


Diese bahnbrechende Umfrage "Datensätze für Großsprachenmodelle: Eine umfassende Umfrage, die im Februar 2024 veröffentlicht wurde, enthüllt eine Schatzkammer mit über 400 akribisch kategorisierten Datensätzen für die Entwicklung des LLM -Modells (Language Model). Zusammengestellt von Yang Liu, Jiahuan Cao, Chongyu Liu, Kai Ding und Lianwen Jin ist diese Ressource eine Goldmine für Forscher und Entwickler. Es ist nicht nur eine statische Sammlung; Es wird regelmäßig aktualisiert, um seine anhaltende Relevanz zu gewährleisten.
Das Papier bietet einen umfassenden Überblick über LLM -Datensätze, das für das Verständnis der Grundlage dieser leistungsstarken Modelle von wesentlicher Bedeutung ist. Die Datensätze werden in sieben wichtigsten Dimensionen kategorisiert: Voraussetzungskorpora, Befehlsfeinabeinstellungsdatensätze, Präferenzdatensätze, Bewertungsdatensätze, herkömmliche NLP-Datensätze, MLLL-Datensätze (Multi-Modal Language Models) (MLLLMS) und ARRAVAL ARRAVAL AUSGEGENTED-DATASETS (ARRAVAL ARRAVED ERGENTELIGE EINGEGEBEN. Die schiere Skala ist beeindruckend, mit über 774,5 TB Daten allein für die Vorausbildung und 700 Millionen Instanzen in anderen Kategorien, die 32 Domänen und 8 Sprachen umfassen.

Schlüsselkategorien und Beispiele für Datensatze:
Die Umfrage beschreibt verschiedene Datensatzstypen, darunter:
Voraussetzungskorpora: Massive Textsammlungen für das erste LLM-Training. Beispiele sind Madlad-400 (2,8T-Token), Fineweb (15 TB-Token) und Bookcorpusopen (17.868 Bücher). Diese werden weiter in allgemeine Korpora (Webseiten, Bücher, Sprachtexte) und domänenspezifische Korpora (Finanzen, Medizin, Mathematik) unterteilt.
Befehl feinabstimmungsdatensätze: Anweisungspaare und entsprechende Antworten zur Verfeinerung des Modellverhaltens. Beispiele sind Datenbanken-Dolly-15K und Alpaca_Data. Diese werden auch in allgemeine und domänenspezifische (medizinische, Code-) Datensätze eingeteilt.
Präferenzdatensätze: Wird zur Bewertung und Verbesserung der Modellausgaben durch Vergleich mehrerer Antworten verwendet. Beispiele sind Chatbot_arena_Conversations und HH-RLHF.
Bewertungsdatensätze: speziell für die Benchmark -LLM -Leistung bei verschiedenen Aufgaben entwickelt. Beispiele sind Alpakaeval und Bayling-80.
Herkömmliche NLP-Datensätze: Datensätze, die für Pre-Llm-NLP-Aufgaben verwendet werden. Beispiele sind Boolq, Cosmosqa und PubMedqa.
Datensätze mit Multimodal großer Sprache (MLLMS): Datensätze, die Text und andere Modalitäten (Bilder, Videos) kombinieren. Beispiele sind Moscar und MMRS-1M.
Datensätze (Abrufener Augmented Generation): Datensätze, die LLMs mit externen Datenabruffunktionen verbessern. Beispiele sind Crud-Rag und Wikieval.

Quelle: Datensätze für große Sprachmodelle: Eine umfassende Umfrage
Die Architektur der Umfrage ist unten dargestellt:
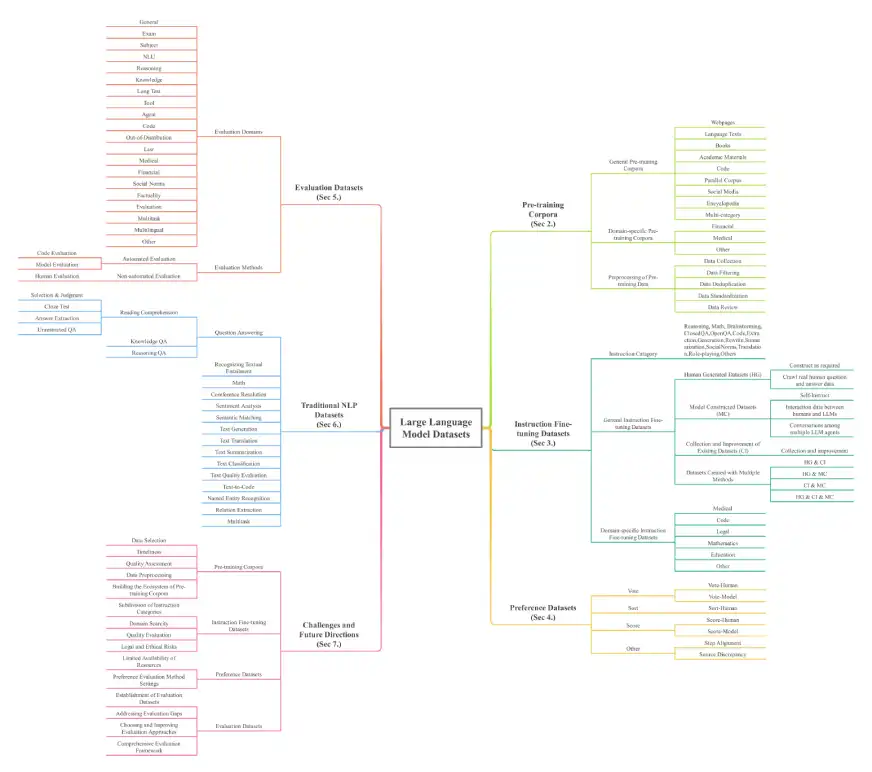
Schlussfolgerung und weitere Untersuchung:
Diese Umfrage dient als wichtige Ressource und führt Forscher und Entwickler im LLM -Bereich. Das bereitgestellte Repository (Awesome-LlMS-Datensätze) bietet eine komplette Roadmap für den Zugriff und die Verwendung dieser unschätzbaren Datensätze. Die detaillierte Kategorisierung und die umfassende Statistiken machen es zu einem wesentlichen Instrument für alle, die mit LLMs arbeiten oder erforscht. Das Papier befasst sich auch mit den wichtigsten Herausforderungen und schlägt zukünftige Forschungsrichtungen vor.
Das obige ist der detaillierte Inhalt vonEin Leitfaden zu 400 kategorisierten Datensätzen für Großsprachenmodell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 binäre Arithmetik
binäre Arithmetik
 So verwenden Sie Shuffle
So verwenden Sie Shuffle
 So kaufen Sie echte Ripple-Münzen
So kaufen Sie echte Ripple-Münzen
 So starten Sie den Dienst im Swoole-Framework neu
So starten Sie den Dienst im Swoole-Framework neu
 Telnet-Befehl
Telnet-Befehl
 Verwendung der Informix-Funktion
Verwendung der Informix-Funktion
 So legen Sie den gepunkteten CSS-Rahmen fest
So legen Sie den gepunkteten CSS-Rahmen fest
 Aktuelles Ranking der digitalen Währungsbörsen
Aktuelles Ranking der digitalen Währungsbörsen
 Was sind die sieben Prinzipien der PHP-Codespezifikationen?
Was sind die sieben Prinzipien der PHP-Codespezifikationen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



