


Die Messung der Ausführungszeit von Anfragen an externe Dienste ist für die Leistungsüberwachung und -optimierung von entscheidender Bedeutung. Wenn jedoch Verbindungen zu diesen externen Diensten gepoolt werden, messen Sie möglicherweise versehentlich mehr als nur die Anforderungszeit. Insbesondere wenn Anfragen zu lange dauern und Ihnen die verfügbaren Verbindungen ausgehen, beginnt Ihre benutzerdefinierte Logik möglicherweise damit, die Wartezeit für den Erhalt einer Verbindung aus dem Pool einzubeziehen. Dies kann zu irreführenden Messwerten führen, die dazu führen, dass Sie die Leistung Ihres Systems falsch interpretieren. Lassen Sie uns untersuchen, wie dies geschieht und wie Sie vermeiden können, sich von Ihren eigenen Kennzahlen täuschen zu lassen.
Wenn alle Verbindungen im Pool verwendet werden, müssen zusätzliche Anfragen warten, bis eine Verbindung verfügbar wird. Diese Wartezeit kann Ihre Kennzahlen verzerren, wenn sie nicht getrennt von der tatsächlichen Anfragezeit gemessen wird.
Wenn Ihre benutzerdefinierte Logik die Gesamtzeit von der Anfrage bis zum Eingang einer Antwort misst, berücksichtigen Sie sowohl die Wartezeit als auch die Anfragezeit.
Um zu veranschaulichen, wie Sie sich in einer Umgebung mit Verbindungspools von Ihren eigenen Metriken täuschen lassen können, gehen wir ein praktisches Beispiel mit Spring Boot und Apache HttpClient 5 durch. Wir richten eine einfache Spring Boot-Anwendung ein, die HTTP-Anfragen an eine externe Adresse sendet Service, messen Sie die Ausführungszeit dieser Anfragen und zeigen Sie, wie die Erschöpfung des Verbindungspools zu irreführenden Metriken führen kann.
Um Verzögerungen im externen Dienst zu simulieren, verwenden wir das httpbin Docker-Image. Httpbin bietet einen benutzerfreundlichen HTTP-Anfrage- und Antwortdienst, mit dem wir künstliche Verzögerungen bei unseren Anfragen erzeugen können.
@SpringBootApplication @RestController public class Server { public static void main(String... args) { SpringApplication.run(Server.class, args); } class TimeClientHttpRequestInterceptor implements ClientHttpRequestInterceptor { @Override public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException { var t0 = System.currentTimeMillis(); try { return execution.execute(request, body); } finally { System.out.println("Request took: " + (System.currentTimeMillis() - t0) + "ms"); } } } @Bean public RestClient restClient() { var connectionManager = new PoolingHttpClientConnectionManager(); connectionManager.setMaxTotal(2); // Max number of connections in the pool connectionManager.setDefaultMaxPerRoute(2); // Max number of connections per route return RestClient.builder()// .requestFactory(new HttpComponentsClientHttpRequestFactory( HttpClients.custom().setConnectionManager(connectionManager).build())) .baseUrl("http://localhost:9091")// .requestInterceptor(new TimeClientHttpRequestInterceptor()).build(); } @GetMapping("/") String hello() { return restClient().get().uri("/delay/2").retrieve().body(String.class); } }
Im obigen Code haben wir einen Anfrage-Interceptor (ClientHttpRequestInterceptor) erstellt, um zu messen, was unserer Meinung nach die Ausführungszeit von Anfragen an den externen Dienst sein würde, der von httpbin unterstützt wird.
Wir haben den Pool außerdem explizit auf eine sehr kleine Größe von 2 Verbindungen eingestellt, um die Reproduktion des Problems zu erleichtern.
Jetzt müssen wir nur noch httpbin starten, unsere Spring-Boot-App ausführen und einen einfachen Test mit ab durchführen
$ docker run -p 9091:80 kennethreitz/httpbin
ab -n 10 -c 4 http://localhost:8080/ ... Percentage of the requests served within a certain time (ms) 50% 4049 66% 4054 75% 4055 80% 4055 90% 4057 95% 4057 98% 4057 99% 4057 100% 4057 (longest request)
Request took: 2021ms Request took: 2016ms Request took: 2022ms Request took: 4040ms Request took: 4047ms Request took: 4030ms Request took: 4037ms Request took: 4043ms Request took: 4050ms Request took: 4034ms
Wenn wir uns die Zahlen ansehen, können wir erkennen, dass wir, obwohl wir eine künstliche Verzögerung von 2 Sekunden für den externen Server eingestellt haben, bei den meisten Anfragen tatsächlich eine Verzögerung von 4 Sekunden erhalten. Darüber hinaus stellen wir fest, dass nur die ersten Anfragen die konfigurierte Verzögerung von 2 Sekunden einhalten, während nachfolgende Anfragen zu einer Verzögerung von 4 Sekunden führen.
Profiling ist wichtig, wenn Sie auf seltsames Codeverhalten stoßen, da es Leistungsengpässe identifiziert, versteckte Probleme wie Speicherlecks aufdeckt und zeigt, wie Ihre Anwendung Systemressourcen nutzt.
Dieses Mal werden wir die Lauf-App mit JFR profilieren, während wir den Bauchmuskelbelastungstest durchführen.
$ jcmdJFR.start name=app-profile duration=60s filename=app-profile-$(date +%FT%H-%M-%S).jfr
$ ab -n 50 -c 4 http://localhost:8080/ ... Percentage of the requests served within a certain time (ms) 50% 4043 66% 4051 75% 4057 80% 4060 90% 4066 95% 4068 98% 4077 99% 4077 100% 4077 (longest request)
Wenn wir die JFR-Datei öffnen und uns das Flamegraph ansehen, können wir sehen, dass die meiste Ausführungszeit von unserem HTTP-Client aufgewendet wird. Die Ausführungszeit des Clients teilt sich auf zwischen dem Warten auf die Antwort unseres externen Dienstes und dem Warten auf eine Verbindung vom Pool.
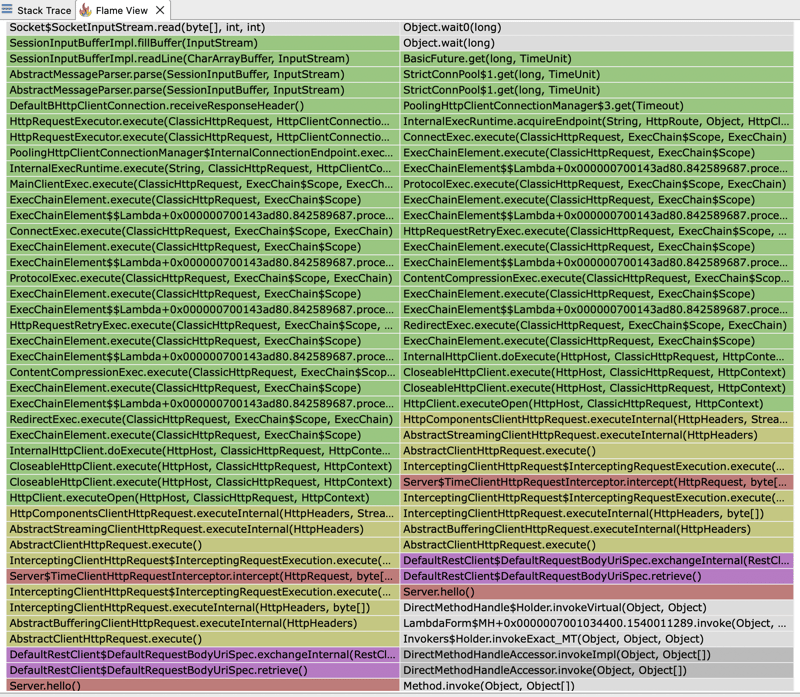
Das erklärt, warum die Antwortzeiten, die wir sehen, doppelt so hoch sind wie die erwartete feste Verzögerung von 2 Sekunden, die wir für unseren externen Server festgelegt haben. Wir haben einen Pool mit 2 Verbindungen konfiguriert. In unserem Test führen wir jedoch vier gleichzeitige Anfragen durch. Daher werden nur die ersten beiden Anfragen in der erwarteten Zeit von 2 Sekunden bearbeitet. Nachfolgende Anfragen müssen warten, bis der Pool eine Verbindung freigibt, wodurch sich die beobachtete Antwortzeit erhöht.
Wenn wir uns den Flamegraph noch einmal ansehen, können wir auch herausfinden, warum die von unserem ClientHttpRequestInterceptor gemessene Zeit nicht die Zeit widerspiegelt, die der externe Server benötigt, um zu antworten, sondern die Zeit, die benötigt wird, um eine Verbindung aus dem Pool herzustellen, plus die Zeit, die er für die Ausführung benötigt die eigentliche Anfrage an den externen Server. Unser Interceptor verpackt tatsächlich einen Stack-Trace, der schließlich einen Pool-Manager aufruft, um eine Verbindung herzustellen: PoolingHttpClientConnectionManager
HTTP 클라이언트의 응답 시간을 모니터링하는 것은 내장된 측정항목을 사용하는 것이 가장 좋습니다. 이러한 측정항목은 정확한 타이밍 정보를 캡처하도록 특별히 설계되었기 때문입니다. 이는 연결 획득, 데이터 전송 및 응답 처리를 포함하여 HTTP 요청 수명주기의 모든 측면을 설명합니다. 이를 통해 측정값이 정확하고 클라이언트의 실제 성능과 일관되게 유지됩니다.
Das obige ist der detaillierte Inhalt vonMetriken können Sie täuschen: Messen der Ausführungszeit in Umgebungen mit Verbindungspools. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So stellen Sie mit sqlplus eine Verbindung zur Datenbank her
So stellen Sie mit sqlplus eine Verbindung zur Datenbank her Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
Gründe, warum der Touchscreen eines Mobiltelefons ausfällt Litecoin-Preis heute
Litecoin-Preis heute Was nützt Bitlocker?
Was nützt Bitlocker? Welche Börse ist EDX?
Welche Börse ist EDX? Was sind die häufig verwendeten Funktionen von Informix?
Was sind die häufig verwendeten Funktionen von Informix? Was bedeutet Chrom?
Was bedeutet Chrom? So stellen Sie den normalen Druck wieder her, wenn der Drucker offline ist
So stellen Sie den normalen Druck wieder her, wenn der Drucker offline ist
























