


In vielen realen Anwendungen sind Daten nicht rein textuell-es kann Bilder, Tabellen und Diagramme enthalten, die dazu beitragen, die Erzählung zu verstärken. Mit einem multimodalen Berichtsgenerator können Sie sowohl Text als auch Bilder in eine endgültige Ausgabe einbeziehen, wodurch Ihre Berichte dynamischer und visuell reicher werden.
In diesem Artikel wird beschrieben, wie eine solche Pipeline mit:
erstellt wirdDas Endergebnis ist eine Pipeline, die ein ganzes PDF -Diagrammdeck - sowohl Text als auch Visuals - verarbeiten und einen strukturierten Bericht erstellen kann, der sowohl Text als auch Bilder enthält.
Dieser Artikel wurde als Teil des Data Science -Blogathon veröffentlicht.
Sobald das Setup abgeschlossen ist, verarbeitet die Pipeline ein PDF -Dokument, das seinen Inhalt in strukturierten Text analysiert und visuelle Elemente wie Tabellen und Diagramme rendert. Diese analysierten Elemente werden dann zugeordnet und erstellen einen einheitlichen Datensatz. Ein Zusammenfassungsindex wurde entwickelt, um hochrangige Erkenntnisse zu ermöglichen, und eine strukturierte Abfrage-Engine wird entwickelt, um Berichte zu erstellen, die Textanalysen mit relevanten Visuals kombinieren. Das Ergebnis ist ein dynamischer und interaktiver Berichtsgenerator, der statische Dokumente in reichhaltige, multimodale Ausgänge umwandelt, die auf Benutzeranfragen zugeschnitten sind.
Befolgen Sie diese detaillierte Anleitung, um einen multimodalen Berichtsgenerator zu erstellen, vom Einrichten von Abhängigkeiten bis hin zum Generieren strukturierter Ausgänge mit integrierten Text und Bildern. Jeder Schritt sorgt für eine nahtlose Integration von Llamaindex, Llamaparse und Arize Phoenix für eine effiziente und dynamische Pipeline.
Sie benötigen die folgenden Bibliotheken auf Python 3.9.9:
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Wir integrieren in Lamatrace - Llamacloud API (Arize Phoenix). Erhalten Sie zuerst einen API -Schlüssel von llamatrace.com und richten Sie dann Umgebungsvariablen ein, um Spuren an Phoenix zu senden.
Phoenix -API -Schlüssel kann erhalten werden, indem Sie sich hier für Lamatrace anmelden, dann zum unteren linken Bereich navigieren und auf "Tasten" klicken, wo Sie Ihre API -Taste finden sollten.
Zum Beispiel:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)Zur Demonstration verwenden wir Conocophillips '2023 Investor Meeting Slide Deck. Wir laden das PDF herunter:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Überprüfen Sie, ob sich das PDF -Diasdeck im Datenordner befindet. Wenn Sie es nicht im Datenordner platzieren, und so wie Sie möchten.
Sie benötigen ein Einbettungsmodell und ein LLM. In diesem Beispiel:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Als nächstes registrieren Sie diese als Standard für llamaindex:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
llamaparse kann Text und Bilder extrahieren (über ein multimodales großes Modell). Für jede PDF -Seite kehrt sie zurück:
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])
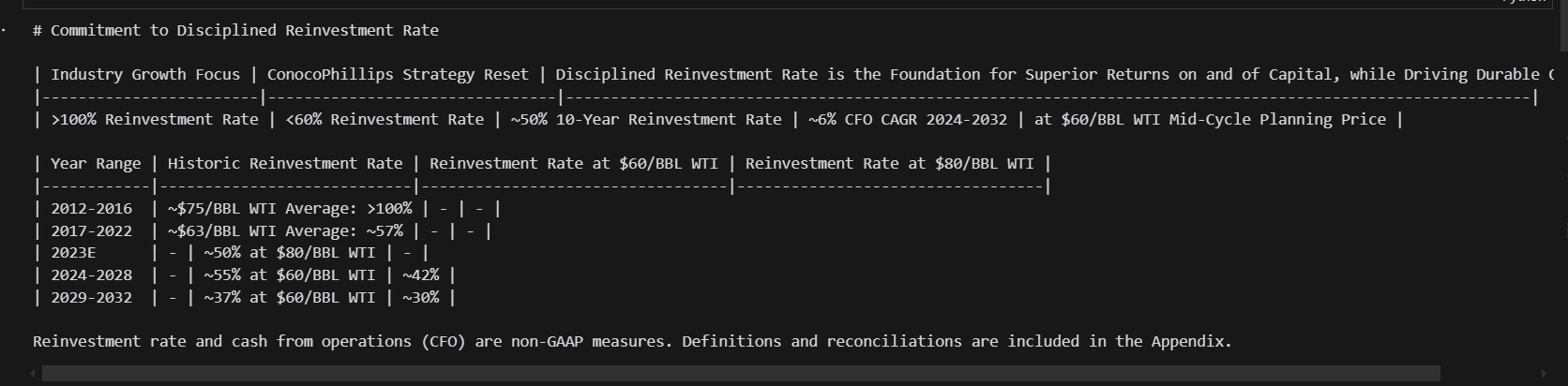
print(md_json_list[1].keys())

!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Wir erstellen für jede Seite eine Liste von Textnode Objekte (Lamaindex -Datenstruktur). Jeder Knoten hat Metadaten über die Seitenzahl und den entsprechenden Bilddateipfad:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
) 
Mit diesen Textknoten in der Hand können Sie einen zusammenfassendenIndex erstellen:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Der SummaryIndex stellt sicher, dass Sie über das gesamte Dokument leicht abrufen oder hochrangige Zusammenfassungen erzeugen können.
Unsere Pipeline zielt darauf ab, eine endgültige Ausgabe mit verschachtelten Textblöcken und Bildblöcken zu erzeugen. For that, we create a custom Pydantic model (using Pydantic v2 or ensuring compatibility) with two block types—TextBlock and ImageBlock—and a parent model ReportOutput:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Der Schlüsselpunkt: reportOutput erfordert mindestens einen Bildblock, um sicherzustellen, dass die endgültige Antwort multimodal ist.
llamaindex können Sie ein „strukturiertes LLM“ verwenden (d. H. Ein LLM, dessen Ausgabe automatisch in ein bestimmtes Schema analysiert wird). So ist:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm

print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])

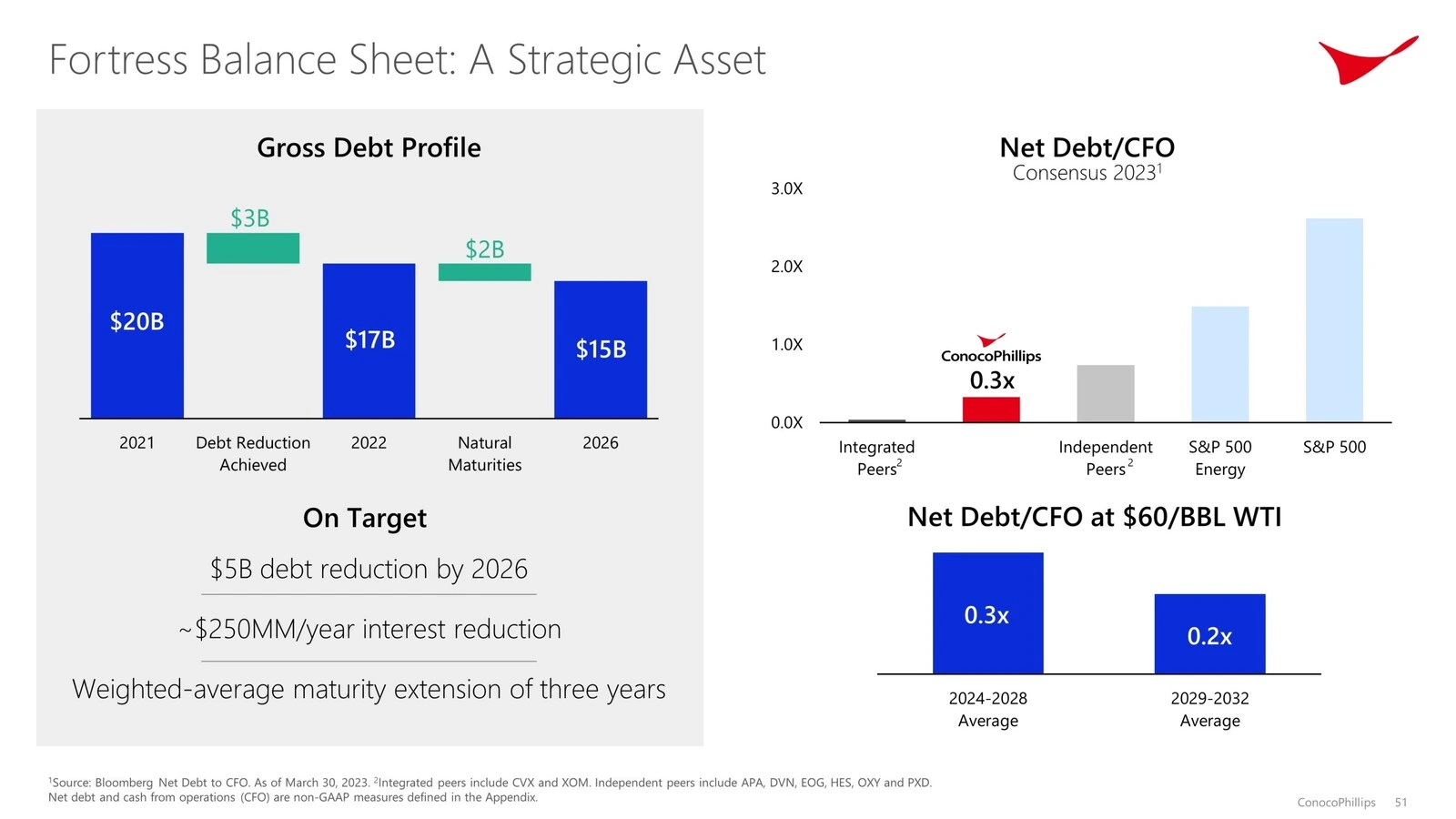
Durch Kombination von Llamaindex, Llamaparse und OpenAI können Sie einen multimodalen Berichtsgenerator erstellen, der einen gesamten PDF (mit Text, Tabellen und Bildern) in eine strukturierte Ausgabe verarbeitet. Dieser Ansatz liefert umfangreichere und visuell informative Ergebnisse - genau das, was die Stakeholder für kritische Erkenntnisse aus komplexen Unternehmens- oder technischen Dokumenten benötigen.
Sie können diese Pipeline gerne an Ihre eigenen Dokumente anpassen, einen Abrufschritt für große Archive hinzufügen oder domänenspezifische Modelle zur Analyse der zugrunde liegenden Bilder integrieren. Mit den hier festgelegten Grundlagen können Sie dynamische, interaktive und visuell reiche Berichte erstellen, die weit über einfache textbasierte Abfragen hinausgehen.
Ein großes Dankeschön an Jerry Liu von Llamaindex für die Entwicklung dieser erstaunlichen Pipeline.
a. Ein multimodaler Berichtsgenerator ist ein System, das Berichte erstellt, die mehrere Arten von Inhalten - vor allem Text und Bilder - in einer zusammenhängenden Ausgabe enthalten. In dieser Pipeline analysieren Sie ein PDF sowohl in Text- als auch in visuelle Elemente und kombinieren sie dann zu einem einzigen Abschlussbericht.
Q2. Warum muss ich Lama-Index-Callbacks-Arize-Phoenix installieren und die Beobachtbarkeit aufstellen?a. Beobachtbarkeitsinstrumente wie Arize Phoenix (über Lamatrace) können Sie das Modellverhalten des Modells überwachen und debuggen, Abfragen und Antworten verfolgen und Probleme in Echtzeit identifizieren. Es ist besonders nützlich, wenn es um große oder komplexe Dokumente und mehrere LLM-basierte Schritte geht.
Q3. Warum Lamaparse anstelle eines Standard -PDF -Text -Extraktors verwenden?a. Die meisten PDF -Text -Extraktoren verarbeiten nur Rohtext und verlieren häufig Formatierung, Bilder und Tabellen. Llamaparse kann sowohl Text als auch Bilder (gerenderte Seitenbilder) extrahieren, was für die Erstellung multimodaler Pipelines entscheidend ist, wo Sie sich auf Tabellen, Diagramme oder andere Visuals beziehen müssen.
Q4. Was ist der Vorteil der Verwendung eines summaryIndex?a. SummaryIndex ist eine Lamaindex -Abstraktion, die Ihren Inhalt (z. B. Seiten eines PDF) organisiert, damit sie schnell umfassende Zusammenfassungen erzeugen kann. Es hilft, hochrangige Erkenntnisse aus langen Dokumenten zu sammeln, ohne sie manuell einteilen oder eine Abrufabfrage für jedes Datenstück ausführen zu müssen.
Q5. Wie stelle ich sicher, dass der Abschlussbericht mindestens einen Bildblock enthält?a. Durch das pydantische Modell von Reportputs erfordern die Liste der Blöcke mindestens ein ImageBlock. Dies wird in Ihrer System -Eingabeaufforderung und Ihrem System angegeben. Das LLM muss diese Regeln befolgen, oder es erzeugt keine gültige strukturierte Ausgabe.
Die in diesem Artikel gezeigten Medien sind nicht im Besitz von Analytics Vidhya und wird nach Ermessen des Autors verwendet.
Das obige ist der detaillierte Inhalt vonErzeugung multimodaler Finanzberichte unter Verwendung von Llamaindex. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Plattform ist Kuai Tuan Tuan?
Welche Plattform ist Kuai Tuan Tuan?
 Selbststudium für Anfänger in C-Sprache ohne Grundkenntnisse
Selbststudium für Anfänger in C-Sprache ohne Grundkenntnisse
 So verwenden Sie die Imfinfo-Funktion
So verwenden Sie die Imfinfo-Funktion
 regulärer Perl-Ausdruck
regulärer Perl-Ausdruck
 So konvertieren Sie PDF-Dateien in PDF
So konvertieren Sie PDF-Dateien in PDF
 Lösungen für verstümmelte chinesische Schriftzeichen
Lösungen für verstümmelte chinesische Schriftzeichen
 Der Unterschied zwischen PHP und JS
Der Unterschied zwischen PHP und JS
 Wie man Douyin Xiaohuoren verkleidet
Wie man Douyin Xiaohuoren verkleidet








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



