


GraphQL ist eine Abfragesprache zum Abrufen tief verschachtelter strukturierter Daten aus dem Backend einer Website, ähnlich wie MongoDB-Abfragen.
Die Anfrage ist normalerweise ein POST an einen allgemeinen /graphql-Endpunkt mit einem Text wie diesem:

Bei großen Datenstrukturen wird dies jedoch ineffizient – Sie senden eine große Abfrage in einem POST-Anfragetext, der (fast immer) derselbe ist und sich nur bei Website-Updates ändert; POST-Anfragen können nicht zwischengespeichert werden usw. Daher wurde eine Erweiterung namens „Persisted Queries“ entwickelt. Das ist kein Anti-Scraping-Geheimnis; Die öffentliche Dokumentation dazu können Sie hier lesen.
TLDR: Der Client berechnet den sha256-Hash des Abfragetexts und sendet nur diesen Hash. Darüber hinaus können Sie all dies möglicherweise in die Abfragezeichenfolge einer GET-Anfrage einfügen, sodass es leicht zwischengespeichert werden kann. Unten finden Sie eine Beispielanfrage von Zillow

Wie Sie sehen können, handelt es sich lediglich um einige Metadaten über die persistedQuery-Erweiterung, den Hash der Abfrage und in die Abfrage einzubettende Variablen.
Hier ist eine weitere Anfrage von expedia.com, gesendet als POST, aber mit derselben Erweiterung:

Dies optimiert in erster Linie die Website-Leistung, stellt das Web Scraping jedoch vor mehrere Herausforderungen:
Aus verschiedenen Gründen kann es daher sein, dass Sie den gesamten Abfragetext extrahieren müssen. Sie könnten das JavaScript der Website durchforsten und mit etwas Glück dort den Abfragetext möglicherweise vollständig finden, aber oft wird er irgendwie dynamisch aus mehreren Fragmenten usw. erstellt.
Deshalb haben wir einen besseren Weg gefunden: Wir werden das clientseitige JavaScript überhaupt nicht anfassen. Stattdessen werden wir versuchen, die Situation zu simulieren, in der der Client versucht, einen Hash zu verwenden, den der Server nicht kennt. Daher müssen wir die (gültige) Anfrage, die der Browser während des Flugs sendet, abfangen und den Hash in einen falschen ändern, bevor wir ihn an den Server weiterleiten.
Für genau diesen Anwendungsfall gibt es ein perfektes Tool: mitmproxy, eine Open-Source-Python-Bibliothek, die Anfragen Ihrer eigenen Geräte, Websites oder Apps abfängt und es Ihnen ermöglicht, diese mit einfachen Python-Skripten zu ändern.
Laden Sie mitmproxy herunter und bereiten Sie ein Python-Skript wie dieses vor:
import json
def request(flow):
try:
dat = json.loads(flow.request.text)
dat[0]["extensions"]["persistedQuery"]["sha256Hash"] = "0d9e" # any bogus hex string here
flow.request.text = json.dumps(dat)
except:
pass
Dies definiert einen Hook, den Mitmproxy bei jeder Anfrage ausführt: Er versucht, den JSON-Body der Anfrage zu laden, ändert den Hash in einen beliebigen Wert und schreibt den aktualisierten JSON als neuen Body der Anfrage.
Wir müssen außerdem sicherstellen, dass wir unsere Browseranfragen an mitmproxy umleiten. Zu diesem Zweck verwenden wir eine Browsererweiterung namens FoxyProxy. Es ist sowohl in Firefox als auch in Chrome verfügbar.
Fügen Sie einfach eine Route mit diesen Einstellungen hinzu:

Jetzt können wir mitmproxy mit diesem Skript ausführen: mitmweb -s script.py
Dadurch wird ein Browser-Tab geöffnet, in dem Sie alle abgefangenen Anfragen in Echtzeit verfolgen können.

Wenn Sie zu dem jeweiligen Pfad gehen und die Abfrage im Anforderungsabschnitt sehen, werden Sie feststellen, dass der Hash durch einen Müllwert ersetzt wurde.
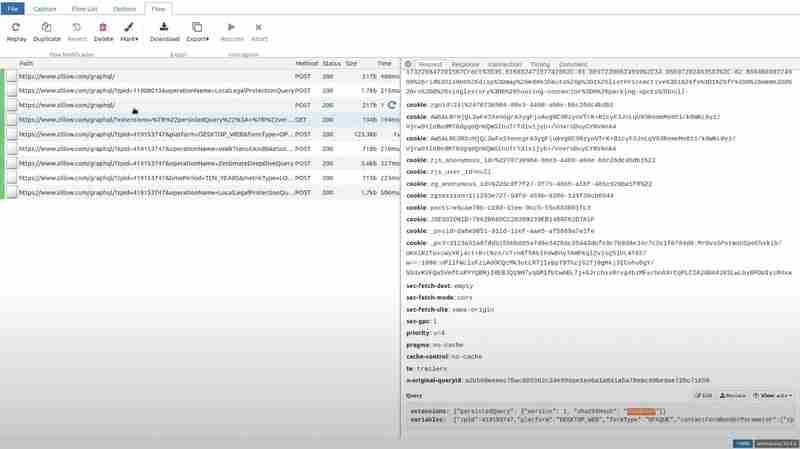
Wenn Sie nun Zillow besuchen und den bestimmten Pfad öffnen, den wir für die Erweiterung ausprobiert haben, und zum Antwortabschnitt gehen, erhält die Clientseite den Fehler PersistedQueryNotFound.

Das Frontend von Zillow reagiert mit dem Senden der gesamten Abfrage als POST-Anfrage.

Wir extrahieren die Abfrage und den Hash direkt aus dieser POST-Anfrage. Um sicherzustellen, dass der Zillow-Server diesen Hash nicht vergisst, führen wir diese POST-Anfrage regelmäßig mit genau derselben Abfrage und demselben Hash aus. Dadurch wird sichergestellt, dass der Scraper auch dann weiter funktioniert, wenn der Cache des Servers bereinigt oder zurückgesetzt wird oder sich die Website ändert.
Fazit
Persistente Abfragen sind ein leistungsstarkes Optimierungstool für GraphQL-APIs, das die Website-Leistung verbessert, indem es die Nutzlastgröße minimiert und das Caching von GET-Anfragen ermöglicht. Sie stellen jedoch auch erhebliche Herausforderungen für das Web Scraping dar, vor allem aufgrund der Abhängigkeit von servergespeicherten Hashes und der Möglichkeit, dass diese Hashes ungültig werden.
Die Verwendung von mitmproxy zum Abfangen und Bearbeiten von GraphQL-Anfragen bietet einen effizienten Ansatz, um den vollständigen Abfragetext anzuzeigen, ohne sich mit komplexem clientseitigem JavaScript zu befassen. Indem wir den Server zwingen, mit einem PersistedQueryNotFound-Fehler zu antworten, können wir die gesamte Abfragenutzlast erfassen und für Scraping-Zwecke verwenden. Durch die regelmäßige Ausführung der extrahierten Abfrage wird sichergestellt, dass der Scraper auch dann funktionsfähig bleibt, wenn der serverseitige Cache zurückgesetzt wird oder sich die Website weiterentwickelt.
Das obige ist der detaillierte Inhalt vonReverse Engineering der GraphQL-PersistedQuery-Erweiterung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



