


In früheren Artikeln haben wir etwas über DOM und CSSOM gelernt. Wenn Sie immer noch Zweifel an diesen beiden Wörtern haben, empfehle ich Ihnen, die beiden folgenden Beiträge zu lesen:
Um es noch einmal zusammenzufassen: Das DOM ist eine Struktur, die der Browser zum Rendern unserer Seite verwendet. Allerdings werden Internetdaten nicht in Form eines DOM übertragen, daher muss ein Prozess durchgeführt werden, bevor das DOM für die Nutzung durch den Browser bereit ist.
An diesem Punkt fragen Sie sich vielleicht, wie Daten im Internet übertragen werden?
Immer wenn wir auf eine Website zugreifen, findet ein Austausch in einem Muster statt, das wir Client x Server nennen.
Bei diesem Austausch fordert der Client (Ihr Browser) den Server auf, auf die Website www.cristiano.dev zuzugreifen, der mit dem gesamten Inhalt der angeforderten Website antwortet, dieser Inhalt kommt jedoch in Form von Bytes und in gewisser Weise Das ist weit entfernt von dem HTML/CSS/JS, das wir kennen.
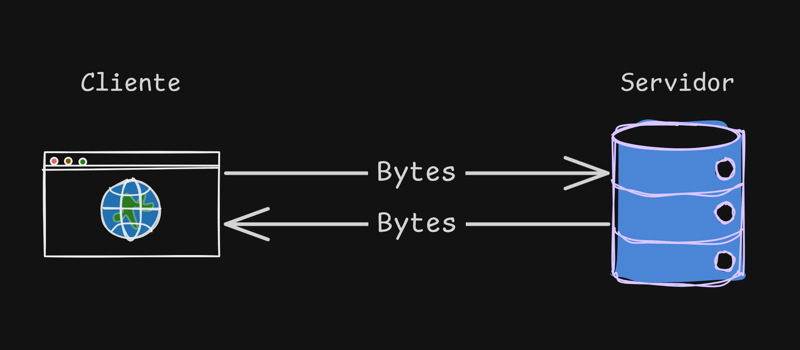
Was der Browser vom Server empfängt, ist eine Folge von Bytes.
Für diesen kleinen HTML-Ausschnitt, der vom Server bereitgestellt wird:
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>
Der Browser würde in Bytes etwa Folgendes erhalten:
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
Allerdings kann der Browser eine Seite nur mit diesen Informationen nicht rendern. Damit unser Layout zusammengestellt werden kann, führt der Browser einige Schritte aus, bevor er über das DOM verfügt.
Diese Schritte sind:

In diesem Schritt liest der Browser die Rohdaten aus dem Netzwerk oder einer Festplatte und wandelt sie basierend auf der in der Datei angegebenen Kodierung in Zeichen um, zum Beispiel UTF-8.
Im Grunde ist es der Schritt, bei dem der Browser Bytes in den Code in dem Format umwandelt, das wir in unserem täglichen Leben schreiben.

In diesem Stadium konvertiert der Browser Zeichenfolgen in kleine Einheiten, sogenannte Token. Jeder Anfang, jedes Ende des Tags und jeder Inhalt werden gezählt, außerdem hat jedes Token einen bestimmten Satz von Regeln.
Zum Beispiel ist das Tag hat andere Attribute als das
-TagOhne diesen Schritt haben wir nur eine Menge Text ohne Bedeutung für den Browser und am Ende dieses Prozesses würde unser Basis-HTML wie folgt tokenisiert:
➔ Token: StartTag, Name: p

Ein Token ist ein einzelnes Wort oder Symbol in einem Text. „Tokenisierung“ ist der Prozess der Aufteilung von Text in kleinere Wörter, Phrasen oder Symbole.

Der Lexing-Schritt (lexikalische Analyse) ist für die Konvertierung von Token in Objekte verantwortlich, aber dies ist noch nicht das DOM. In diesem Moment generiert der Browser isolierte Teile des DOM, wobei jedes Tag in ein Objekt mit Attributen umgewandelt wird, die Informationen zu Attributen, übergeordneten Tags, untergeordneten Tags usw. enthalten.
Das Ergebnis nach dem Lexen unseres Tags
Es würde ungefähr so aussehen:
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>

Wir haben endlich die Bauphase des DOM erreicht!
An diesem Punkt berücksichtigt der Browser die Beziehungen zwischen den HTML-Tags und fügt die Knoten zu einer Baumdatenstruktur zusammen, die diese Beziehungen hierarchisch darstellt. Beispiel: Das HTML-Objekt ist das übergeordnete Objekt des Body-Objekts, der Body ist das übergeordnete Objekt des Absatzobjekts, bis die gesamte Darstellung des Dokuments erstellt ist.
Am Ende der Konstruktion wird unser Beispiel-HTML zu einem Baum mit Objekten wie diesem:
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
Der Prozess zum Aufbau des DOM ist komplex und erfolgt in den folgenden Schritten:
Ein ähnlicher Prozess findet auch für CSSOM statt, bestehend aus Konvertierung, Tokenisierung und Lexing.
Sie fragen sich bestimmt, wo Sie dieses Wissen in Ihrer täglichen Entwicklung anwenden werden...
Es stimmt, dass diese Art von Informationen nicht häufig abgefragt wird, aber es ist wichtig zu verstehen, wie Browser, das wichtigste Frontend-Arbeitstool, im Wesentlichen funktionieren.
Dieses Wissen wird auch für das Verständnis der nächsten Themen, die wir hier behandeln werden, sehr wertvoll sein: Paint, Repaint, Flow und Reflow.
Danke, dass Sie hier sind!
Ich hoffe, Sie haben bei dieser Lektüre etwas Neues gelernt.
Bis zum nächsten Mal!
Aufbau des Objektmodells
Dekonstruktion des Webs: Seitenrendering
Das obige ist der detaillierte Inhalt vonRendering im Browser verstehen: Wie wird das DOM generiert?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Lösung für Sitzungsfehler
Lösung für Sitzungsfehler
 So stellen Sie den PPT-Breitbildmodus ein
So stellen Sie den PPT-Breitbildmodus ein
 Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
 Warum meldet vue.js einen Fehler?
Warum meldet vue.js einen Fehler?
 Was tun, wenn Ihre IP-Adresse angegriffen wird?
Was tun, wenn Ihre IP-Adresse angegriffen wird?
 Der Unterschied zwischen WeChat-Dienstkonto und offiziellem Konto
Der Unterschied zwischen WeChat-Dienstkonto und offiziellem Konto
 Eingang zur offiziellen msdn-Website
Eingang zur offiziellen msdn-Website
 Der Unterschied zwischen fprintf und printf
Der Unterschied zwischen fprintf und printf








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



