

 System-Tutorial
Windows-Serie
Echtzeit-Computing-Framework, das durch Zeit und Raum reisen kann-Flink-Verarbeitung von Zeit
System-Tutorial
Windows-Serie
Echtzeit-Computing-Framework, das durch Zeit und Raum reisen kann-Flink-Verarbeitung von Zeit
Echtzeit-Computing-Framework, das durch Zeit und Raum reisen kann-Flink-Verarbeitung von Zeit

Im Streaming-die Zukunft der Big Data wissen wir, dass die beiden wichtigsten Dinge für die Streaming-Verarbeitung und Zeitpunkte für Zeitgelände sind. Flink hat sehr gute Unterstützung für beide.
Flink garantiert die KorrektheitFür kontinuierliche Ereignis -Streaming -Daten, da es möglicherweise noch Ereignisse gibt, die noch nicht eingetroffen sind, kann die Richtigkeit der Daten betroffen sein. Die übliche Praxis der Verwendung von Offline-Computing mit hoher Latenz ist jetzt garantiert, opfert aber auch eine geringe Latenz.
Die Richtigkeit des Flinkes spiegelt sich in der Definition des Berechnungsfensters im Einklang mit den Naturgesetzen der Datenerzeugung wider. Klicken Sie beispielsweise auf Stream -Ereignis auf den Zugriffsstatus von 3 Benutzern A, B und C auf Stream -Ereignis nach, dass die Daten, das das Sitzungsfenster ist, möglicherweise Lücken gibt.
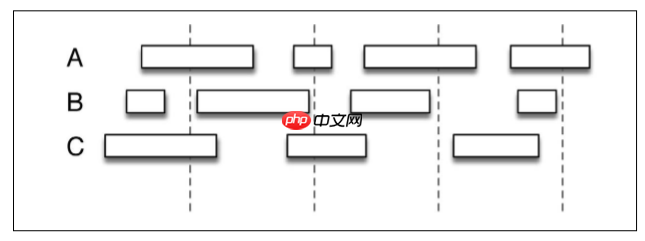
Mit der Mikrobatch -Methode von SparksTreaming (gestrichelte Linien sind Berechnungsfenster und durchgezogene Linien sind Sitzungsfenster) ist es schwierig, die Berechnungsfenster und die Sitzungsfenster zu entsprechen. Mit Flink's Stream Processing -API können Sie das Berechnungsfenster flexibel definieren. Beispielsweise können Sie einen Wert festlegen, wenn er diesen Wert überschreitet, wird die Aktivität als vorbei angesehen.
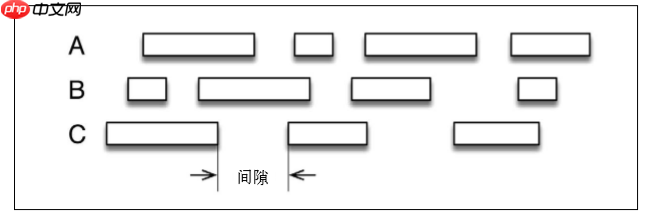
Im Gegensatz zur allgemeinen Stream -Verarbeitung kann Flink die Ereigniszeit übernehmen, was für die Korrektheit sehr nützlich ist.
Für die Richtigkeit des Versagens muss der Berechnungszustand nachverfolgt werden. In den meisten Fällen wird die staatliche Garantie von Entwicklern abgeschlossen, aber kontinuierliche Berechnungen der Strömungsverarbeitung haben kein Ende. Flink verwendet Checkpoint-Checkpoint-Technologie, um dieses Problem zu lösen. An jedem Checkpoint zeichnet das System den Zwischenberechnungsstatus auf, der beim Auftreten eines Fehlers genau zurückgesetzt wird. Diese Methode ermöglicht es dem System, eine Fehlertoleranz auf geringe Overhead -Weise zu haben. Wenn alles normal ist, hat der Checkpoint -Mechanismus einen sehr geringen Einfluss auf das System.
Die von Flink bereitgestellte Schnittstelle umfasst die Verfolgung von Computing -Aufgaben und die Verwendung der gleichen Technologie zur Implementierung von Arbeitenverarbeitung und Stapelverarbeitung, Vereinfachung der Betriebs- und Wartungsentwicklungsarbeiten, was auch eine Garantie für die Korrektheit ist.
Flinks ZeitverarbeitungDer größte Unterschied zwischen der Verwendung von Stream -Verarbeitung und Stapelverarbeitung ist die Zeitverarbeitung.
Verwenden der StapelverarbeitungsarchitekturIn dieser Architektur können wir Daten von Zeit zu Zeit in HDFs speichern und sie regelmäßig vom Scheduler ausführen, um die Ergebnisse auszugeben.
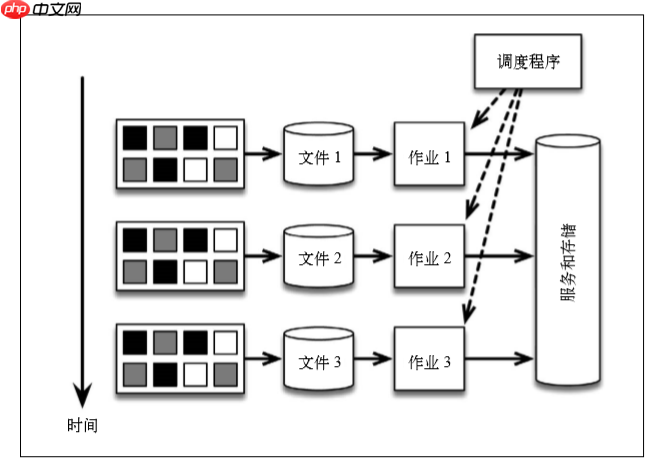
Diese Architektur ist machbar, aber es gibt mehrere Probleme:
Zu viele getrennte Teile. Um die Anzahl der Ereignisse in den Daten zu berechnen, verwendet diese Architektur zu viele Systeme. Jedes System verfügt über Lernkosten und Managementkosten, und es kann Fehler geben. Die Methode der Handhabungszeit ist unklar. Angenommen, es muss stattdessen alle 30 Minuten gezählt werden. Diese Änderung umfasst Workflow -Planungslogik (anstelle von Anwendungscode -Logik) und verwirrt DevOps -Probleme mit den Geschäftsanforderungen. Vorwarnung. Nehmen wir an, dass Sie zusätzlich zur Zählung einmal pro Stunde so früh wie möglich eine Zählwarnung erhalten müssen (z. B. wenn die Anzahl der Ereignisse 10 überschreitet). Zu diesem Zweck kann Storm eingeführt werden, um Meldungsströme zu sammeln, zusätzlich zu regelmäßigen Ausführung von Stapeljobs. Storm liefert ungefähre Zählungen in Echtzeit, und Stapeljobs bieten genaue Zählungen pro Stunde. Auf diese Weise wird der Architektur ein System hinzugefügt, und ein neues Programmiermodell, das sich darauf bezieht. Die obige Architektur wird als Lambda -Architektur bezeichnet.
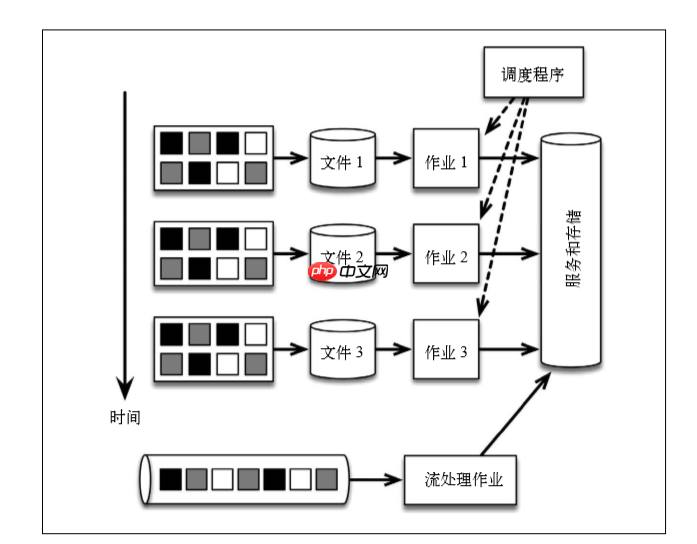
Zunächst wird die Nachricht zentral an das Nachrichtenübertragungssystem Kafka geschrieben, der Ereignisstrom wird vom Nachrichtenübertragungssystem bereitgestellt und nur von einem einzelnen Flink -Job verarbeitet.
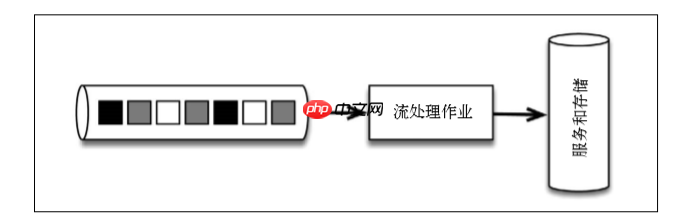
Teilen Sie den Ereignisstrom in Zeiteinheiten in Zeiten in die Aufgaben auf, und diese Logik ist vollständig in die Anwendungslogik des Flink -Programms eingebettet. Die Warnung wird durch dasselbe Programm erzeugt, und außergewöhnliche Ereignisse werden von Flink selbst übernommen. Um von der Gruppierung mit fester Zeit bis zu Gruppierung nach dem Zeitraum zu wechseln, in dem die Daten generiert werden, ändern Sie einfach die Definition des Fensters im Flink -Programm. Wenn der Code der Anwendung geändert wurde, können Sie die Anwendung wiederholen, indem Sie einfach das Kafka -Thema wiederholen. Die Verwendung einer Streaming -Architektur kann Systeme erheblich reduzieren, die Code lernen, verwalten und schreiben müssen. Beispiel für Flink -Anwendungscode:
Codesprache: JavaScript Anzahl der Codeläufe: 0 laufen Kopie <code class="javascript">DataStream<LogEvent> stream = env // 通过Kafka生成数据流.addSource(new FlinkKafkaConsumer(...)) // 分组.keyBy("country") // 将时间窗口设为60分钟.timeWindow(Time.minutes(60)) // 针对每个时间窗口进行操作.apply(new CountPerWindowFunction());</code>In der Stream -Verarbeitung gibt es zwei Hauptkonzepte der Zeit:
Ereigniszeit, dh die Zeit, in der das Ereignis tatsächlich auftritt. Genauer gesagt hat jedes Ereignis einen Zeitstempel, und der Zeitstempel ist Teil des Datensatzes.
Verarbeitungszeit, dh die Zeit, in der das Ereignis verarbeitet wird. Die Verarbeitungszeit ist tatsächlich die Zeit, die von der Maschine gemessen wird, die Ereignisse übernimmt.
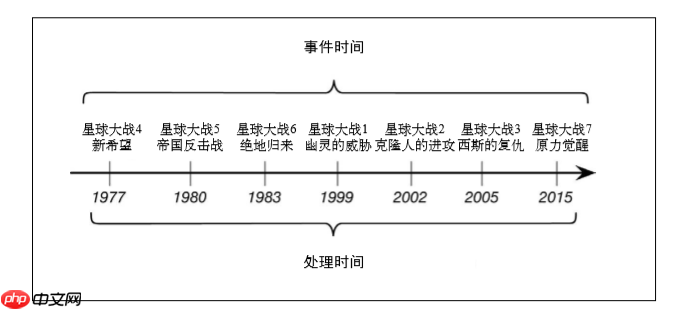
Nehmen Sie die Star Wars -Serie als Beispiel. Die ersten 3 veröffentlichten Filme sind die 4., 5. und 6. in der Serie (dies ist die Zeit des Events), und ihre Veröffentlichungsjahre sind 1977, 1980 und 1983 (dies ist die Zeit des Prozesses). Die von der Veranstaltungszeit veröffentlichte 1., 2., 3. und 7. Serie waren dann die entsprechenden Verarbeitungszeiten 1999, 2002, 2005 bzw. 2015. Es ist ersichtlich, dass die Reihenfolge des Ereignisflusses chaotisch sein kann (obwohl die Reihenfolge der Jahre im Allgemeinen nicht unordentlich ist)
In der Regel gibt es das dritte Zeitkonzept, nämlich die Ansaugzeit, auch als Einstiegszeit bezeichnet. Es bezieht sich auf die Zeit, in der ein Ereignis in das Stream -Verarbeitungs -Framework eintritt. Daten, denen der Zeitpunkt des realen Ereignisses fehlt, werden vom Stream -Prozessor ein Zeitstempel, dh wenn der Stream -Prozessor es zum ersten Mal sieht (dieser Vorgang erfolgt durch die Quellfunktion, die der erste Verarbeitungspunkt des Programms ist).
In der realen Welt verursachen viele Faktoren (z. B. vorübergehende Verbindungsunterbrechung, Netzwerkverzögerung, die durch unterschiedliche Gründe verursacht werden, die Synchronisation in verteilten Systemen, eine starke Erhöhung der Datenraten, physischen Gründe oder ein Pech) die Ereigniszeit und die Verarbeitungszeit voreingenommen (d. H. Ereigniszeitabweichung). Ereignischronologische Ordnung und Verarbeitung chronologischer Reihenfolge sind häufig inkonsistent, was bedeutet, dass Ereignisse nicht in Ordnung zum Stream -Prozessor kommen.
Mit Flink können Benutzer die Ereigniszeit, die Verarbeitungszeit oder die Aufnahmezeitdefinitionsfenster anhand der erforderlichen Semantik und Anforderungen an die Genauigkeit annehmen.
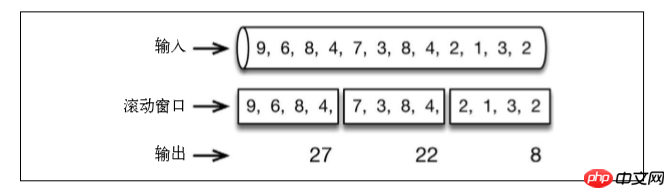
FensterDas Zeitfenster ist das einfachste und nützlichste. Es unterstützt Scrollen und Gleiten.
Beispielsweise sammelt ein einminütiges Scroll-Fenster die Werte der letzten Minute und gibt die Summe am Ende einer Minute aus:
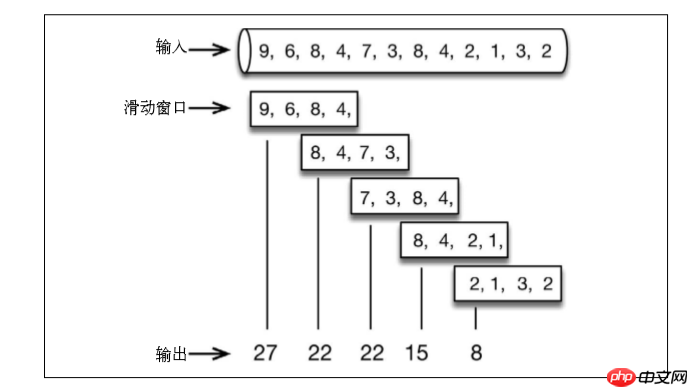
Das einminütige Gleitfenster berechnet die Summe der Werte der letzten Minute, gleitet jedoch jede halbe Minute und gibt das Ergebnis aus:
Im Flink wird das einminütige Scroll-Fenster wie folgt definiert.
Codesprache: JavaScript Anzahl der Codeläufe: 0 laufen Kopie<code class="javascript">stream.timeWindow(Time.minutes(1))</code>
Das einminütige Gleitfenster, das jede halbe Minute (d. H. 30 Sekunden) gleitet, ist unten gezeigt.
Codesprache: JavaScript Anzahl der Codeläufe: 0 laufen Kopie<code class="javascript">stream.timeWindow(Time.minutes(1), Time.seconds(30))</code>
Ein weiteres gemeinsames Fenster, das von Flink unterstützt wird, wird als Zählfenster bezeichnet. Bei Verwendung eines Zählfensters ist die Gruppierung kein Zeitstempel mehr, sondern die Anzahl der Elemente.
Ein Gleitfenster kann auch als Zählfenster interpretiert werden, das aus 4 Elementen und Rutschen einmal alle zwei Elemente besteht. Die Scrollen- und Schieberzählfenster werden wie folgt definiert.
Codesprache: JavaScript Anzahl der Codeläufe: 0 laufen Kopie<code class="javascript">stream.countWindow(4) stream.countWindow(4, 2)</code>
Obwohl das Zählfenster nützlich ist, ist seine Definition nicht so streng wie das Zeitfenster, daher sollte es mit Vorsicht verwendet werden. Die Zeit stoppt nicht und das Zeitfenster wird immer "geschlossen". Aber was das Zählen von Fenstern betrifft, ist jedoch die Anzahl der definierten Elemente 100 beträgt und die entsprechenden Elemente eines Schlüssels niemals 100 erreichen, das Fenster wird niemals geschlossen und der vom Fenster besetzte Speicher wird verschwendet.
Ein weiteres nützliches Fenster, das von Flink unterstützt wird, ist das Sitzungsfenster. Das Sitzungsfenster wird bis zur Zeitüberschreitung festgelegt, dh wie lange dauert es, bis Sie glauben, dass die Sitzung beendet ist. Beispiele sind wie folgt:
Codesprache: JavaScript Anzahl der Codeläufe: 0 laufen Kopie<code class="javascript">stream.window(SessionWindows.withGap(Time.minutes(5))</code>auslösen
Neben Windows bietet Flink auch einen Triggermechanismus. Der Trigger steuert die Zeit, in der das Ergebnis generiert wird, dh wenn der Fensterinhalt aggregiert ist und das Ergebnis an den Benutzer zurückgegeben wird. Jedes Standardfenster hat einen Auslöser. Beispielsweise wird ein Zeitfenster, das die Ereigniszeit benötigt, ausgelöst, wenn ein Wasserzeichen empfangen wird. Für Benutzer können zusätzliche und genaue Ergebnisse beim Erhalt des Wasserzeichens auch benutzerdefinierte Auslöser implementiert werden.
Zeit BacktrackEine Kernfähigkeit der Stream -Verarbeitungsarchitektur ist der zeitliche Backtracking -Mechanismus. Dies bedeutet, dass der Datenstrom in der Vergangenheit in die Vergangenheit zurückspulen und den Handler bis zur Verarbeitung der aktuellen Zeit neu starten. Kafka unterstützt diese Fähigkeit.
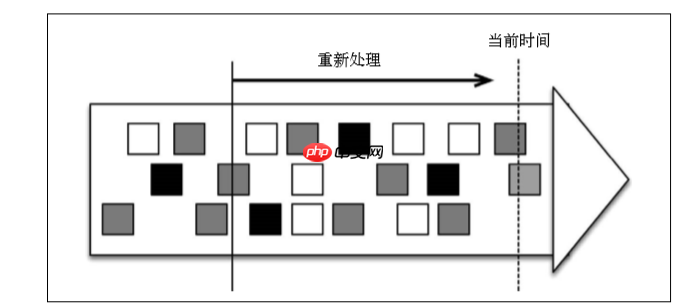
Die Echtzeit-Stream-Verarbeitung verarbeitet immer die neuesten Daten (d. H. Daten der "aktuellen Zeit" in der Abbildung), während die historische Stream-Verarbeitung in der Vergangenheit beginnt und bis zur aktuellen Zeit verarbeitet werden kann. Streaming -Prozessoren unterstützen die Ereigniszeit, was bedeutet, dass das Datenstrom "Rückspulen" bedeutet, dass das gleiche Programm mit demselben Datensatz das gleiche Ergebnis erzielt.
WasserzeichenFlink fährt die Ereigniszeit durch Wasserzeichen. Wasserzeichen ist eine herkömmliche Aufzeichnung, die in den Strom eingebettet ist. Das Berechnungsprogramm verwendet das Wasserzeichen, um zu wissen, dass ein bestimmter Zeitpunkt eingetroffen ist. Das Fenster, das das Wasserzeichen erhält, wird wissen, dass keine mehr Aufzeichnungen früher als zu diesem Zeitpunkt angezeigt werden, da alle Ereignisse mit Zeitstempeln kleiner oder gleich dieser Zeit eingetroffen sind. Zu diesem Zeitpunkt kann das Fenster das Ergebnis (Summe) sicher berechnen und geben. Wasserzeichen macht die Ereigniszeit völlig unabhängig von der Verarbeitungszeit. Die späten Wasserzeichen ("spät" erfolgt aus der Perspektive der Verarbeitungszeit) wirken sich nicht auf die Richtigkeit der Ergebnisse aus, sondern nur die Geschwindigkeit der empfangenen Ergebnisse.
Wasserzeichen werden von Anwendungsentwicklern erzeugt, die normalerweise ein bestimmtes Verständnis der entsprechenden Felder erfordern. Perfekte Wasserzeichen können niemals falsch sein: Ereignisse, deren Zeitstempel kleiner sind als die Zeit der Wasserzeichenmarke, erscheinen nicht wieder.
Wenn das Wasserzeichen zu spät ist, kann das Ergebnis sehr langsam empfangen werden. Die Lösung besteht darin, ein ungefähres Ergebnis auszugeben, bevor das Wasserzeichen ankommt (Flink kann dies tun). Wenn das Wasserzeichen zu früh eintrifft, erhalten Sie möglicherweise ein Fehlerergebnis, aber der Mechanismus von Flink, um verspätete Daten zu verarbeiten, kann dieses Problem lösen.
Verwandte Artikel: Streaming-die Zukunft von Big Data
Der Eckpfeiler der Big -Data -Verarbeitung von Echtzeit -Computing - Google DataFlow
Die Zukunft der Datenarchitektur - eine kurze Diskussion über die Streaming -Verarbeitungsarchitektur
Das obige ist der detaillierte Inhalt vonEchtzeit-Computing-Framework, das durch Zeit und Raum reisen kann-Flink-Verarbeitung von Zeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.


Stock Market GPT
KI-gestützte Anlageforschung für intelligentere Entscheidungen

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Warum habe ich nicht Xiaohongshu Qianfan App_instructions über die Berechtigungen der Xiaohongshu Qianfan App
Sep 29, 2025 pm 12:18 PM
Warum habe ich nicht Xiaohongshu Qianfan App_instructions über die Berechtigungen der Xiaohongshu Qianfan App
Sep 29, 2025 pm 12:18 PM
Sie müssen zuerst die Unternehmenszertifizierung für Unternehmen oder professionelle Konto eröffnen und ein Geschäft eröffnen, um sicherzustellen, dass das Konto nicht verletzt wird und dem Zugang zu Branchen entspricht, und die App dann auf die neueste Version aktualisieren, um den Eingang zu finden.
 Ist die Xiaohongshu Qianfan App einfach zu bedienen? Benutzererfahrung und Funktionsbewertung der Xiaohongshu Qianfan App
Sep 29, 2025 pm 12:03 PM
Ist die Xiaohongshu Qianfan App einfach zu bedienen? Benutzererfahrung und Funktionsbewertung der Xiaohongshu Qianfan App
Sep 29, 2025 pm 12:03 PM
Die Xiaohongshu Qianfan App bietet Funktionen wie Produktauftragsmanagement, Kundendienstsprachbibliothek, zeitgesteuerte Inhaltsveröffentlichung, automatische Versand für virtuelle Produkte und Berechtigungszuweisungen der Unterkontrolle und unterstützt den effizienten mobilen Betrieb. Einige Benutzer haben jedoch Leistungsprobleme wie Verzögerungen beim Hochladen von Bildern und das Senden von Nachrichten gemeldet. Es wird empfohlen, die App in einer Wi-Fi-Umgebung zu verwenden und auf dem Laufenden zu halten, um die Erfahrung zu verbessern.
 Welche kostenlose Roman -App ist besser.
Sep 29, 2025 pm 12:00 PM
Welche kostenlose Roman -App ist besser.
Sep 29, 2025 pm 12:00 PM
Antwort: Tomatenfreier Roman, Qimao Free Roman, Shuqi -Roman und Crazy Reading Novel sind vier kostenlose Lesenanwendungen mit reichen Ressourcen und reibungslosen Erfahrung. Tomate verbessert die Nachhaltigkeit des Lesens durch personalisierte Empfehlungen und Anreizmechanismen. Qimao konzentriert sich auf kostenlose Websites und stützt sich auf Werbung, um urheberrechtlich geschützte Inhalte zu unterstützen, die für Leser geeignet sind, die urbane coole Artikel und Fantasie mögen. Shuqi -Roman stützt sich auf Alibabas Ökosystem, um Romane, Comics und Videos zu integrieren und die Interoperabilität und soziale Interaktion der Richtlinien zu unterstützen. Crazy Reading Roman konzentriert sich auf qualitativ hochwertige Originalwerke und ermutigt die Benutzer, am Konstruktion des Inhalts-Ökosystems teilzunehmen. Jede Anwendung bietet Funktionen wie ein klassifiziertes Browsing, personalisierte Einstellungen, Offline -Caching usw. Einige unterstützen auch das Hören von Büchern, Notizen und Auszügen und Lesetätigkeiten, um die verschiedenen Lesebedürfnisse zu erfüllen.
 So wählen Sie die Hintergrundmusik für Douyin_recommend und Verwendung von Douyins beliebten BGMs
Sep 29, 2025 pm 12:06 PM
So wählen Sie die Hintergrundmusik für Douyin_recommend und Verwendung von Douyins beliebten BGMs
Sep 29, 2025 pm 12:06 PM
Die Priorität hat die Suche nach populären BGMs durch die Douyin Hot List, wie "The Moon of the Small Village", der sich dem pastoralen Stil anpasst. "Weinen mit dem Wind" wird für inspirierende Themen von Broken Hearts verwendet und die Kombination von Videoemotionen zur Auswahl von Musik und zum Sammeln gemeinsamer Songs zur Verbesserung der Effizienz.
 Wie deaktiviere ich ein Gastkonto für einen Computer? Schritte zum Deaktivieren eines Gastkontos
Sep 29, 2025 am 10:45 AM
Wie deaktiviere ich ein Gastkonto für einen Computer? Schritte zum Deaktivieren eines Gastkontos
Sep 29, 2025 am 10:45 AM
Um anderen die Verwendung des Computers zu erleichtern, erstellen viele Benutzer normalerweise ein Gastkonto im System. In einigen Fällen können Sie jedoch, wenn das Konto nicht mehr benötigt wird, es deaktivieren oder löschen. Wie deaktivieren Sie das Gastkonto auf Ihrem Computer? Das Folgende ist ein Windows 10 -System als Beispiel zur Einführung der spezifischen Betriebsmethode zur Deaktivierung des Gastkontos im Detail. 1. Suchen Sie das Symbol "This Computer" auf dem Desktop, klicken Sie mit der rechten Maustaste und wählen Sie die Option "Verwalten" im Popup-Menü. 2. Nach dem Eintritt in die Computerverwaltungsschnittstelle finden Sie das Element "Lokale Benutzer und Gruppen" in der Menüleiste links und klicken, um einzugeben. 3. Nachdem "lokale Benutzer und Gruppen" erweitert wurden, werden im Folgenden mehrere Subitems angezeigt, einschließlich des Verknüpfungsportals "Benutzer". 4. Klicken Sie auf "Benutzer"
 Wie setze ich die zeitgesteuerte Kugou -Musik aus? Tutorial über den Schlafmodus der Kugou -Musik
Sep 29, 2025 pm 12:09 PM
Wie setze ich die zeitgesteuerte Kugou -Musik aus? Tutorial über den Schlafmodus der Kugou -Musik
Sep 29, 2025 pm 12:09 PM
1. Öffnen Sie die Kugou -Musik -App, klicken Sie auf das drei horizontale Symbol in der oberen rechten Ecke, um das Menü einzugeben, wählen Sie "Timed Off" und setzen Sie die Countdown -Zeit, um nach Abschluss der Wiedergabe automatisch zu stoppen, und speichern Sie Strom.
 So ändern Sie die Anzahl der Schritte in WeChat -Übungsstufen_Modify und synchronisieren Sie die Anzahl der Schritte in WeChat -Übungsschritten
Sep 29, 2025 am 11:54 AM
So ändern Sie die Anzahl der Schritte in WeChat -Übungsstufen_Modify und synchronisieren Sie die Anzahl der Schritte in WeChat -Übungsschritten
Sep 29, 2025 am 11:54 AM
Das abnormale Problem mit der WeChat-Bewegung kann gelöst werden, indem Systemgesundheitsdaten geändert, Simulationstools von Drittanbietern verwendet werden, die Berechtigungseinstellungen überprüft und manuell erfrischend werden.
 Persistente Gedächtnisprogrammierung
Sep 30, 2025 am 10:47 AM
Persistente Gedächtnisprogrammierung
Sep 30, 2025 am 10:47 AM
Persistente Gedächtnisprogrammierung Juni 2013 Ich schrieb über zukünftige Schnittstellen für nichtflüchtige Erinnerungen (NVM). Dies beschreibt das NVM -Programmiermodell, das von Snianvm ProgrammingtechnicalWorkGroup (TWG) entwickelt wird. In den letzten vier Jahren wurden Spezifikationen veröffentlicht, und wie vorhergesagt wurden Programmiermodelle zum Schwerpunkt vieler Follow-up-Bemühungen. Dieses Programmiermodell, das in der Spezifikation als nvm.pm.File beschrieben wird, kann PM durch das Betriebssystem als Datei dem Speicher zuordnen. In diesem Artikel wird vorgestellt, wie das persistente Speicherprogrammiermodell im Betriebssystem implementiert wird, welche Arbeiten und mit welchen Herausforderungen wir noch vorstellen. Persistierter Speicherhintergrund PM und StorageClassMe
