


Eins. Vorwort
Wie implementieren wir normalerweise Paging?
SELECT * FROM table ORDER BY id LIMIT 1000, 10;
Aber was passiert, wenn die Datenmenge dramatisch zunimmt?
SELECT * FROM table ORDER BY id LIMIT 1000000, 10;
Die zweite Abfrage oben ist sehr langsam und wird zum Stillstand kommen.
Der kritischste Grund ist das Problem des MySQL-Abfragemechanismus:
Es geht nicht darum, zuerst zu überspringen und später abzufragen; >
Stattdessen zuerst abfragen und später überspringen. (Erklärung unten) Was bedeutet
? Beispiel: Begrenzen Sie 100.000,10. Wenn die ersten 100.000 Elemente gefunden werden, werden zunächst die Felddaten der ersten 100.000 Elemente abgerufen und dann verworfen, wenn sie sich als unbrauchbar erweisen Die benötigten 10 Artikel werden endlich gefunden.
Zwei. AnalyseLimit Offset,N, wenn der Offset sehr groß ist, ist die Effizienz extrem gering,
Der Grund ist, dass MySQL dies nicht tut Überspringe die versetzte Zeile, dann nimm einfach N Zeilen,
aber nimm Offset+N Zeilen, gib die versetzte Zeile zurück, bevor du aufgibst, und gib N Zeilen zurück [wie oben erwähnt, zuerst abfragen, dann überspringen ].
Der Wirkungsgrad ist geringer, wenn der Offset größer ist, ist der Wirkungsgrad geringer
1:Lösen Sie es aus geschäftlicher Sicht
Methode:Es ist nicht erlaubt, 100 Seiten umzublättern
Nehmen Sie Baidu als Beispiel , blättern Sie im Allgemeinen auf etwa 70 Seiten um .
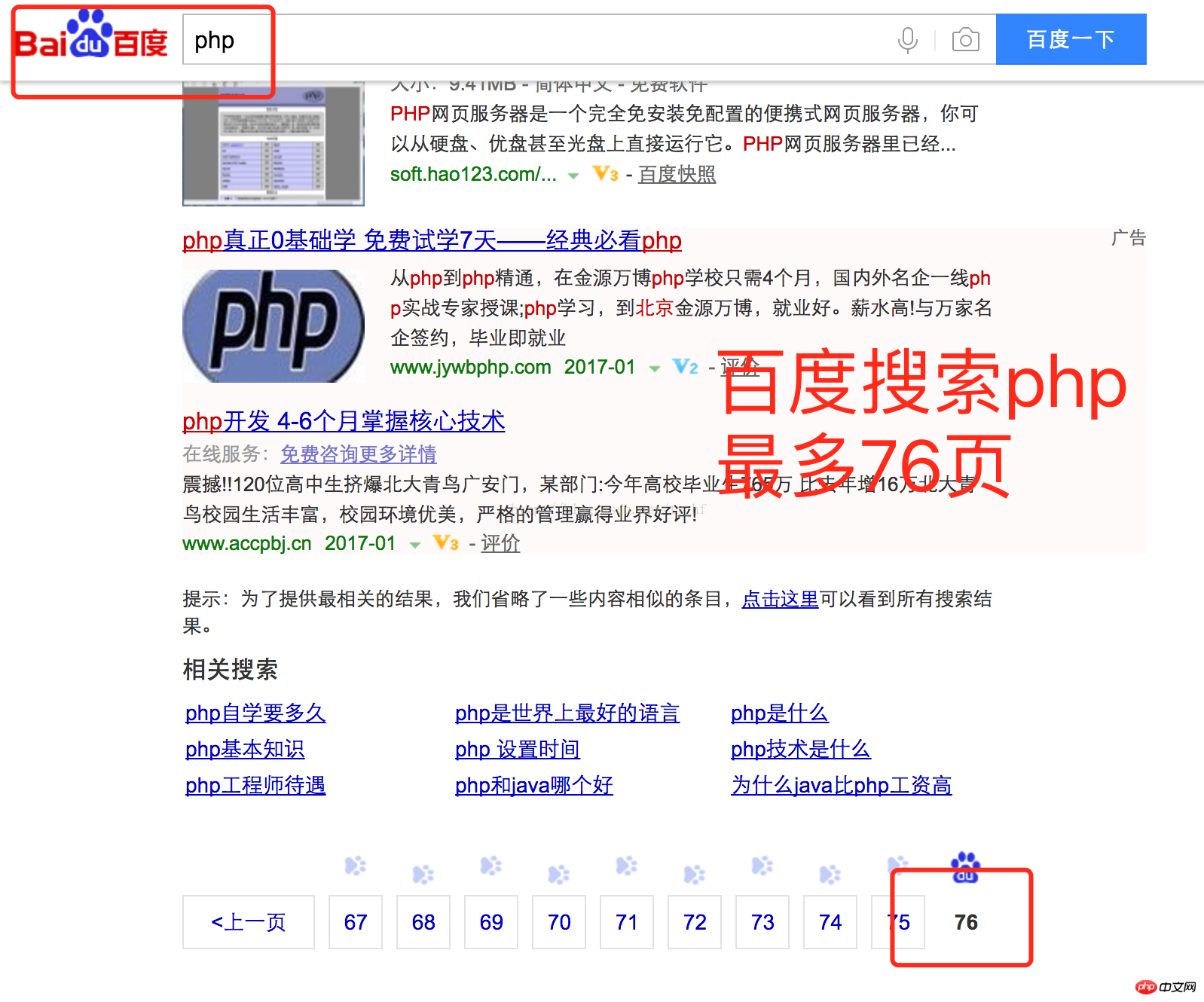
2:Keine NotwendigkeitOffset, Abfrage mit Bedingungen.
Beispiel :
Phänomene: Von 5,3 Sekunden auf weniger als 100 Millisekunden wird die Abfragegeschwindigkeit stark beschleunigt; die Datenergebnisse sind jedoch unterschiedlichmysql> select id, from lx_com limit 5000000,10; +---------+--------------------------------------------+ | id | name | +---------+--------------------------------------------+ | 5554609 |温泉县人民政府供暖中心 | .................. | 5554618 |温泉县邮政鸿盛公司 | +---------+--------------------------------------------+ 10 rows in set (5.33 sec) mysql> select id,name from lx_com where id>5000000 limit 10; +---------+--------------------------------------------------------+ | id | name | +---------+--------------------------------------------------------+ | 5000001 |南宁市嘉氏百货有限责任公司 | ................. | 5000002 |南宁市友达电线电缆有限公司 | +---------+--------------------------------------------------------+ 10 rows in set (0.00 sec)
Vorteile : Verwenden Sie die Where-Bedingung, um die erste -Abfrage zu vermeiden und dann die -Fragen zu überspringen. Stattdessen schränkt die -Bedingung den Bereich ein und überspringt direkt.
Es liegt ein Problem vor: Manchmal stellt sich heraus, dass die Ergebnisse der Verwendung dieser Methode und limitM, N, two inkonsistent sind [ wie im Beispiel oben gezeigt]
Ursache:Die Daten wurden physisch gelöscht,Es gibt Lücken.
Lösung:Daten werden nicht physisch gelöscht(können logisch gelöscht werden). 最终在页面上显示数据时,逻辑删除的条目不显示即可. (一般来说,大网站的数据都是不物理删除的,只做逻辑删除 ,比如 is_delete=1) 3:延迟索引. 非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办? 优化思路: 利用索引覆盖,快速查询出满足条件的主键id;然后凭借主键id作为where条件,达到快速查询。 (速度快在哪里?利用索引覆盖不需要回行就可以快速查询出满足条件的id,时间节约在这里了) 我们现在必须要查,则只查索引,不查数据,得到id.再用id去查具体条目. 这种技巧就是延迟索引. 慢原因: 查询100W条数据的id,name,m每次查询回行抛弃,跨过100W后取到真正要的数据。【就是我们刚刚说的,先查询,后跳过】 优化后快原理: a.利用索引覆盖先查询出主键id,在索引上就拿到信息了,避免回行 b.找到主键后,根据已知的目标主键在查询,避免跨大数据行去寻找,而是直接定位哪几条数据直接查询。 本方法即延迟索引查询。 四。总结: 从方案上来说,肯定是方法一优先,从业务上去满足是否要翻那么多页。 如果业务要求,则用id>n limit m的方式来代替limit n,m,但缺点是不能有物理删除 如果非有物理删除有空缺不能用方法二,则用延迟索引法,本质是利用索引覆盖先快速取出索引值,根据锁定的目标的索引值。一次性去回行取值,效果很明显。 以上就是Mysql优化-大数据量下的分页策略的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id);
+---------+-----------------------------------------------+
| id | name |
+---------+-----------------------------------------------+
| 5050425 | 陇县河北乡大谈湾小学 |
........
| 5050434 | 陇县堎底下镇水管站 |
+---------+-----------------------------------------------+
10 rows in set (1.35 sec)
Nach dem Login kopieren
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



