IO 操作; java.nio.channels.AsynchronousServerSocketChannel:ServerSocket 的 AIO 版本,创建 TCP 服务端,绑定地址,监听端口等; java.nio.channels.AsynchronousSocketChannel:面向流的异步 Socket Channel,表示一个连接; java.nio.channels.AsynchronousChannelGroup:异步 Channel 的分组管理,目的是为了资源共享。 一个 AsynchronousChannelGroup 绑定一个线程池,这个线程池执行两个任务:处理 IO 事件和派发 CompletionHandler。AsynchronousServerSocketChannel 创建的时候可以传入一个 AsynchronousChannelGroup,那么通过 AsynchronousServerSocketChannel 创建的 AsynchronousSocketChannel 将同属于一个组,共享资源; java.nio.channels.CompletionHandler:异步 IO 操作结果的回调接口,用于定义在 IO 操作完成后所作的回调工作。 AIO 的 API 允许两种方式来处理异步操作的结果:返回的 Future 模式或者注册 CompletionHandler,推荐用 CompletionHandler 的方式, 这些 handler 的调用是由 AsynchronousChannelGroup 的线程池派发的。这里线程池的大小是性能的关键因素。
Hier ist ein Programmbeispiel für eine kurze Einführung Werfen wir einen Blick darauf, wie AIO funktioniert.
Listing 10. Serverprogramm
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousServerSocketChannel;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
import java.util.concurrent.ExecutionException;
public class SimpleServer {
public SimpleServer(int port) throws IOException {
final AsynchronousServerSocketChannel listener =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(port));
//监听消息,收到后启动 Handle 处理模块
listener.accept(null, new CompletionHandler<AsynchronousSocketChannel, Void>() {
public void completed(AsynchronousSocketChannel ch, Void att) {
listener.accept(null, this);// 接受下一个连接
handle(ch);// 处理当前连接
}
@Override
public void failed(Throwable exc, Void attachment) {
// TODO Auto-generated method stub
}
});
}
public void handle(AsynchronousSocketChannel ch) {
ByteBuffer byteBuffer = ByteBuffer.allocate(32);//开一个 Buffer
try {
ch.read(byteBuffer).get();//读取输入
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
byteBuffer.flip();
System.out.println(byteBuffer.get());
// Do something
}
}Listing 11. Clientprogramm
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleClientClass {
private AsynchronousSocketChannel client;
public SimpleClientClass(String host, int port) throws IOException,
InterruptedException, ExecutionException {
this.client = AsynchronousSocketChannel.open();
Future<?> future = client.connect(new InetSocketAddress(host, port));
future.get();
}
public void write(byte b) {
ByteBuffer byteBuffer = ByteBuffer.allocate(32);
System.out.println("byteBuffer="+byteBuffer);
byteBuffer.put(b);//向 buffer 写入读取到的字符
byteBuffer.flip();
System.out.println("byteBuffer="+byteBuffer);
client.write(byteBuffer);
}
}Listing 12.Hauptfunktion
import java.io.IOException;
import java.util.concurrent.ExecutionException;
import org.junit.Test;
public class AIODemoTest {
@Test
public void testServer() throws IOException, InterruptedException {
SimpleServer server = new SimpleServer(9021);
Thread.sleep(10000);//由于是异步操作,所以睡眠一定时间,以免程序很快结束
}
@Test
public void testClient() throws IOException, InterruptedException, ExecutionException {
SimpleClientClass client = new SimpleClientClass("localhost", 9021);
client.write((byte) 11);
}
public static void main(String[] args){
AIODemoTest demoTest = new AIODemoTest();
try {
demoTest.testServer();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
demoTest.testClient();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Es wird später einen speziellen Artikel geben Detaillierte und ausführliche Einführung in den Quellcode, die Designkonzepte, Designmuster usw. von AIO.
Fazit
Ein wichtiger Unterschied zwischen I/O und NIO besteht darin, dass wir bei der Verwendung von I/O häufig Multithreading einführen. Jede Verbindung verwendet einen separaten Thread, während NIO einen einzelnen Thread oder nur eine kleine Anzahl von Multithreads verwendet . , jede Verbindung teilt sich einen Thread. Da die nicht blockierende Natur von NIO ständige Abfragen erfordert, die Systemressourcen verbrauchen, wurde der asynchrone nicht blockierende Modus AIO geboren. In diesem Artikel werden die drei Eingabe- und Ausgabebetriebsmodi wie I/O, NIO und AIO nacheinander vorgestellt und sollen den Lesern durch einfache Beschreibungen und Beispiele die Beherrschung grundlegender Vorgänge und Optimierungsmethoden ermöglichen.
Das Obige ist eine detaillierte Einführung in den Java-E/A-Betrieb und die Optimierung mit Bildern und Texten. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (m.sbmmt.com).
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



