


Februar 2023: Ich wollte alle Partituren für Filme und Fernsehsendungen auf einer Seite sehen und wissen, wo ich sie streamen kann, konnte aber keinen Aggregator finden, der alle für mich relevanten Quellen enthält.
März 2023: Also habe ich ein MVP erstellt, das spontan Punkte sammelte, und die Website online gestellt. Es hat funktioniert, war aber langsam (10 Sekunden, um die Ergebnisse anzuzeigen).
Okt 2023: Da mir klar wurde, dass das Speichern von Daten auf meiner Seite eine Notwendigkeit ist, habe ich windmill.dev entdeckt. Es stellt ähnliche Orchestrierungs-Engines deutlich in den Schatten – zumindest für meine Bedürfnisse.
Schneller Vorlauf bis heute und nach 12 Monaten ununterbrochener Datensuche möchte ich Ihnen mitteilen, wie die Pipeline im Detail funktioniert. Sie erfahren, wie Sie ein komplexes System aufbauen, das Daten aus vielen verschiedenen Quellen erfasst, Daten normalisiert und in einem optimierten Format für Abfragen kombiniert.

Dies ist die Ausführungsansicht. Jeder Punkt repräsentiert einen Flow-Lauf. Ein Flow kann alles sein, zum Beispiel ein einfaches Ein-Schritt-Skript:

Der Block in der Mitte enthält ein Skript wie dieses (vereinfacht):
def main():
return tmdb_extract_daily_dump_data()
def tmdb_extract_daily_dump_data():
print("Checking TMDB for latest daily dumps")
init_mongodb()
daily_dump_infos = get_daily_dump_infos()
for daily_dump_info in daily_dump_infos:
download_zip_and_store_in_db(daily_dump_info)
close_mongodb()
return [info.to_mongo() for info in daily_dump_infos]
[...]
Das folgende Biest ist ebenfalls ein Flow (denken Sie daran, dies ist nur einer der grünen Punkte):

(Bild mit höherer Auflösung: https://i.imgur.com/LGhTUGG.png)
Lass uns das aufschlüsseln:
Jeder dieser Schritte ist mehr oder weniger komplex und erfordert die Verwendung asynchroner Prozesse.
Um zu bestimmen, welche Titel als nächstes ausgewählt werden sollen, werden zwei Spuren parallel verarbeitet. Dies ist ein weiterer Bereich, in dem Windmill glänzt. Parallelisierung und Orchestrierung funktionieren mit ihrer Architektur einwandfrei.
Die beiden Spuren zur Auswahl des nächsten Artikels sind:
Zunächst werden Titel, an die keine Daten angehängt sind, für jede Datenquelle ausgewählt. Das heißt, wenn die Metacritic-Pipeline einen Film enthält, der noch nicht gescrapt wurde, wird dieser als nächstes ausgewählt. Dadurch wird sichergestellt, dass jeder Titel, auch neue, mindestens einmal verarbeitet wurde.
Sobald an jeden Titel Daten angehängt sind, wählt die Pipeline diejenigen mit den am wenigsten aktuellen Daten aus.
Hier ist ein Beispiel für einen solchen Flow-Lauf, hier mit einem Fehler, weil das Ratenlimit erreicht wurde:

Mit Windmill können Sie ganz einfach Wiederholungsversuche für jeden Schritt im Ablauf definieren. In diesem Fall besteht die Logik darin, es im Fehlerfall dreimal erneut zu versuchen. Sofern das Ratenlimit nicht erreicht wurde (was normalerweise ein anderer Statuscode oder eine andere Fehlermeldung ist), stoppen wir sofort.
Das oben Gesagte funktioniert, weist jedoch ein ernstes Problem auf: neue Versionen werden nicht rechtzeitig genug aktualisiert. Es kann Wochen oder sogar Monate dauern, bis alle Datenaspekte erfolgreich abgerufen wurden. Beispielsweise kann es vorkommen, dass ein Film über einen aktuellen IMDb-Score verfügt, die anderen Scores jedoch veraltet sind und die Streaming-Links komplett fehlen. Insbesondere bei den Spielständen und der Streaming-Verfügbarkeit wollte ich eine deutlich bessere Genauigkeit erreichen.
Um dieses Problem zu lösen, konzentriert sich die zweite Spur auf eine andere Priorisierungsstrategie: Die beliebtesten und angesagtesten Filme/Sendungen werden für eine vollständige Datenaktualisierung über alle Datenquellen hinweg ausgewählt.Ich habe diesen Ablauf bereits zuvor gezeigt, Es ist das, das ich vorhin als Biest bezeichnet habe.
Titel, die häufiger in der App angezeigt werden, erhalten ebenfalls einen Prioritätsschub. Das bedeutet, dass jedes Mal, wenn ein Film oder eine Sendung in den Top-Suchergebnissen auftaucht oder wenn die Detailansicht geöffnet wird, diese wahrscheinlich bald aktualisiert werden.
Jeder Titel kann nur einmal pro Woche aktualisiert werden unter Verwendung der Prioritätsspur, um sicherzustellen, dass wir keine Daten abrufen, die sich in der Zwischenzeit wahrscheinlich nicht geändert haben.
Sie fragen sich vielleicht: Ist Scraping legal? Das Erfassen der Daten ist normalerweise in Ordnung. Was Sie mit den Daten tun, muss jedoch sorgfältig überlegt werden. Sobald Sie von einem Dienst profitieren, der gescrapte Daten verwendet, verstoßen Sie wahrscheinlich gegen deren Geschäftsbedingungen. (siehe „Die Rechtslandschaft des Web Scraping“ und „Scraping“ ist nur automatisierter Zugriff, und jeder tut es )
Scraping und damit verbundene Gesetze sind neu und oft ungetestet und es gibt viele rechtliche Grauzonen. Ich bin entschlossen, jede Quelle entsprechend zu zitieren, Tarifbeschränkungen zu respektieren und unnötige Anfragen zu vermeiden, um die Auswirkungen auf ihre Dienste zu minimieren.
Fakt ist, dass die Daten nicht zur Erzielung von Gewinnen verwendet werden. GoodWatch wird für immer für alle kostenlos nutzbar sein.
Windmill verwendet Worker, um die Codeausführung auf mehrere Prozesse zu verteilen. Jeder Schritt in einem Ablauf wird an einen Worker gesendet, wodurch er von der eigentlichen Geschäftslogik unabhängig wird. Nur die Haupt-App orchestriert die Jobs, während Worker nur Eingabedaten und Code zur Ausführung erhalten und das Ergebnis zurückgeben.
Es ist eine effiziente Architektur, die sich gut skalieren lässt. Derzeit sind es 12 Arbeiter, die sich die Arbeit aufteilen. Sie werden alle auf Hetzner gehostet.
Jeder Worker hat einen maximalen Ressourcenverbrauch von 1 vCPU und 2 GB RAM. Hier eine Übersicht:

Windmill bietet ein browserinternes IDE-ähnliches Editor-Erlebnis mit Linting, automatischer Formatierung, einem KI-Assistenten und sogar kollaborativer Bearbeitung (Letztes ist eine kostenpflichtige Funktion). Das Beste ist jedoch dieser Button:
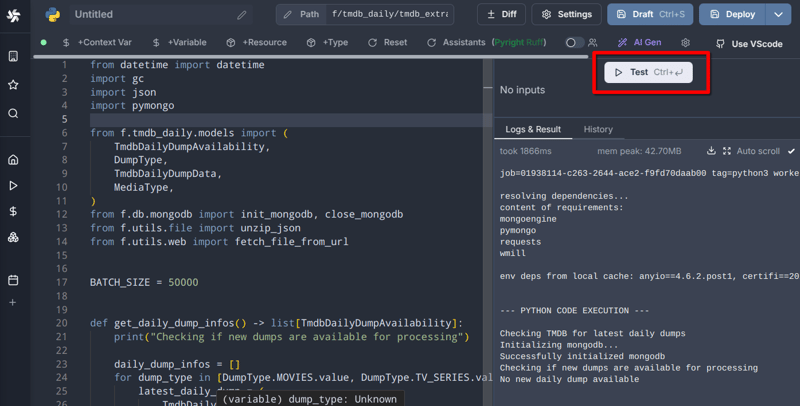
Es ermöglicht mir, Skripte schnell zu iterieren und zu testen, bevor ich sie bereitstelle. Normalerweise bearbeite und teste ich Dateien im Browser und schiebe sie auf Git, wenn ich fertig bin.
Das Einzige, was für eine optimale Codierungsumgebung fehlt, sind Debugging-Tools (Haltepunkte und variabler Kontext). Derzeit debugge ich Skripte in meiner lokalen IDE, um diese Schwachstelle zu beheben.
Ich auch!
Derzeit benötigt GoodWatch etwa 100 GB dauerhaften Datenspeicher:
Jeden Tag laufen 6.500 Flows durch die Orchestrierungs-Engine von Windmill. Daraus ergibt sich ein Tagesvolumen von:
Diese Zahlen unterscheiden sich aufgrund unterschiedlicher Ratenbegrenzungsrichtlinien grundlegend.
Einmal pro Tag werden die Daten bereinigt und zum endgültigen Datenformat zusammengefasst. Derzeit ist die Datenbank, die die GoodWatch-Webapp-Stores betreibt:
Stellen Sie sich vor, Sie könnten Filme nur nach ihrem Genre unterscheiden, was äußerst einschränkend ist, oder?
Deshalb habe ich das DNA-Projekt gestartet. Es ermöglicht die Kategorisierung von Filmen und Shows nach anderen Attributen wie Stimmung, Plotelements, Charaktertypen, Dialog oder Schlüssel-Requisiten .
Hier sind die Top 10 aller DNA-Werte über alle Artikel hinweg:

Es ermöglicht zwei Dinge:
Beispiele:
Es wird in Zukunft einen eigenen Blogbeitrag über die DNA mit vielen weiteren Details geben.
Um die Funktionsweise der Datenpipeline vollständig zu verstehen, finden Sie hier eine Aufschlüsselung der Ereignisse für jede Datenquelle:
Für jede Datenquelle gibt es einen Init-Flow, der eine MongoDB-Sammlung mit allen erforderlichen Daten vorbereitet. Für IMDb ist das nur die imdb_id. Für Rotten Tomatoes sind der Titel und das Erscheinungsjahr erforderlich. Das liegt daran, dass die ID unbekannt ist und wir anhand des Namens die richtige URL erraten müssen.
Basierend auf der oben erläuterten Prioritätsauswahl werden Elemente in den vorbereiteten Sammlungen mit den abgerufenen Daten aktualisiert. Jede Datenquelle verfügt über eine eigene Sammlung, die mit der Zeit immer vollständiger wird.
Es gibt einen Ablauf für Filme, einen für Fernsehsendungen und einen weiteren für Streaming-Links. Sie sammeln alle notwendigen Daten aus verschiedenen Sammlungen und speichern sie in ihren jeweiligen Postgres-Tabellen, die dann von der Webanwendung abgefragt werden.
Hier ist ein Auszug aus dem Ablauf und dem Skript zum Kopieren von Filmen:

Die Ausführung einiger dieser Flows dauert lange, manchmal sogar länger als 6 Stunden. Dies kann optimiert werden, indem alle aktualisierten Elemente markiert und nur diese kopiert werden, anstatt den gesamten Datensatz stapelweise zu verarbeiten. Einer von vielen TODO-Punkten auf meiner Liste ?
Die Planung ist so einfach wie das Definieren von Cron-Ausdrücken für jeden Ablauf oder jedes Skript, das automatisch ausgeführt werden muss:

Hier ein Auszug aller Zeitpläne, die für GoodWatch definiert sind:

Insgesamt sind rund 50 Zeitpläne definiert.
Mit großartigen Daten geht große Verantwortung einher. Es kann viel schiefgehen. Und das tat es.
Frühe Versionen meiner Skripte brauchten ewig, um alle Einträge in einer Sammlung oder Tabelle zu aktualisieren. Das lag daran, dass ich jeden Artikel einzeln eingefügt habe. Das verursacht viel Overhead und verlangsamt den Prozess erheblich.
Ein viel besserer Ansatz besteht darin, die einzufügenden Daten zu sammeln und die Datenbankabfragen in einem Batch durchzuführen. Hier ist ein Beispiel für MongoDB:
def main():
return tmdb_extract_daily_dump_data()
def tmdb_extract_daily_dump_data():
print("Checking TMDB for latest daily dumps")
init_mongodb()
daily_dump_infos = get_daily_dump_infos()
for daily_dump_info in daily_dump_infos:
download_zip_and_store_in_db(daily_dump_info)
close_mongodb()
return [info.to_mongo() for info in daily_dump_infos]
[...]
Selbst bei der Stapelverarbeitung verbrauchten einige Skripte so viel Speicher, dass die Worker abstürzten. Die Lösung bestand darin, die Chargengröße für jeden Anwendungsfall sorgfältig abzustimmen.
Einige Stapel lassen sich gut in 5000er-Schritten ausführen, andere speichern viel mehr Daten im Speicher und laufen besser mit 500er-Schritten.
Windmill verfügt über eine großartige Funktion, um den Speicher zu beobachten, während ein Skript ausgeführt wird:

Windmill ist eine große Bereicherung im Toolkit jedes Entwicklers zur Automatisierung von Aufgaben. Für mich war es ein unschätzbarer Produktivitätsschub, da ich mich auf die Ablaufstruktur und die Geschäftslogik konzentrieren konnte, während ich die schwere Arbeit der Aufgabenkoordinierung, Fehlerbehandlung, Wiederholungsversuche und Caching auslagerte.
Der Umgang mit großen Datenmengen ist immer noch eine Herausforderung und die Optimierung der Pipeline ist ein fortlaufender Prozess – aber ich bin wirklich zufrieden damit, wie sich bisher alles entwickelt hat.
Das dachte ich mir. Lassen Sie mich einfach ein paar Ressourcen verlinken und wir sind fertig:
Wussten Sie, dass GoodWatch Open Source ist? Sie können sich alle Skripte und Flow-Definitionen in diesem Repository ansehen: https://github.com/alp82/goodwatch-monorepo/tree/main/goodwatch-flows/windmill/f
Lassen Sie es mich wissen, wenn Sie Fragen haben.
Das obige ist der detaillierte Inhalt vonEine Datenpipeline für Millionen Filme und Millionen Streaming-Links. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist Kryptowährung Kol
Was ist Kryptowährung Kol
 Einführung in SSL-Erkennungstools
Einführung in SSL-Erkennungstools
 Lösung zur Verlangsamung der Zugriffsgeschwindigkeit bei der Anmietung eines US-Servers
Lösung zur Verlangsamung der Zugriffsgeschwindigkeit bei der Anmietung eines US-Servers
 Das heißt, die Verknüpfung kann nicht gelöscht werden
Das heißt, die Verknüpfung kann nicht gelöscht werden
 Was ist der Unterschied zwischen USB-C und TYPE-C?
Was ist der Unterschied zwischen USB-C und TYPE-C?
 Lösung für die Meldung „Ungültige Partitionstabelle' beim Start von Windows 10
Lösung für die Meldung „Ungültige Partitionstabelle' beim Start von Windows 10
 So lösen Sie 404 nicht gefunden
So lösen Sie 404 nicht gefunden
 Was tun, wenn Chrome keine Plugins laden kann?
Was tun, wenn Chrome keine Plugins laden kann?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



