


Der Aufstieg kleiner Modelle.
Letzten Monat veröffentlichte Meta die Modellreihe Llama 3.1, zu der Metas bislang größtes Modell, der 405B, sowie zwei kleinere Modelle gehören. Die Parameterbeträge betragen 70 Milliarden bzw. 8 Milliarden.
Llama 3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen.
Daher hat sich in der Branche ein weiterer Trend herausgebildet, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig bereitzustellen sind.
Kürzlich zeigen Untersuchungen von NVIDIA, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. # ##### ## ## ## ## #, Meta-Chef-KI-Wissenschaftler Jann LECun lobte die Studie ebenfalls.

Llama-3.1-Minitron 4B übertrifft modernste Open-Source-Modelle ähnlicher Größe, darunter Minitron 4B, Phi-2 2.7B, Gemma2 2.6B und Qwen2-1.5B.
Das entsprechende Papier dieser Forschung wurde bereits letzten Monat veröffentlicht.

Papierlink: https://www.arxiv.org/pdf/2407.14679
# ?? #
.
Es ist zu beachten, dass Sie vor dem Beschneiden des Modells verstehen müssen, welcher Teil des Modells wichtig ist. NVIDIA schlägt eine aktivierungsbasierte Strategie zur reinen Wichtigkeitsbewertung vor, die gleichzeitig Informationen in allen relevanten Dimensionen (Tiefe, Neuron, Kopf und Einbettungskanäle) berechnet und dabei einen kleinen Kalibrierungsdatensatz von 1024 Proben verwendet und nur eine Vorwärtsausbreitung erforderlich ist. Dieser Ansatz ist einfacher und kostengünstiger als Strategien, die auf Gradienteninformationen basieren und eine Backpropagation erfordern.
Während des Beschneidens können Sie iterativ zwischen Beschneiden und Wichtigkeitsschätzung für eine bestimmte Achse oder Achsenkombination wechseln. Empirische Studien zeigen, dass die Verwendung einer einzelnen Wichtigkeitsschätzung ausreichend ist und dass iterative Schätzungen keinen zusätzlichen Nutzen bringen.
Umschulung mittels klassischer WissensdestillationAbbildung 2 unten zeigt den Destillationsprozess, bei dem das N-Schicht-Schülermodell (das beschnittene Modell) aus dem M-Schicht-Lehrermodell (dem ursprünglichen unbeschnittenen Modell) destilliert wird. Das Schülermodell wird durch Minimierung einer Kombination aus Einbettungsausgangsverlusten, Logit-Verlusten und Transformer-Encoder-spezifischen Verlusten erlernt, die den Schülerblöcken S und den Lehrerblöcken T zugeordnet sind. Abbildung 2: Verlust des Destillationstrainings.

Best Practices für Pruning und DestillationBasierend auf umfangreicher Ablationsforschung zu Pruning und Wissensdestillation in kompakten Sprachmodellen fasst NVIDIA seine Lernergebnisse in den folgenden strukturierten Best Practices für die Komprimierung zusammen.
Eine besteht darin, die Größe anzupassen.Um eine Reihe von LLMs zu trainieren, trainieren Sie zuerst das größte und beschneiden und destillieren Sie es dann iterativ, um kleinere LLMs zu erhalten. Wenn Sie zum Trainieren des größten Modells eine mehrstufige Trainingsstrategie verwenden, ist es am besten, das in der letzten Trainingsphase erhaltene Modell zu beschneiden und neu zu trainieren.
Lehrer-Feinabstimmung Nur tiefe Beschneidung
Nur Tiefenbeschneidung
Um von 8B auf 4B zu reduzieren, hat NVIDIA 16 Ebenen (50 %) beschnitten. Sie bewerten zunächst die Bedeutung jeder Schicht oder Gruppe aufeinanderfolgender Unterschichten, indem sie sie aus dem Modell entfernen, und beobachten einen Anstieg des LM-Verlusts oder eine Abnahme der Genauigkeit bei nachgelagerten Aufgaben. Abbildung 5 unten zeigt die LM-Verlustwerte im Validierungssatz nach dem Entfernen von 1, 2, 8 oder 16 Schichten. Das rote Diagramm für Schicht 16 zeigt beispielsweise den LM-Verlust an, der auftritt, wenn die ersten 16 Schichten entfernt werden. Schicht 17 zeigt an, dass ein LM-Verlust auch auftritt, wenn die erste Schicht beibehalten wird und die Schichten 2 bis 17 gelöscht werden. Nvidia stellt fest: Die Start- und Endschicht sind die wichtigsten.
Abbildung 5: Die Bedeutung des reinen Tiefenschnitts der Mittelschicht.
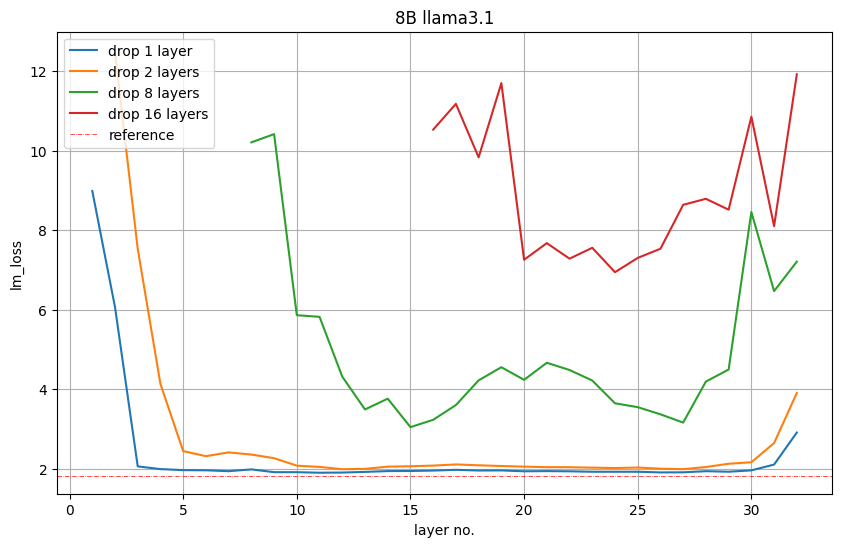
Abbildung 6 unten zeigt die Winogrande-Genauigkeit jedes beschnittenen Modells. Sie zeigt, dass es am besten ist, die 16. bis 31. Schicht zu löschen, wobei die 31. Schicht die vorletzte Schicht ist. Die 5-Schuss-Genauigkeit des beschnittenen Modells ist deutlich höher. mit zufälliger Genauigkeit (0,5). Nvidia nutzte diese Erkenntnis und entfernte die Schichten 16 bis 31. Abbildung 6: Genauigkeit der Winogrande-Aufgabe, wenn 16 Schichten entfernt werden.
Nur Breitenbeschneidung
NVIDIA beschneidet die Einbettung (versteckt) und die MLP-Zwischenabmessungen entlang der Breitenachse, um Llama 3.1 8B zu komprimieren. Insbesondere verwenden sie die zuvor beschriebene aktivierungsbasierte Strategie, um Wichtigkeitswerte für jeden Aufmerksamkeitskopf, jeden Einbettungskanal und jede versteckte MLP-Dimension zu berechnen. Nach der Wichtigkeitsschätzung entschied sich NVIDIA
Nach der Wichtigkeitsschätzung entschied sich NVIDIA
, die MLP-Mitteldimension von 14336 auf 9216 zu beschneiden.
Versteckte Größe von 4096 auf 3072 reduzieren.
Achten Sie erneut auf die Anzahl der Köpfe und Schichten.
Es ist erwähnenswert, dass nach dem Einzelprobenschnitt der LM-Verlust beim Breitenschnitt höher ist als beim Tiefenschnitt. Nach einer kurzen Umschulungsphase kehrte sich der Trend jedoch um.
Genauigkeitsbenchmark
NVIDIA hat das Modell anhand der folgenden Parameter destilliert:
Spitzenlernrate = 1e-4
Minimale Lernrate = 1e-5
40 Schritte linear

Tabelle 1: Genauigkeitsvergleich des Minitron 4B-Basismodells im Vergleich zu Basismodellen ähnlicher Größe.
Um zu überprüfen, ob das destillierte Modell zu einem leistungsstarken Befehlsmodell werden kann, hat NVIDIA NeMo-Aligner zur Feinabstimmung des Llama-3.1-Minitron 4B-Modells verwendet. Sie verwendeten Nemotron-4 340B-Trainingsdaten und werteten sie auf IFEval, MT-Bench, ChatRAG-Bench und dem Berkeley Function Calling Leaderboard (BFCL) aus, um Anweisungen zu befolgen, Rollenspiele, RAG und Funktionsaufruffähigkeiten zu testen. Schließlich wurde bestätigt, dass das Modell Llama-3.1-Minitron 4B ein zuverlässiges Unterrichtsmodell sein kann, das andere Basis-SLMs übertrifft.
Tabelle 2: Accurac Y-Vergleich des ausgerichteten Minitron 4B-Basismodells mit ausgerichteten Modellen ähnlicher Größe.
Leistungsbenchmarks
NVIDIA optimierte die Modelle Llama 3.1 8B und Llama-3.1-Minitron 4B mit NVIDIA TensorRT-LLM, einem Open-Source-Toolkit zur Optimierung der LLM-Inferenz. Die nächsten beiden Abbildungen zeigen die Durchsatzanforderungen pro Sekunde verschiedener Modelle bei FP8- und FP16-Präzision unter verschiedenen Anwendungsfällen, ausgedrückt als Kombination aus Eingabesequenzlänge und Ausgabesequenzlänge (ISL/OSL) der Stapelgröße von 32 für 8B Modell und Die Stapelgröße des 4B-Modells ist eine Kombination aus Eingabesequenzlänge und Ausgabesequenzlänge (ISL/OSL) von 64, da die kleineren Gewichte eine größere Stapelgröße auf einer NVIDIA H100 80-GB-GPU ermöglichen. Die Llama-3.1-Minitron-4B-Depth-Base-Variante ist die schnellste mit einem durchschnittlichen Durchsatz, der etwa 2,7-mal so hoch ist wie der von Llama 3.1 8B, während die Llama-3.1-Minitron-4B-Width-Base-Variante einen durchschnittlichen Durchsatz aufweist Der Durchsatz ist etwa 1,8-mal so hoch wie der von Llama 3.1 8B. Der Einsatz im FP8 verbessert außerdem die Leistung aller drei Modelle um etwa das 1,3-fache im Vergleich zu BF16.

80 GB GPU.
Fazit
Beschneidung und klassische Wissensverfeinerung sind eine sehr kostengünstige Methode, um schrittweise LLMs kleinerer Größe zu erhalten und in allen Bereichen eine höhere Genauigkeit zu erzielen als das Training von Grund auf. Dies ist ein effizienterer und dateneffizienterer Ansatz als die Feinabstimmung synthetischer Daten oder das Vortraining von Grund auf. Llama-3.1-Minitron 4B ist NVIDIAs erster Versuch, die hochmoderne Open-Source-Llama-3.1-Serie zu nutzen. Informationen zur Verwendung der SDG-Feinabstimmung von Llama-3.1 mit NVIDIA NeMo finden Sie im Abschnitt /sdg-law-title-generation auf GitHub. Weitere Informationen finden Sie in den folgenden Ressourcen:Referenzlinks:
https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b -Modell/
Das obige ist der detaillierte Inhalt vonNvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Die Hauptfunktion der Recheneinheit in einem Mikrocomputer besteht darin, auszuführen
Die Hauptfunktion der Recheneinheit in einem Mikrocomputer besteht darin, auszuführen So fangen Sie belästigende Anrufe ab
So fangen Sie belästigende Anrufe ab Ethereum-Browser fragt digitale Währung ab
Ethereum-Browser fragt digitale Währung ab 0x80070057 Fehlerlösung
0x80070057 Fehlerlösung Einführung in CLI-Befehle
Einführung in CLI-Befehle CSS-Bildlaufleistenstil
CSS-Bildlaufleistenstil HTML-Webseitenproduktion
HTML-Webseitenproduktion Die diagonale Kopfzeile von Excel ist zweigeteilt
Die diagonale Kopfzeile von Excel ist zweigeteilt
























