


In den letzten Jahren hat die Transformer-Architektur große Erfolge erzielt und auch eine Vielzahl von Varianten hervorgebracht, beispielsweise Vision Transformer (ViT), der sich gut für die Verarbeitung visueller Aufgaben eignet. Der in diesem Artikel vorgestellte Body Transformer (BoT) ist eine Transformer-Variante, die sich sehr gut für das Erlernen von Roboterstrategien eignet.
Wir wissen, dass ein physischer Agent, wenn er eine Korrektur und Stabilisierung von Handlungen durchführt, oft eine räumliche Reaktion auslöst, die auf der Position des externen Reizes basiert, den er spürt. Beispielsweise befinden sich die menschlichen Reaktionsschaltkreise auf diese Reize auf der Ebene der neuronalen Schaltkreise der Wirbelsäule und sind speziell für die Reaktion eines einzelnen Aktors verantwortlich. Die korrigierende lokale Ausführung ist ein wesentlicher Faktor für effiziente Bewegungen, was auch für Roboter besonders wichtig ist.
Aber bisherige Lernarchitekturen stellten in der Regel nicht die räumliche Korrelation zwischen Sensoren und Aktoren her. Da Roboterstrategien Architekturen verwenden, die größtenteils für natürliche Sprache und Computer Vision entwickelt wurden, gelingt es ihnen oft nicht, die Struktur des Roboterkörpers effektiv auszunutzen.
Allerdings hat Transformer in dieser Hinsicht noch großes Potenzial. Studien haben gezeigt, dass Transformer lange Sequenzabhängigkeiten effektiv bewältigen und große Datenmengen problemlos aufnehmen kann. Die Transformer-Architektur wurde ursprünglich für unstrukturierte NLP-Aufgaben (Natural Language Processing) entwickelt. Bei diesen Aufgaben (z. B. Sprachübersetzung) wird die Eingabesequenz normalerweise einer Ausgabesequenz zugeordnet.
Basierend auf dieser Beobachtung schlug ein Team unter der Leitung von Professor Pieter Abbeel von der University of California in Berkeley den Body Transformer (BoT) vor, der die räumliche Position von Sensoren und Aktoren am Roboterkörper berücksichtigt.

Papiertitel: Body Transformer: Leveraging Robot Embodiment for Policy Learning
Papieradresse: https://arxiv.org/pdf/2408.06316v1
Projektwebsite: https://sferrazza .cc/bot_site
Codeadresse: https://github.com/carlosferrazza/BodyTransformer
Konkret modelliert BoT den Roboterkörper in einem Diagramm, in dem die Knoten seine Sensoren und Aktoren sind. Anschließend wird eine äußerst spärliche Maske auf der Aufmerksamkeitsschicht verwendet, um zu verhindern, dass jeder Knoten auf andere Teile als seine unmittelbaren Nachbarn achtet. Durch die Verbindung mehrerer strukturell identischer BoT-Schichten werden Informationen aus dem gesamten Diagramm zusammengeführt, ohne die Darstellungsmöglichkeiten der Architektur zu beeinträchtigen. BoT schneidet sowohl beim Nachahmungslernen als auch beim Verstärkungslernen gut ab und wird von manchen sogar als „Game Changer“ des Strategielernens angesehen.
Body Transformer
Wenn die Roboter-Lernstrategie die ursprüngliche Transformer-Architektur als Rückgrat verwendet, werden die nützlichen Informationen, die die Roboterkörperstruktur bereitstellt, normalerweise ignoriert. Tatsächlich können diese Strukturinformationen jedoch eine stärkere induktive Vorspannung für Transformer liefern. Das Team nutzte diese Informationen und behielt gleichzeitig die Darstellungsfähigkeiten der ursprünglichen Architektur bei.
Die Body Transformer (BoT)-Architektur basiert auf maskierter Aufmerksamkeit. Auf jeder Ebene dieser Architektur kann ein Knoten nur Informationen über sich selbst und seine unmittelbaren Nachbarn sehen. Auf diese Weise fließen Informationen entsprechend der Struktur des Diagramms, wobei vorgelagerte Schichten Rückschlüsse auf der Grundlage lokaler Informationen ziehen und nachgelagerte Schichten globalere Informationen von weiter entfernten Knoten sammeln.
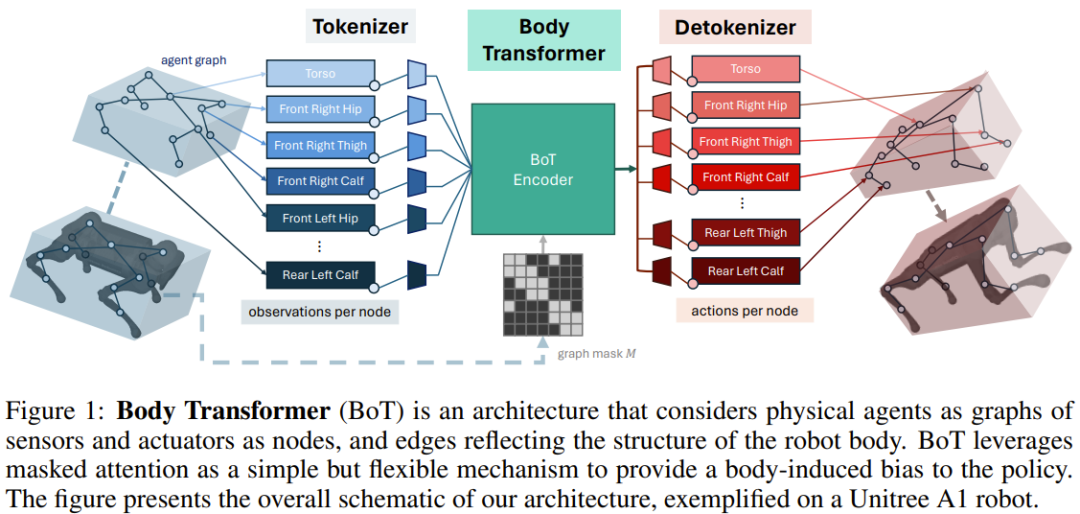
Wie in Abbildung 1 dargestellt, enthält die BoT-Architektur die folgenden Komponenten:
1.Tokenizer: projiziert die Sensoreingabe in die entsprechende Knoteneinbettung;
2.Transformer-Encoder: verarbeitet die Eingabeeinbettung und generiert eine Ausgabe von die gleiche Dimension Features;
3.detokenizer: Detokenisierung, d.
Tokenizer
Das Team entschied sich dafür, Beobachtungsvektoren in Diagrammen abzubilden, die aus lokalen Beobachtungen bestehen.
In der Praxis weisen sie den Wurzelelementen des Roboterkörpers globale Größen und den Knoten, die die entsprechenden Gliedmaßen darstellen, lokale Größen zu. Diese Zuordnung ähnelt der vorherigen GNN-Methode.
Verwenden Sie dann eine lineare Ebene, um den lokalen Zustandsvektor in einen Einbettungsvektor zu projizieren. Der Zustand jedes Knotens wird in seine knotenspezifische lernbare lineare Projektion eingespeist, was zu einer Folge von n Einbettungen führt, wobei n die Anzahl der Knoten (oder die Sequenzlänge) darstellt. Dies unterscheidet sich von früheren Arbeiten, die normalerweise nur eine einzige gemeinsame lernbare lineare Projektion verwenden, um unterschiedliche Anzahlen von Knoten beim verstärkenden Lernen mit mehreren Aufgaben zu verarbeiten.
BoT-Encoder
Das vom Team verwendete Backbone-Netzwerk ist ein standardmäßiger mehrschichtiger Transformer-Encoder, und es gibt zwei Varianten dieser Architektur:
BoT-Hard: Maskieren Sie jede Ebene mit einer binären Maske, die die Struktur des Diagramms widerspiegelt. Insbesondere ist die Art und Weise, wie sie die Maske konstruieren, M = I_n + A, wobei I_n die n-dimensionale Identitätsmatrix und A die dem Diagramm entsprechende Adjazenzmatrix ist. Abbildung 2 zeigt ein Beispiel. Dies ermöglicht es jedem Knoten, nur sich selbst und seine unmittelbaren Nachbarn zu sehen, und kann zu einer erheblichen Sparsität des Problems führen – was aus Sicht der Rechenkosten besonders attraktiv ist.
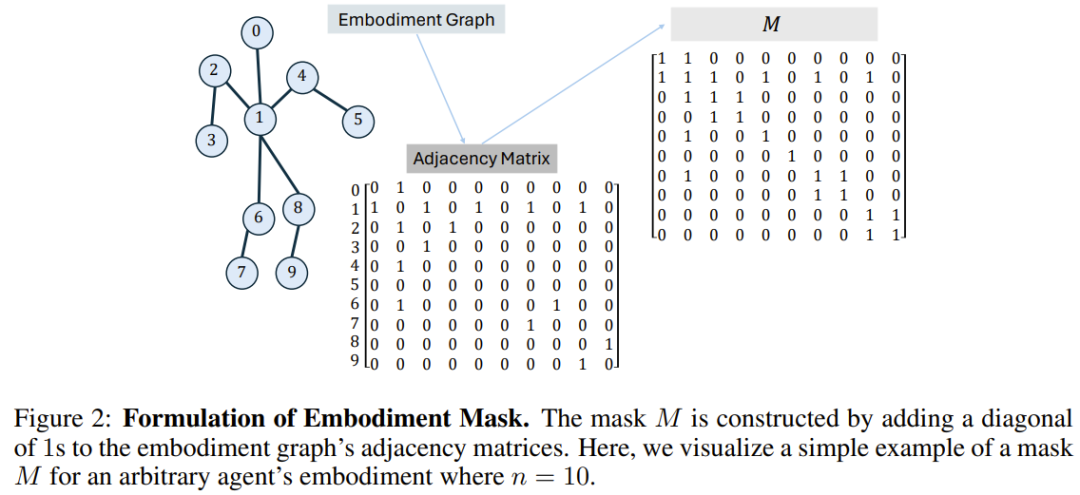
BoT-Mix: verwebt Schichten mit maskierter Aufmerksamkeit (wie BoT-Hard) mit Schichten mit unmaskierter Aufmerksamkeit.
Detokenizer
Transformer Die vom Encoder ausgegebenen Merkmale werden der linearen Ebene zugeführt und dann in Aktionen projiziert, die dem Glied des Knotens zugeordnet sind. Diese Aktionen werden basierend auf der Nähe des entsprechenden Aktors zum Glied zugewiesen . Auch hier sind diese lernbaren linearen Projektionsebenen für jeden Knoten separat. Wenn BoT als kritische Architektur in einer Umgebung des verstärkenden Lernens verwendet wird, gibt der Detokenizer keine Aktionen, sondern Werte aus, die dann über Körperteile gemittelt werden.
Experimente
Das Team bewertete die Leistung von BoT in Nachahmungs- und Verstärkungslernumgebungen. Sie behielten die gleiche Struktur wie in Abbildung 1 bei und ersetzten lediglich den BoT-Encoder durch verschiedene Basisarchitekturen, um die Wirksamkeit des Encoders zu bestimmen.
Ziel dieser Experimente ist es, die folgenden Fragen zu beantworten:
Kann maskierte Aufmerksamkeit die Leistung und Generalisierungsfähigkeit des Nachahmungslernens verbessern?
Kann BoT im Vergleich zur ursprünglichen Transformer-Architektur einen positiven Skalierungstrend aufweisen?
Ist BoT mit Reinforcement-Learning-Frameworks kompatibel und welche sinnvollen Designoptionen gibt es, um die Leistung zu maximieren?
Können BoT-Strategien auf reale Roboteraufgaben angewendet werden?
Was sind die rechnerischen Vorteile der maskierten Aufmerksamkeit?
Imitation Learning Experiment
Das Team bewertete die Imitationslernleistung der BoT-Architektur bei der Körperverfolgungsaufgabe, die durch den MoCapAct-Datensatz definiert wurde.
Die Ergebnisse sind in Abbildung 3a dargestellt und es ist ersichtlich, dass BoT immer eine bessere Leistung erbringt als die MLP- und Transformer-Basislinien. Es ist erwähnenswert, dass die Vorteile von BoT gegenüber diesen Architekturen bei bisher unbekannten Verifizierungsvideos noch zunehmen werden, was beweist, dass eine körperbewusste induktive Verzerrung zu verbesserten Generalisierungsfähigkeiten führen kann.
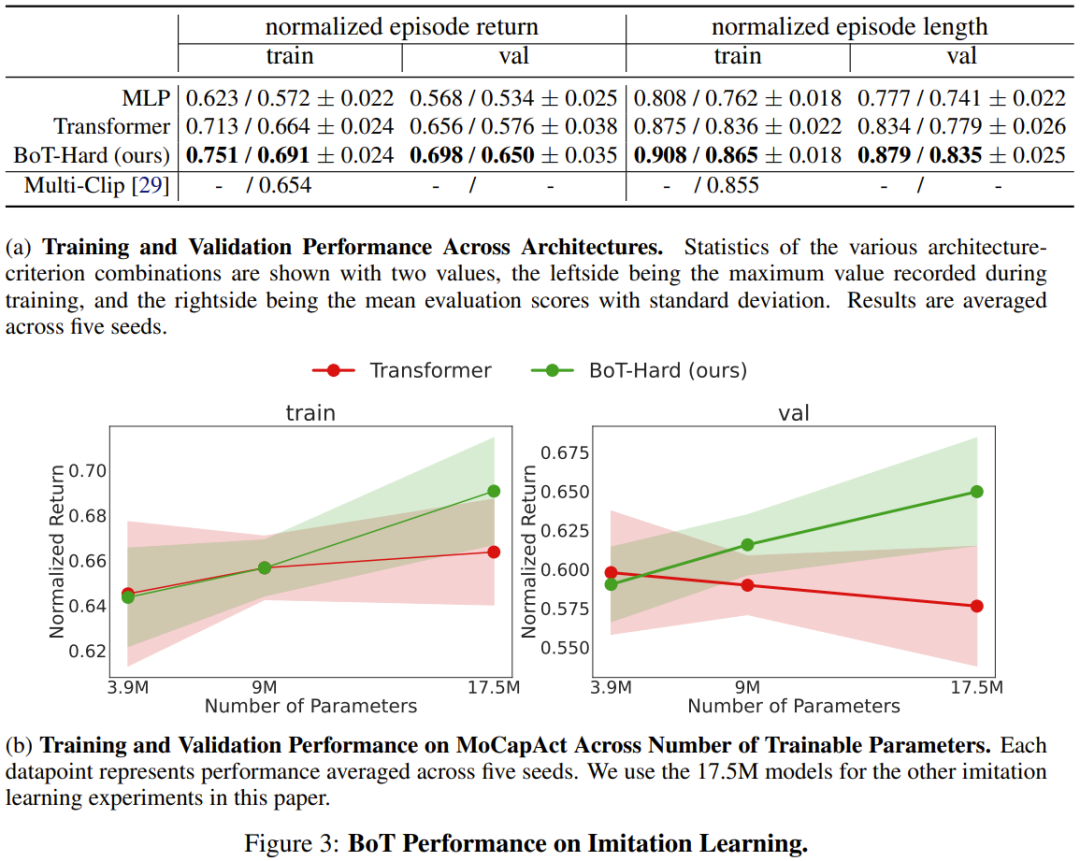
Und Abbildung 3b zeigt, dass BoT-Hard im Vergleich zur Transformer-Basislinie eine gute Skalierbarkeit aufweist. Seine Leistung steigt sowohl bei Trainings- als auch bei Verifizierungsvideoclips, wenn die Anzahl der trainierbaren Parameter zunimmt, was weiter zeigt, dass BoT-Hard dazu tendiert Überanpassung der Trainingsdaten, und diese Überanpassung wird durch Verkörperungsfehler verursacht. Weitere experimentelle Beispiele werden unten gezeigt, Einzelheiten finden Sie im Originalpapier.


Reinforcement Learning Experiment
Das Team bewertete die Reinforcement-Learning-Leistung von BoT bei 4 Robotersteuerungsaufgaben im Isaac Gym im Vergleich zu einer Basislinie mit PPO. Die 4 Aufgaben sind: Humanoid-Mod, Humanoid-Board, Humanoid-Hill und A1-Walk.
Abbildung 5 zeigt die durchschnittlichen Diagrammerträge der Evaluierungseinführung während des Trainings für MLP, Transformer und BoT (Hard und Mix). wobei die durchgezogene Linie dem Mittelwert und der schattierte Bereich dem Standardfehler der fünf Samen entspricht.
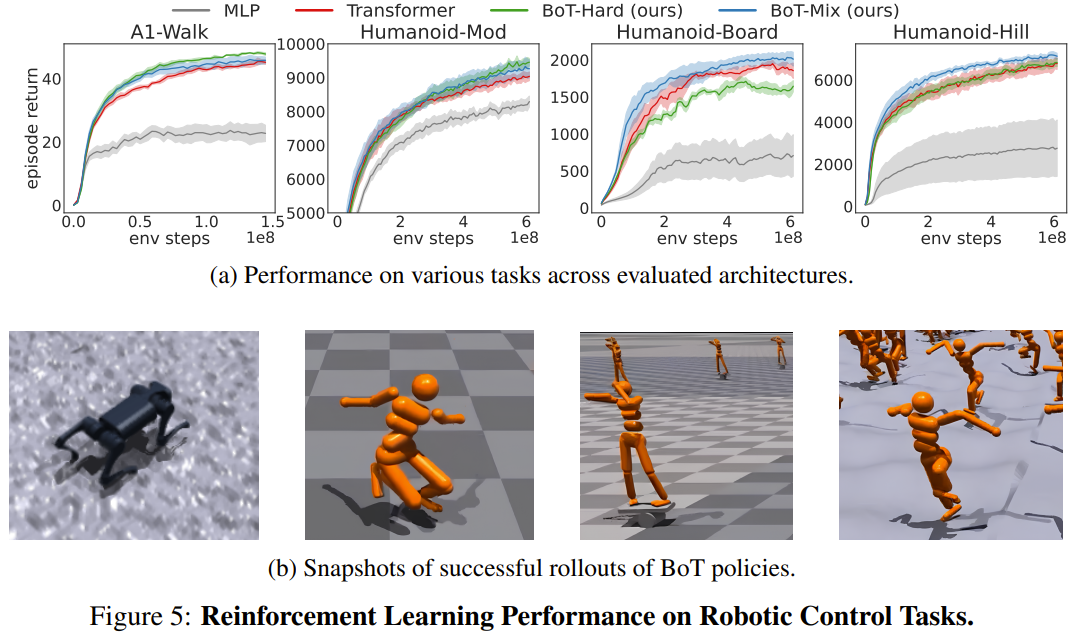

Die Ergebnisse zeigen, dass BoT-Mix die MLP- und ursprünglichen Transformer-Basislinien in Bezug auf Probeneffizienz und asymptotische Leistung durchweg übertrifft. Dies verdeutlicht den Nutzen der Integration von Vorurteilen aus dem Roboterkörper in die Architektur des Richtliniennetzwerks.
Mittlerweile schneidet BoT-Hard bei einfacheren Aufgaben (A1-Walk und Humanoid-Mod) besser ab als der ursprüngliche Transformer, schneidet jedoch bei schwierigeren Erkundungsaufgaben (Humanoid-Board und Humanoid-Hill) schlechter ab. Angesichts der Tatsache, dass maskierte Aufmerksamkeit die Ausbreitung von Informationen aus entfernten Körperteilen behindert, können die starken Einschränkungen von BoT-Hard bei der Informationskommunikation die Effizienz der Erforschung des verstärkenden Lernens beeinträchtigen.
Realwelt-Experiment
Persekitaran sukan simulasi Isaac Gym sering digunakan untuk memindahkan strategi pembelajaran pengukuhan daripada persekitaran maya kepada persekitaran sebenar tanpa memerlukan pelarasan dunia sebenar. Untuk mengesahkan sama ada seni bina yang baru dicadangkan sesuai untuk aplikasi dunia sebenar, pasukan itu menggunakan dasar BoT yang dilatih di atas kepada robot Unitree A1. Seperti yang anda boleh lihat daripada video di bawah, seni bina baharu boleh digunakan dengan pasti dalam penggunaan dunia sebenar.

Analisis Pengiraan
Pasukan juga menganalisis kos pengiraan seni bina baharu, seperti ditunjukkan dalam Rajah 6. Keputusan penskalaan perhatian bertopeng yang baru dicadangkan dan perhatian konvensional pada panjang jujukan yang berbeza (bilangan nod) diberikan di sini.
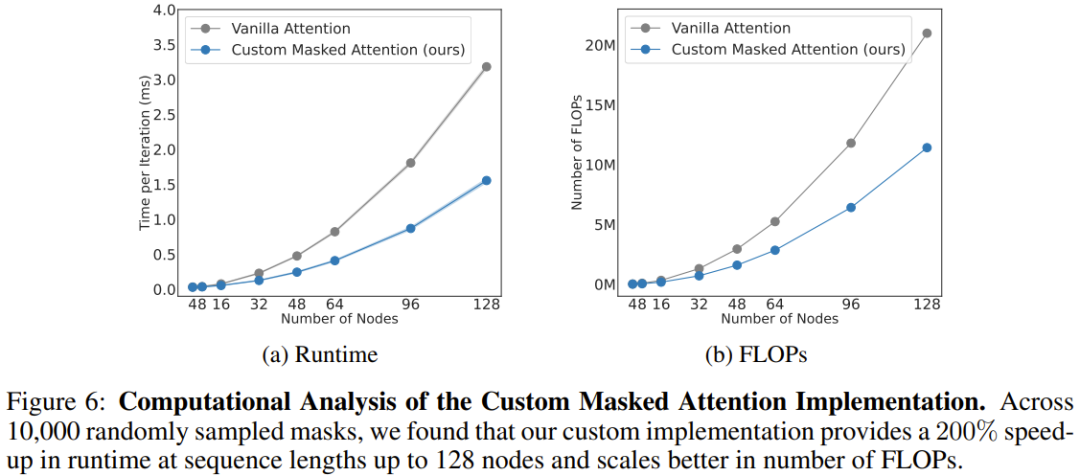
Dapat dilihat apabila terdapat 128 nod (bersamaan dengan robot humanoid dengan lengan yang tangkas), perhatian baru boleh meningkatkan kelajuan sebanyak 206%.
Secara keseluruhannya, ini menunjukkan bahawa berat sebelah terbitan badan dalam seni bina BoT bukan sahaja meningkatkan prestasi keseluruhan ejen fizikal, tetapi juga mendapat manfaat daripada penyamaran secara semula jadi jarang dari seni bina. Kaedah ini boleh mengurangkan masa latihan algoritma pembelajaran dengan ketara melalui selari yang mencukupi.
Das obige ist der detaillierte Inhalt vonGame Changer für das Erlernen von Roboterstrategien? Berkeley schlägt Body Transformer vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































