


Das Hochladen einer CSV-Datei in Django REST (insbesondere in einer atomaren Umgebung) ist eine einfache Aufgabe, hat mich aber verwirrt, bis ich einige Tricks herausgefunden habe, die ich mit Ihnen teilen möchte.
In diesem Artikel verwende ich Postman (anstelle eines Frontends) und erkläre auch, was Sie bei Postman für den Anforderungsversand über Bilder einstellen müssen.
Was wir uns wünschen
Methode
pip install pandas
Klicken Sie für die Wertzelle auf die Schaltfläche „Dateien auswählen“ und laden Sie die CSV-Datei hoch. Schauen Sie sich den Screenshot unten an

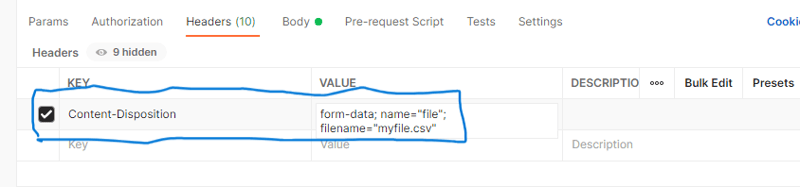
Stellen Sie unter „Headers“ Content-Disposition und den Wert auf „form-data“ ein. name="Datei"; Dateiname="Ihr_Dateiname.csv". Ersetzen Sie your_file_name.csv durch Ihren tatsächlichen Dateinamen. Schauen Sie sich den Screenshot unten an.
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
Erklärung des obigen Codes:
Der Code beginnt mit dem Importieren notwendiger Pakete, dem Definieren einer klassenbasierten Ansicht und dem Festlegen einer Parser-Klasse (FileUploadParser). Der erste Teil der Post-Methode in der Klasse versucht, die Datei von request.FILES abzurufen und ihre Verfügbarkeit zu überprüfen.
Anschließend überprüft eine kleine Validierung, ob es sich um eine CSV-Datei handelt, indem die Erweiterung überprüft wird.
Der nächste Teil lädt es in einen Pandas-Datenrahmen (ähnlich einer Tabellenkalkulation):
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
Ich werde einige der an die Ladefunktion übergebenen Argumente erläutern:
Skiprows
Beim Lesen der geladenen CSV-Datei ist zu beachten, dass die CSV-Datei in diesem Fall über ein Netzwerk übertragen wird, sodass einige Metadaten wie Dinge am Anfang und Ende der Datei hinzugefügt werden. Diese Dinge können ärgerlich sein und liegen nicht im CSV-Format (Comma Separated Value) vor, sodass sie beim Parsen tatsächlich zu Fehlern führen können. Dies erklärt, warum ich „skiprows=3“ verwendet habe, um die ersten drei Zeilen mit Metadaten und Header zu überspringen und direkt im Hauptteil der CSV-Datei zu landen. Wenn Sie Skiprows entfernen oder eine geringere Zahl verwenden, erhalten Sie möglicherweise eine Fehlermeldung wie: Fehler bei der Tokenisierung der Daten. C-Fehler, sonst bemerken Sie möglicherweise, dass die Daten ab der Kopfzeile beginnen.
dtype=str
Pandas erweist sich gerne als schlau, wenn es darum geht, den Datentyp bestimmter Spalten zu erraten. Ich wollte alle Werte als String haben, also habe ich dtype=str
Trennzeichen
Gibt an, wie die Zellen getrennt werden. Der Standardwert ist normalerweise Komma.
iloc[:-1]
Ich musste iloc verwenden, um den Datenrahmen aufzuteilen und die Metadaten am Ende des df zu entfernen.
Dann konvertiert die nächste Zeile df = df.where(pd.notnull(df), None) alle NaN-Werte in None. NaNi ist ein Ersatzwert, den Pandas verwendet, um None darzustellen.
Der nächste Block ist etwas knifflig. Wir durchlaufen jede Zeile im Datenrahmen, instanziieren die Zeilendaten mit dem BiodataModel, führen eine Validierung auf Modellebene (nicht auf Serialisierungsebene) mit der Methode full_clean() durch, da die Massenerstellung die Django-Validierung umgeht, und fügen dann unsere Erstellungsvorgänge einer Liste mit dem Namen „ bulk_data. Ja, hinzufügen noch nicht ausgeführt! Denken Sie daran, dass wir versuchen, eine atomare Operation (auf Batch-Ebene) durchzuführen, also wollen wir „all“ oder „None“. Das einzelne Speichern von Zeilen führt nicht zu einem All-oder-Keine-Verhalten.
Dann zum letzten wichtigen Teil. Innerhalb eines Transaction.atomic()-Blocks (der alles oder kein Verhalten bereitstellt) führen wir BiodataModel.objects.bulk_create(bulk_data) aus, um alle Zeilen auf einmal zu speichern.
Noch etwas. Beachten Sie die Indexvariable und den Except-Block in der for-Schleife. In der Ausnahmeblock-Fehlermeldung habe ich 2 zur von df.iterrows() abgeleiteten Indexvariablen hinzugefügt, da der Wert bei Betrachtung in einer Excel-Datei nicht genau mit der Zeile übereinstimmte, in der er sich befand. Der Ausnahmeblock fängt jeden Fehler ab und erstellt beim Öffnen in Excel eine Fehlermeldung mit der genauen Zeilennummer, sodass der Uploader die Zeile in der Excel-Datei leicht finden kann!
Danke fürs Lesen!!!
VERSIONEN DER VERWENDETEN WERKZEUGE
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
Das obige ist der detaillierte Inhalt vonSO LADEN SIE EINE CSV-DATEI AUF DJANGO REST HOCH. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Eine vollständige Liste der Tastenkombinationen für Ideen
Eine vollständige Liste der Tastenkombinationen für Ideen
 So erstellen Sie einen Index in Word
So erstellen Sie einen Index in Word
 ps ausgewählten Bereich löschen
ps ausgewählten Bereich löschen
 Welche Größe hat A5-Papier?
Welche Größe hat A5-Papier?
 Lösung für fehlende xlive.dll
Lösung für fehlende xlive.dll
 Methode zum Öffnen der Bereichsberechtigung
Methode zum Öffnen der Bereichsberechtigung
 Lösung für Socket-Fehler 10054
Lösung für Socket-Fehler 10054
 Verwendung der C-Sprache printf-Funktion
Verwendung der C-Sprache printf-Funktion








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



