


Persistenz: Speichern Sie Daten auf einem ausgeschalteten Speichergerät zur späteren Verwendung. In den meisten Fällen, insbesondere bei Anwendungen auf Unternehmensebene, bedeutet Datenpersistenz, die Daten im Speicher auf der Festplatte zu speichern und zu „festigen“. Der Persistenzprozess wird meist über verschiedene relationale Datenbanken erreicht.
Die Hauptanwendung der Persistenz besteht darin, Daten im Speicher einer relationalen Datenbank zu speichern. Natürlich können sie auch in Festplattendateien und XML-Datendateien gespeichert werden.
In Java kann die Datenbankzugriffstechnologie in die folgenden Kategorien unterteilt werden:
JDBC greift direkt auf die Datenbank zu
JDO-Technologie
O/R-Tools von Drittanbietern wie Hibernate, ibatis usw.
JDBC Es ist der Grundstein für den Zugriff von Java auf Datenbanken. JDO, Hibernate usw. kapseln JDBC einfach besser.
JDBC (Java Database Connectivity) ist eine öffentliche Schnittstelle für den universellen SQL-Datenbankzugriff und -betrieb, die unabhängig von einem bestimmten Datenbankverwaltungssystem ist ( Eine Reihe von APIs, die Standard-Java-Klassenbibliotheken (java.sql, javax.sql) definieren, die für den Zugriff auf Datenbanken verwendet werden. Mit dieser Klassenbibliothek können Sie auf einfache Weise auf Datenbankressourcen zugreifen Der Ansatz verbirgt einige Details vor den Entwicklern.
Das Ziel von JDBC besteht darin, Java-Programmierern die Verwendung von JDBC zu ermöglichen, um eine Verbindung zu jedem Datenbanksystem herzustellen, das einen JDBC-Treiber bereitstellt, sodass Programmierer nicht zu viel Wissen über die Eigenschaften eines bestimmten haben müssen Datenbanksystem. Dies vereinfacht und beschleunigt den Entwicklungsprozess erheblich.
Die JDBC-Schnittstelle (API) umfasst zwei Ebenen:
Orientierte Anwendung API: Java-API, abstrakte Schnittstelle, die von Anwendungsentwicklern verwendet wird (Verbindung zur Datenbank herstellen, SQL-Anweisungen ausführen und Ergebnisse abrufen).
Datenbankorientierte API: Java-Treiber-API, damit Entwickler Datenbanktreiber entwickeln können.
JDBC ist eine Reihe von Schnittstellen, die von Sun für Datenbankoperationen bereitgestellt werden. Java-Programmierer müssen nur für diese Schnittstellen programmieren. Verschiedene Datenbankanbieter müssen unterschiedliche Implementierungen für diesen Schnittstellensatz bereitstellen. Eine Sammlung verschiedener Implementierungen sind Treiber für verschiedene Datenbanken. ——Schnittstellenorientierte Programmierung
JDBC-Treiber: Eine Klassenbibliothek von JDBC-Implementierungsklassen, die von verschiedenen Datenbankanbietern gemäß JDBC-Spezifikationen erstellt wurden
Es gibt insgesamt vier Arten von JDBC-Treibern:
Kategorie 1: JDBC-ODBC-Brücke.
Die zweite Kategorie: einige lokale APIs und einige Java-Treiber.
Die dritte Kategorie: JDBC-Netzwerk reiner Java-Treiber.
Kategorie 4: Reiner Java-Treiber für lokale Protokolle.
Die dritte und vierte Kategorie sind reine Java-Treiber und bieten daher für Java-Entwickler die besten Vorteile von Leistung und Funktion.
Der frühe Zugriff auf die Datenbank basierte auf dem Aufruf der proprietären API, die vom Datenbankanbieter bereitgestellt wurde. Um eine einheitliche Zugriffsmethode unter der Windows-Plattform bereitzustellen, hat Microsoft ODBC (Open Database Connectivity, offene Datenbankverbindung) eingeführt und eine ODBC-API bereitgestellt. Benutzer müssen nur die ODBC-API im Programm aufrufen, und der ODBC-Treiber konvertiert Es handelt sich um eine Aufrufanforderung an eine bestimmte Datenbank. Eine ODBC-basierte Anwendung ist für Datenbankoperationen nicht auf ein DBMS (Datenbankmanagersystem) angewiesen. Alle Datenbankoperationen werden vom ODBC-Treiber ausgeführt das entsprechende DBMS. Mit anderen Worten, ob es sich um FoxPro oder Access handelt
Auf , MYSQL- oder Oracle-Datenbanken kann über die ODBC-API zugegriffen werden. Es ist ersichtlich, dass der größte Vorteil von ODBC darin besteht, dass alle Datenbanken einheitlich verwaltet werden können.
JDBC-ODBC-Brücke
Die JDBC-ODBC-Brücke selbst ist auch ein Treiber. Mit diesem Treiber können Sie die JDBC-API verwenden Zugriff über die ODBC-Datenbank. Dieser Mechanismus wandelt tatsächlich Standard-JDBC-Aufrufe in entsprechende ODBC-Aufrufe um und greift über ODBC auf die Datenbank zu. Da hierfür mehrere Aufrufebenen erforderlich sind, ist die Verwendung der JDBC-ODBC-Brücke für den Zugriff auf die Datenbank ineffizient bereitgestellt. Die Implementierungsklasse der ODBC-Brücke (sun.jdbc.odbc.JdbcOdbcDriver).
Diese Art von JDBC-Treiber ist in Java geschrieben und ruft die vom Datenbankhersteller über diesen Typ bereitgestellte lokale API auf Der Zugriff des JDBC-Treibers auf die Datenbank reduziert die Anzahl der ODBC-Aufrufe und verbessert die Effizienz des Datenbankzugriffs. Auf diese Weise müssen ein lokaler JDBC-Treiber und die lokale API eines bestimmten Anbieters auf dem Computer des Kunden installiert werden.
Diese Art von Treiber verwendet den Middleware-Anwendungsserver, um auf die Datenbank zuzugreifen. Der Anwendungsserver fungiert als Gateway zu mehreren Datenbanken, über das Clients eine Verbindung zu verschiedenen Datenbankservern herstellen können.
Der Anwendungsserver verfügt normalerweise über ein eigenes Netzwerkprotokoll. Das Java-Benutzerprogramm sendet JDBC-Aufrufe an den Anwendungsserver. Der Anwendungsserver verwendet den lokalen Programmtreiber, um auf die Datenbank zuzugreifen Anfrage.
Die meisten Datenbankanbieter unterstützen bereits die direkte Kommunikation von Client-Programmen mit dem Netzwerkprotokoll für die Datenbankkommunikation.
Dieser Treibertyp ist vollständig in Java geschrieben. Durch die mit der Datenbank hergestellte Socket-Verbindung verwendet er das spezifische Netzwerkprotokoll des Herstellers, um JDBC-Aufrufe in direkt verbundene Netzwerkaufrufe an die JDBC-API umzuwandeln.
JDBC API ist eine Reihe von Schnittstellen, die es Anwendungen ermöglichen, eine Verbindung zu Datenbanken herzustellen, SQL-Anweisungen auszuführen und zurückgegebene Ergebnisse zu erhalten.
java.sql. Die Treiberschnittstelle ist die Schnittstelle, die alle JDBC-Treiber implementieren müssen. Diese Schnittstelle wird für Datenbankanbieter bereitgestellt. Es besteht keine Notwendigkeit, direkt auf die Klassen zuzugreifen, die die Treiberschnittstelle im Programm implementieren Durchführung.
Oracle-Treiber: oracle.jdbc.driver.OracleDriver
MySql-Treiber: com.mysql.jdbc.Driver
Methode 1: Um den JDBC-Treiber zu laden, müssen Sie die statische Methode forName() der Class-Klasse aufrufen und übergeben der zu ladende JDBC-Treiber
Class.forName(“com.mysql.jdbc.Driver“);
Methode 2: DriverManager-Klasse Ist die Treibermanagerklasse, die für die Verwaltung des Treibers verantwortlich ist
DriverManager.registerDriver(com.mysql.jdbc.Driver);
Normalerweise ist es nicht erforderlich, die Methode registerDriver() der Klasse DriverManager explizit aufzurufen, um eine Instanz der Treiberklasse zu registrieren, da alle Treiberklassen der Treiberschnittstelle statische Codeblöcke enthalten Im Codeblock wird die Methode DriverManager.registerDriver() aufgerufen, um eine Instanz von sich selbst zu registrieren.
Sie können die Methode getConnection() der Klasse DriverManager aufrufen, um eine Verbindung zur Datenbank herzustellen.
Benutzer und Passwort können der Datenbank mithilfe von „Attributname = Attributwert“ mitgeteilt werden.
JDBC-URL wird verwendet, um einen registrierten Treiber und Treibermanager zu identifizieren Über diese URL können Sie den richtigen Treiber aufrufen, um eine Verbindung zur Datenbank herzustellen.
Der JDBC-URL-Standard besteht aus drei Teilen, die durch Doppelpunkte getrennt sind.
jdbc: Unterprotokoll: Untername
Protokoll: Das Protokoll in der JDBC-URL ist immer jdbc.
Subprotokoll: Das Subprotokoll wird verwendet, um einen Datenbanktreiber zu identifizieren.
Subname: Eine Möglichkeit, die Datenbank zu identifizieren. Der Untername kann sich je nach Unterprotokoll ändern. Der Zweck der Verwendung des Unternamens besteht darin, ausreichende Informationen zum Auffinden der Datenbank bereitzustellen. Enthält den Hostnamen (entsprechend der IP-Adresse des Servers), die Portnummer und den Datenbanknamen.
jdbc:mysql://localhost:3306/test
Protokoll-Unterprotokoll-Untername
Verwenden Sie für die Oracle-Datenbankverbindung das folgende Formular:
jdbc:oracle:thin:@localhost:1521:atguigu
Für die SQLServer-Datenbankverbindung verwenden Sie das folgende Formular:
jdbc:microsoft:sqlserver//localhost:1433; DatabaseName=sid
Für die MYSQL-Datenbankverbindung , verwenden Sie das folgende Formular:
jdbc:mysql://localhost:3306/atguigu
Once the Verbindungsobjekt Verbindung wird abgerufen. Es ist noch nicht möglich, SQL auszuführen. Sie müssen die Ausführungsobjekt-Anweisung vom Verbindungsobjekt abrufen, um SQL auszuführen.
Connection connection = getConnection(); Statement state = connection.createStatement(); int n = state.executeUpdate(“insert,update,delete…”);
wobei n die Anzahl der Datensätze ist, die durch das Hinzufügen, Löschen oder Ändern der Tabelle betroffen sind. Wenn eine Abfrage ausgeführt wird, ein ResultSet Ergebnissatzobjekt wird zurückgegeben.
SQL-Injection ist die Verwendung bestimmter Systeme, die das nicht vollständig überprüfen Vom Benutzer eingegebene Daten. Fügen Sie illegale SQL-Anweisungssegmente oder Befehle in die Daten ein (z. B.: SELECT user, password FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1'), Dabei wird die SQL-Engine des Systems verwendet, um bösartiges Verhalten zu vervollständigen. Um SQL-Injection zu verhindern, verwenden Sie für Java einfach PreparedStatement (erweitert von Statement).
Ersetzen Sie einfach Statement .
Datentyp-Konvertierungstabelle
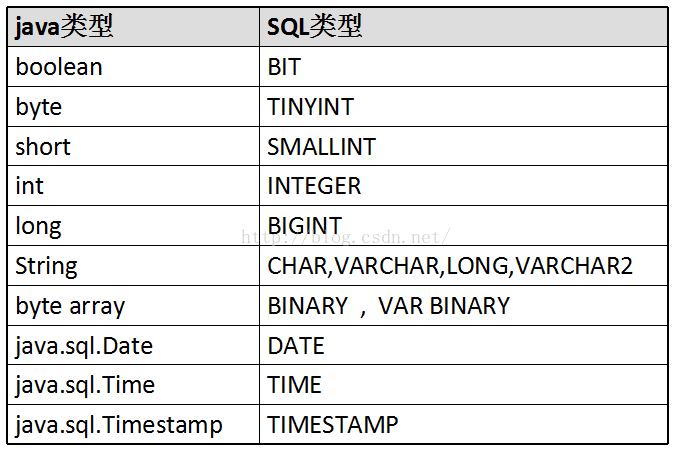
kann per Anruf abgerufen werden das Connection-Objekt Die Methode PreparedStatement() ruft das PreparedStatement-Objekt ab.
Die PreparedStatement-Schnittstelle ist eine Unterschnittstelle von Statement, die eine vorkompilierte SQL-Anweisung darstellt.
Die Parameter in der SQL-Anweisung, die durch das PreparedStatement-Objekt dargestellt werden, werden durch Fragezeichen (?) dargestellt. Rufen Sie die setXxx()-Methode des PreparedStatement-Objekts auf, um diese Parameter festzulegen Zwei Parameter, der erste Ein Parameter ist der Index (beginnend bei 1) des Parameters in der festzulegenden SQL-Anweisung und der zweite ist der Wert des Parameters in der festzulegenden SQL-Anweisung.
PreparedStatement vs Statement
Lesbarkeit und Wartbarkeit des Codes.
PreparedStatement kann die Leistung maximieren:
DBServer bietet Leistungsoptimierung für vorbereitete Anweisungen. Da vorkompilierte Anweisungen wiederholt aufgerufen werden können, wird der Ausführungscode der Anweisung nach der Kompilierung durch den DBServer-Compiler zwischengespeichert. Wenn die Anweisung dann das nächste Mal aufgerufen wird, muss sie nicht kompiliert werden, solange es sich um dieselbe vorkompilierte Anweisung handelt , solange die Parameter direkt übergeben werden, werden kompilierte Anweisungen im Ausführungscode ausgeführt.
In der Anweisungsanweisung kann die gesamte Anweisung selbst nicht übereinstimmen, selbst wenn es sich um denselben Vorgang handelt, der Dateninhalt jedoch unterschiedlich ist, und es hat keinen Sinn, die Anweisung zwischenzuspeichern. Tatsache ist, dass keine Datenbank den kompilierten Ausführungscode gewöhnlicher Anweisungen zwischenspeichert. Auf diese Weise muss die eingehende Anweisung bei jeder Ausführung einmal kompiliert werden. (Syntaxprüfung, Semantikprüfung, Übersetzung in Binärbefehle, Caching).
PreparedStatement kann SQL-Injection verhindern
Registrieren Sie den Treiber (nur einmal durchführen)
Stellen Sie eine Verbindung her (Verbindung)
Erstellen Sie eine Anweisung zum Ausführen von SQL (PreparedStatement)
Ausführungsanweisung
Ausführung verwalten Ergebnisse (ResultSet)
Ressourcen freigeben
Connection conn = null;
PreparedStatement st=null;
ResultSet rs = null;
try {
//获得Connection
//创建PreparedStatement
//处理查询结果ResultSet
}catch(Exception e){
e.printStackTrance();
} finally {
//释放资源ResultSet,
// PreparedStatement ,
//Connection
释放ResultSet, PreparedStatement ,Connection。
数据库连接(Connection)是非常稀有的资源,用完后必须马上释放,如果Connection不能及时正确的关闭将导致系统宕机。Connection的使用原则是尽量晚创建,尽量早的释放。
ORM:Object Relation Mapping
表 与 类 对应
表的一行数据 与 类的一个对象对应
表的一列 与类的一个属性对应
通过调用 PreparedStatement 对象的 excuteQuery() 方法创建该对象。
ResultSet 对象以逻辑表格的形式封装了执行数据库操作的结果集,ResultSet 接口由数据库厂商实现。
ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象的 next() 方法移动到下一行。
ResultSet 接口的常用方法:
boolean next()
getString()
…
处理执行结果(ResultSet)
读取(查询)对应SQL的SELECT,返回查询结果
st = conn.createStatement();
String sql = "select id, name, age,birth from user";
rs = st.executeQuery(sql);
while (rs.next()) {
System.out.print(rs.getInt("id") + " \t ");
System.out.print(rs.getString("name") + " \t");
System.out.print(rs.getInt("age") + " \t");
System.out.print(rs.getDate(“birth") + " \t ");
System.out.println();}
}
关于Result的说明
1. 查询需要调用 Statement 的 executeQuery(sql) 方法,查询结果是一个 ResultSet 对象
2. 关于 ResultSet:代表结果集
ResultSet: 结果集. 封装了使用 JDBC 进行查询的结果. 调用 Statement 对象的 executeQuery(sql) 可以得到结果集.
ResultSet 返回的实际上就是一张数据表. 有一个指针指向数据表的第一条记录的前面.
3.可以调用 next() 方法检测下一行是否有效. 若有效该方法返回 true, 且指针下移. 相当于Iterator 对象的 hasNext() 和 next() 方法的结合体
4.当指针指向一行时, 可以通过调用 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值.
例如: getInt(1), getString("name")
5.ResultSet 当然也需要进行关闭.
MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据。
MySQL的四种BLOB类型(除了在存储的最大信息量上不同外,他们是等同的)。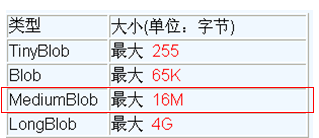
实际使用中根据需要存入的数据大小定义不同的BLOB类型。
需要注意的是:如果存储的文件过大,数据库的性能会下降。
可用于获取关于 ResultSet 对象中列的类型和属性信息的对象。
ResultSetMetaData meta = rs.getMetaData();
getColumnName(int column):获取指定列的名称
getColumnLabel(int column):获取指定列的别名
getColumnCount():返回当前 ResultSet 对象中的列数。
getColumnTypeName(int column):检索指定列的数据库特定的类型名称。
getColumnDisplaySize(int column):指示指定列的最大标准宽度,以字符为单位。
isNullable(int column):指示指定列中的值是否可以为 null。
isAutoIncrement(int column):指示是否自动为指定列进行编号,这样这些列仍然是只读的。
java.sql.DriverManager wird verwendet, um den Treiber zu laden und die Datenbankverbindung herzustellen.
java.sql.Connection stellt die Verbindung zu einer angegebenen Datenbank her.
java.sql.Statement dient als Container für SQL-Ausführungsanweisungen in einer bestimmten Verbindung. Es enthält zwei wichtige Untertypen.
Java.sql.PreparedSatement wird zum Ausführen vorkompilierter SQL-Anweisungen verwendet.
Java.sql.CallableStatement wird verwendet, um Aufrufe an gespeicherte Prozeduren in der Datenbank auszuführen.
java.sql.ResultSet ist die Möglichkeit, das Ergebnis für eine bestimmte Anweisung zu erhalten.
Zwei Gedanken
Die Idee der schnittstellenorientierten Programmierung;
ORM-Idee: SQL muss durch die Kombination von Spaltennamen und Tabellenattributnamen geschrieben werden und auf Aliase geachtet werden.
Zwei Technologien
JDBC-Metadaten: ResultSetMetaData;
PropertyUtils: Erstellen Sie ein Objekt über Class.newInstance() und fügen Sie den abgefragten Spaltenwert über diese Klasse zum erstellten Objekt zusammen.
Stapelverarbeitung von JDBC Anweisungen Verbessern Sie die Verarbeitungsgeschwindigkeit.
Wenn Sie Datensätze stapelweise einfügen oder aktualisieren müssen. Es kann der Stapelaktualisierungsmechanismus von Java verwendet werden, der es ermöglicht, mehrere Anweisungen gleichzeitig zur Stapelverarbeitung an die Datenbank zu senden. Dies ist normalerweise effizienter als die Verarbeitung einzelner Übermittlungen.
JDBC-Stapelverarbeitungsanweisungen umfassen die folgenden zwei Methoden:
addBatch(String): SQL hinzufügen Anweisungen oder Parameter, die eine Stapelverarbeitung erfordern;
executeBatch(): Stapelverarbeitungsanweisungen ausführen;
Normalerweise stoßen wir auf zwei Situationen der Stapelausführung von SQL-Anweisungen:
Stapelverarbeitung mehrerer SQL-Anweisungen;
Batch-Parameterübertragung einer SQL-Anweisung;
6-Datenbank-Verbindungspool
Bei der Entwicklung datenbankbasierter Webprogramme folgt das traditionelle Modell grundsätzlich den folgenden Schritten:
Stellen Sie eine Datenbankverbindung im Hauptprogramm her (z. B. Servlet, Beans)
Führen Sie SQL-Vorgänge aus
Trennen Sie die Datenbankverbindung
Probleme mit diesem Entwicklungsmodell:
Gewöhnliche JDBC-Datenbankverbindungen werden jedes Mal mit DriverManager hergestellt Wenn Sie eine Verbindung zur Datenbank herstellen, müssen Sie die Verbindung in den Speicher laden und dann den Benutzernamen und das Passwort überprüfen (dies dauert 0,05 bis 1 Sekunde). Wenn eine Datenbankverbindung erforderlich ist, fordern Sie eine von der Datenbank an und trennen Sie die Verbindung, nachdem die Ausführung abgeschlossen ist. Dieser Ansatz wird viele Ressourcen und Zeit in Anspruch nehmen. Die Datenbankverbindungsressourcen werden nicht gut wiederverwendet. Wenn Hunderte oder sogar Tausende von Personen gleichzeitig online sind, beanspruchen häufige Datenbankverbindungsvorgänge viele Systemressourcen und führen sogar zum Absturz des Servers. Jede Datenbankverbindung muss nach der Nutzung getrennt werden. Wenn das Programm andernfalls aufgrund einer Anomalie nicht geschlossen werden kann, führt dies zu einem Speicherverlust im Datenbanksystem und schließlich zu einem Neustart der Datenbank. Diese Art der Entwicklung kann die Anzahl der erstellten Verbindungsobjekte nicht steuern und Systemressourcen werden unberücksichtigt zugewiesen. Wenn zu viele Verbindungen vorhanden sind, kann dies auch zu Speicherverlusten und Serverabstürzen führen.
Datenbankverbindungspool (Verbindungspool)
Um Datenbankverbindungsprobleme in der traditionellen Entwicklung zu lösen, kann die Datenbankverbindungspooltechnologie verwendet werden.
Die Grundidee des Datenbankverbindungspools besteht darin, einen „Pufferpool“ für Datenbankverbindungen einzurichten. Legen Sie im Voraus eine bestimmte Anzahl von Verbindungen in den Pufferpool. Wenn Sie eine Datenbankverbindung herstellen müssen, müssen Sie nur eine aus dem „Pufferpool“ nehmen und nach der Verwendung wieder hinzufügen.
Der Datenbankverbindungspool ist für die Zuweisung, Verwaltung und Freigabe von Datenbankverbindungen verantwortlich. Er ermöglicht Anwendungen, eine vorhandene Datenbankverbindung wiederzuverwenden, anstatt eine neue herzustellen.
Der Datenbankverbindungspool erstellt eine bestimmte Anzahl von Datenbankverbindungen und fügt sie während der Initialisierung in den Verbindungspool ein. Die Anzahl dieser Datenbankverbindungen wird durch die Mindestanzahl von Datenbankverbindungen festgelegt. Unabhängig davon, ob diese Datenbankverbindungen verwendet werden oder nicht, ist immer gewährleistet, dass der Verbindungspool über mindestens so viele Verbindungen verfügt. Die maximale Anzahl von Datenbankverbindungen im Verbindungspool begrenzt die maximale Anzahl von Verbindungen, die der Verbindungspool belegen kann. Wenn die Anzahl der von der Anwendung aus dem Verbindungspool angeforderten Verbindungen die maximale Anzahl von Verbindungen überschreitet, werden diese Anforderungen dem hinzugefügt Warteschlange.
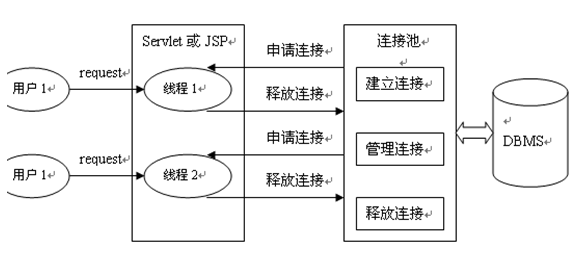
Ressourcenwiederverwendung
Da Datenbankverbindungen wiederverwendet werden können, entsteht durch häufiges Erstellen und Freigeben von Verbindungen ein großer Leistungsaufwand wird vermieden. Durch die Reduzierung des Systemverbrauchs wird andererseits auch die Stabilität der Systembetriebsumgebung erhöht.
Schnellere Systemreaktionsgeschwindigkeit
Während des Initialisierungsprozesses des Datenbankverbindungspools wurden häufig mehrere Datenbanken erstellt Die Verbindung wird zur späteren Verwendung im Verbindungspool abgelegt. Zu diesem Zeitpunkt ist die Initialisierungsarbeit der Verbindung abgeschlossen. Für die Verarbeitung von Geschäftsanfragen werden vorhandene verfügbare Verbindungen direkt verwendet, um den Zeitaufwand für die Initialisierung und Freigabe der Datenbankverbindung zu vermeiden und so die Reaktionszeit des Systems zu verkürzen.
Neue Methode zur Ressourcenzuweisung
Für Systeme, in denen mehrere Anwendungen dieselbe Datenbank gemeinsam nutzen, können Sie dies durch die Konfiguration von tun Im Datenbankverbindungspool ist die maximale Anzahl verfügbarer Datenbankverbindungen für eine bestimmte Anwendung begrenzt, um zu verhindern, dass eine bestimmte Anwendung alle Datenbankressourcen monopolisiert.
Einheitliche Verbindungsverwaltung zur Vermeidung von Datenbankverbindungslecks
In einer relativ vollständigen Implementierung des Datenbankverbindungspools können Sie entsprechend Aufgrund der Zeitüberschreitungseinstellung vor der Belegung wird die belegte Verbindung zwangsweise recycelt, wodurch ein Ressourcenverlust vermieden wird, der bei regulären Datenbankverbindungsvorgängen auftreten kann.
Zwei Open-Source-Datenbankverbindungspools:
Der Datenbankverbindungspool von JDBC wird durch javax.sql.DataSource dargestellt. DataSource ist lediglich eine Schnittstelle, die normalerweise von verwendet wird Server. (Weblogic, WebSphere, Tomcat) bietet Implementierung, und einige Open-Source-Organisationen
bieten Implementierung:
DBCP-Datenbankverbindungspool
C3P0-Datenbankverbindungspool
DataSource wird normalerweise als Datenquelle bezeichnet. Es besteht aus zwei Teilen: Verbindungspool und Verbindungspoolverwaltung. Es ist üblich, DataSource als Verbindungspool zu bezeichnen.
DataSource wird verwendet, um DriverManager zu ersetzen, um eine Verbindung zu erhalten, die schnell ist und die Datenbankzugriffsgeschwindigkeit erheblich verbessern kann.
DBCP-Datenquelle
DBCP ist eine Open-Source-Verbindungspool-Implementierung unter der Apache Software Foundation. Der Verbindungspool basiert auf einem anderen Open-Source-System unter der Organisation: Common- pool . Wenn Sie diese Verbindungspool-Implementierung verwenden möchten, sollten Sie die folgenden zwei JAR-Dateien zum System hinzufügen:
Commons-dbcp.jar: Verbindungspool Implementierung
Commons-pool.jar: Abhängigkeitsbibliothek für die Implementierung des Verbindungspools
Der Verbindungspool von Tomcat wird mithilfe dieses Verbindungspools implementiert. Der Datenbankverbindungspool kann in den Anwendungsserver integriert oder unabhängig von der Anwendung verwendet werden.
Beispiel für die Verwendung von DBCP-Datenquellen
Datenquellen unterscheiden sich von Datenbankverbindungen. Es ist nicht erforderlich, mehrere Datenquellen zu erstellen. Es handelt sich um eine Fabrik, die Datenbankverbindungen generiert. Daher benötigt die gesamte Anwendung nur eine einzige Datenquelle.
Wenn der Datenbankzugriff endet, schließt das Programm weiterhin die Datenbankverbindung wie zuvor: conn.close(); Der obige Code schließt jedoch nicht die physische Verbindung der Datenbank, sondern gibt sie nur frei und kehrt zurück Die Datenbankverbindung Es wird ein Datenbankverbindungspool angegeben.
Transaktion: eine Reihe logischer Operationseinheiten, die Daten von einem Zustand in einen anderen umwandeln.
Transaktionsverarbeitung (Transaktionsvorgang): Stellen Sie sicher, dass alle Transaktionen als Arbeitseinheit ausgeführt werden. Auch wenn ein Fehler auftritt, kann diese Ausführungsmethode nicht geändert werden. Wenn in einer Transaktion mehrere Vorgänge ausgeführt werden, werden entweder alle Transaktionen festgeschrieben und die Änderungen dauerhaft gespeichert, oder das Datenbankverwaltungssystem verwirft alle Änderungen und die gesamte Transaktion wird auf den ursprünglichen Zustand zurückgesetzt.
Um die Konsistenz der Daten in der Datenbank sicherzustellen, sollte die Datenmanipulation aus diskreten Gruppen logischer Einheiten bestehen: Wenn alles abgeschlossen ist, kann die Konsistenz der Daten aufrechterhalten werden, und wenn der If-Teil von Der Vorgang schlägt fehl, die gesamte Transaktion sollte als Fehler betrachtet werden und alle Vorgänge vom Startpunkt aus sollten auf den Startzustand zurückgesetzt werden.
ACID (Säure)-Attribut der Transaktion
1. Atomarität
Atomizität bedeutet, dass eine Transaktion eine unteilbare Arbeitseinheit ist und alle Vorgänge in einer Transaktion stattfinden oder nicht.
2. Konsistenz
Eine Transaktion muss die Datenbank von einem Konsistenzzustand in einen anderen ändern.
3. Isolation
Die Isolation einer Transaktion bedeutet, dass die Ausführung einer Transaktion nicht durch andere Transaktionen, also die Vorgänge und Nutzungen innerhalb einer, beeinträchtigt werden kann Transaktion Die Daten sind von anderen gleichzeitigen Transaktionen isoliert und gleichzeitig ausgeführte Transaktionen können sich nicht gegenseitig stören.
4. Haltbarkeit
Dauerhaftigkeit bedeutet, dass nach der Übermittlung einer Transaktion die Änderungen an den Daten in der Datenbank dauerhaft sind keinen Einfluss darauf haben
JDBC-Transaktionsverarbeitung
Wenn ein Verbindungsobjekt erstellt wird, wird die Transaktion ausgeführt wird standardmäßig automatisch festgeschrieben: Jedes Mal, wenn eine SQL-Anweisung ausgeführt wird und die Ausführung erfolgreich ist, wird sie automatisch an die Datenbank übermittelt und kann nicht zurückgesetzt werden.
Um mehrere SQL-Anweisungen als eine Transaktion auszuführen:
Rufen Sie setAutoCommit(false) des Connection-Objekts auf ; Um die automatische Festschreibungstransaktion abzubrechen
Nachdem alle SQL-Anweisungen erfolgreich ausgeführt wurden, rufen Sie die Methode commit(); auf, um die Transaktion festzuschreiben
Wenn eine Ausnahme auftritt, rufen Sie die Methode rollback(); auf, um die Transaktion zurückzusetzen
Wenn die Verbindung zu diesem Zeitpunkt nicht geschlossen ist, müssen Sie ihren automatischen Übermittlungsstatus wiederherstellen
Datenstatus nach Übermittlung
Die Datenänderungen wurden in der Datenbank gespeichert.
Die Daten vor der Änderung sind verloren gegangen.
Alle Benutzer können die Ergebnisse sehen.
Die Sperre wird aufgehoben und andere Benutzer können die betroffenen Daten bearbeiten.
Eine Sammlung häufig verwendeter JDBC-Klassen und -Methoden zum Betreiben von Datenbanken Zusammen sind es DBUtils.
BeanHandler: Konvertieren Sie die Ergebnismenge in eine JavaBean
BeanBeanListHandler: Konvertieren Sie das Ergebnis set In eine Sammlung von Beans konvertieren
MapHandler: Konvertiert die Ergebnismenge in eine Map
MapMapListHandler: Konvertiert die Ergebnismenge in eine Liste von Maps
ScalarHandler: Konvertiert das Ergebnis auf eine Karte setzen Gibt einen Datentyp zurück, der sich normalerweise auf String oder andere 8 grundlegende Datentypen bezieht
Das Obige ist die JDBC-Datenbank Managementsystem-Inhalt. Weitere verwandte Inhalte finden Sie auf der chinesischen PHP-Website (m.sbmmt.com)!
 Datenbank drei Paradigmen
Datenbank drei Paradigmen
 So löschen Sie eine Datenbank
So löschen Sie eine Datenbank
 So stellen Sie eine Verbindung zur Datenbank in VB her
So stellen Sie eine Verbindung zur Datenbank in VB her
 MySQL-Datenbank wiederherstellen
MySQL-Datenbank wiederherstellen
 So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
 So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
 So verbinden Sie VB mit dem Zugriff auf die Datenbank
So verbinden Sie VB mit dem Zugriff auf die Datenbank
 So stellen Sie mit vb eine Verbindung zur Datenbank her
So stellen Sie mit vb eine Verbindung zur Datenbank her








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



