Menschenpädagogische Methoden eignen sich auch für große Modelle.
Bei der Kindererziehung haben Menschen aller Zeiten über eine wichtige Methode gesprochen: mit gutem Beispiel voranzugehen. Das heißt, seien Sie ein Vorbild für Kinder, das sie nachahmen und von dem sie lernen können, anstatt ihnen nur zu sagen, was sie tun sollen. Beim Training eines großen Sprachmodells (LLM) können wir diese Methode möglicherweise auch verwenden und dem Modell demonstrieren.
Kürzlich hat das Team von Yang Diyi an der Stanford University ein neues Framework DITTO vorgeschlagen, das LLM durch eine kleine Anzahl von Demonstrationen (von Benutzern bereitgestellte Beispiele für gewünschtes Verhalten) an bestimmte Einstellungen anpassen kann. Diese Beispiele können aus den vorhandenen Interaktionsprotokollen des Benutzers oder durch direktes Bearbeiten der Ausgabe von LLM abgerufen werden. Dadurch kann das Modell Benutzerpräferenzen für verschiedene Benutzer und Aufgaben effizient verstehen und anpassen. 
- Papiertitel: Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
- Papieradresse: https://arxiv.org/pdf/2406.00888
DITTO can be Basierend auf einer kleinen Anzahl von Demos (weniger als 10) wird automatisch ein Datensatz erstellt, der eine große Anzahl von Präferenzvergleichen enthält (ein Prozess, der Gerüstbau genannt wird), indem stillschweigend erkannt wird, dass Benutzer das LLM gegenüber der Ausgabe des ursprünglichen LLM und früherer Iterationen bevorzugen . Anschließend werden die Demonstrations- und Modellausgabe zu Datenpaaren kombiniert, um einen erweiterten Datensatz zu erhalten. Das Sprachmodell kann dann mithilfe von Ausrichtungsalgorithmen wie DPO aktualisiert werden. Darüber hinaus entdeckte das Team auch, dass DITTO als Online-Imitations-Lernalgorithmus betrachtet werden kann, bei dem aus LLM-Samples entnommene Daten zur Unterscheidung von Expertenverhalten verwendet werden. Aus dieser Perspektive zeigte das Team, dass DITTO durch Extrapolation eine Expertenleistung erzielen kann. Das Team hat die Wirkung von DITTO auch durch Experimente überprüft. Um LLM auszurichten, erfordern frühere Methoden oft die Verwendung von Tausenden von Vergleichsdatenpaaren, während DITTO das Verhalten des Modells mit nur wenigen Demonstrationen ändern kann. Diese kostengünstige und schnelle Anpassung wurde vor allem durch die Kernerkenntnis des Teams ermöglicht: Online-Vergleichsdaten sind durch Demonstrationen leicht verfügbar. 
Das Sprachmodell kann als Richtlinie π(y|x) betrachtet werden, die zu einer Verteilung von Eingabeaufforderung x und Abschlussergebnis y führt. Das Ziel von RLHF besteht darin, ein LLM zu trainieren, um eine Belohnungsfunktion r (x, y) zu maximieren, die die Qualität des Ergebnispaars aus Eingabeaufforderung und Abschluss (x, y) bewertet. Normalerweise wird auch eine KL-Divergenz hinzugefügt, um zu verhindern, dass das aktualisierte Modell zu weit vom Basissprachenmodell (π_ref) abweicht. Insgesamt sind die Optimierungsziele der RLHF-Methode: 
Dies dient dazu, die erwartete Belohnung für die Prompt-Verteilung p zu maximieren, die von der durch α regulierten KL-Beschränkung beeinflusst wird. Typischerweise verwendet das Optimierungsziel einen Vergleichsdatensatz der Form {(x, y^w, y^l )}, wobei das „gewinnende“ Abschlussergebnis y^w besser ist als das „verlierende“ Abschlussergebnis y ^l, aufgezeichnet als y^w ⪰ y^l. Darüber hinaus markieren wir hier den kleinen Expertendemonstrationsdatensatz als D_E und gehen davon aus, dass diese Demonstrationen durch die Expertenrichtlinie π_E generiert werden, wodurch die Vorhersagebelohnung maximiert werden kann. DITTO kann die Ausgabe von Sprachmodellen und Expertendemonstrationen direkt nutzen, um Vergleichsdaten zu generieren. Das heißt, im Gegensatz zu generativen Paradigmen für synthetische Daten erfordert DITTO kein Modell, das bei einer bestimmten Aufgabe bereits eine gute Leistung erbringt. DITTOs wichtigste Erkenntnis ist, dass das Sprachmodell selbst in Verbindung mit Expertendemonstrationen zu einem Vergleichsdatensatz für die Ausrichtung führen kann, wodurch die Notwendigkeit entfällt, große Mengen paarweiser Präferenzdaten zu sammeln . Dies führt zu einem kontrastähnlichen Ziel, bei dem Expertendemonstrationen positive Beispiele sind. Vergleich generieren. Angenommen, wir probieren ein Vervollständigungsergebnis y^E ∼ π_E (・|x) aus der Expertenrichtlinie aus. Dann kann davon ausgegangen werden, dass die Belohnungen für Stichproben aus anderen Richtlinien π kleiner oder gleich den Belohnungen für Stichproben aus π_E sind. Basierend auf dieser Beobachtung erstellte das Team Vergleichsdaten (x, y^E, y^π), wobei y^E ⪰ y^π. Obwohl solche Vergleichsdaten eher aus Strategien als aus einzelnen Stichproben stammen, haben frühere Untersuchungen die Wirksamkeit dieses Ansatzes gezeigt. Ein natürlicher Ansatz für DITTO besteht darin, diesen Datensatz und einen leicht verfügbaren RLHF-Algorithmus zur Optimierung von (1) zu verwenden. Dadurch wird die Wahrscheinlichkeit von Expertenantworten verbessert und gleichzeitig die Wahrscheinlichkeit der aktuellen Modellstichprobe verringert, im Gegensatz zu Standard-Feinabstimmungsmethoden, die nur Ersteres bewirken. Der Schlüssel liegt darin, dass durch die Verwendung von Stichproben aus π mit einer kleinen Anzahl von Demonstrationen ein unbegrenzter Präferenzdatensatz erstellt werden kann. Das Team stellte jedoch fest, dass es noch besser gemacht werden könnte, wenn die zeitlichen Aspekte des Lernprozesses berücksichtigt würden. Vom Vergleich zum Ranking. Die alleinige Verwendung von Vergleichsdaten von Experten und einer einzigen Richtlinie π reicht möglicherweise nicht aus, um eine gute Leistung zu erzielen. Dadurch wird nur die Wahrscheinlichkeit eines bestimmten π verringert, was zum Überanpassungsproblem führt – das auch SFT mit wenigen Daten belastet. Das Team schlägt vor, dass es auch möglich ist, Daten zu berücksichtigen, die durch alle im Laufe der Zeit während RLHF erlernten Richtlinien generiert werden, ähnlich wie bei der Wiederholung beim Reinforcement Learning. Die anfängliche Strategie in der ersten Iterationsrunde sei π_0. Durch Abtasten dieser Strategie wird ein Datensatz D_0 erhalten. Darauf aufbauend kann dann ein Vergleichsdatensatz für RLHF generiert werden, der als D_E ⪰ D_0 bezeichnet werden kann. Mithilfe dieser abgeleiteten Vergleichsdaten kann π_0 aktualisiert werden, um π_1 zu erhalten. Per Definition gilt auch 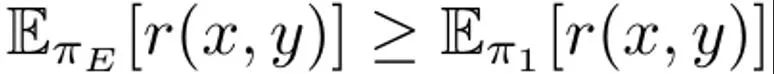 . Verwenden Sie danach weiterhin π_1, um Vergleichsdaten zu generieren, und D_E ⪰ D_1. Setzen Sie diesen Prozess fort und generieren Sie mithilfe aller vorherigen Strategien kontinuierlich immer vielfältigere Vergleichsdaten. Das Team nennt diese Vergleiche „Wiederholungsvergleiche“. Obwohl diese Methode theoretisch sinnvoll ist, kann es zu einer Überanpassung kommen, wenn D_E klein ist. Vergleiche zwischen Richtlinien können jedoch auch während des Trainings berücksichtigt werden, wenn davon ausgegangen wird, dass sich die Richtlinie nach jeder Iteration verbessert. Im Gegensatz zu Expertenvergleichen können wir nicht garantieren, dass die Strategie nach jeder Iteration besser wird, aber das Team stellte fest, dass sich das Gesamtmodell nach jeder Iteration immer noch verbessert. Dies kann daran liegen, dass sowohl die Belohnungsmodellierung als auch (1) konvex sind. Auf diese Weise können die Vergleichsdaten gemäß der folgenden Rangfolge abgetastet werden:
. Verwenden Sie danach weiterhin π_1, um Vergleichsdaten zu generieren, und D_E ⪰ D_1. Setzen Sie diesen Prozess fort und generieren Sie mithilfe aller vorherigen Strategien kontinuierlich immer vielfältigere Vergleichsdaten. Das Team nennt diese Vergleiche „Wiederholungsvergleiche“. Obwohl diese Methode theoretisch sinnvoll ist, kann es zu einer Überanpassung kommen, wenn D_E klein ist. Vergleiche zwischen Richtlinien können jedoch auch während des Trainings berücksichtigt werden, wenn davon ausgegangen wird, dass sich die Richtlinie nach jeder Iteration verbessert. Im Gegensatz zu Expertenvergleichen können wir nicht garantieren, dass die Strategie nach jeder Iteration besser wird, aber das Team stellte fest, dass sich das Gesamtmodell nach jeder Iteration immer noch verbessert. Dies kann daran liegen, dass sowohl die Belohnungsmodellierung als auch (1) konvex sind. Auf diese Weise können die Vergleichsdaten gemäß der folgenden Rangfolge abgetastet werden: 
Durch Hinzufügen dieser „Inter-Modell“- und „Wiederholungs“-Vergleichsdaten wird der Effekt erzielt, dass die Wahrscheinlichkeit früher Stichproben (z. B Proben in D_1) werden höher sein als spätere (wie in D_t). Drücken Sie niedriger, wodurch das implizite Belohnungsbild geglättet wird. In der praktischen Umsetzung besteht der Ansatz des Teams darin, nicht nur Vergleichsdaten mit Experten zu nutzen, sondern auch einige Vergleichsdaten zwischen diesen Modellen zu aggregieren. Ein praktischer Algorithmus. In der Praxis ist der DITTO-Algorithmus ein iterativer Prozess, der aus drei einfachen Komponenten besteht, wie in Algorithmus 1 gezeigt. 
Führen Sie zunächst eine überwachte Feinabstimmung am Experten-Demoset durch und führen Sie dabei eine begrenzte Anzahl von Gradientenschritten durch. Dies sei die anfängliche Richtlinie π_0. Zweiter Schritt, Beispielvergleichsdaten: Während des Trainings wird für jede der N Demonstrationen in D_E ein neuer Datensatz D_t erstellt, indem M Vervollständigungsergebnisse aus π_t abgetastet werden. Sie werden dann entsprechend zum Ranking hinzugefügt Strategie (2). Beim Abtasten von Vergleichsdaten aus Gleichung (2) besteht jeder Stapel B zu 70 % aus „Online“-Vergleichsdaten D_E ⪰ D_t und zu 20 % aus „Wiederholungs“-Vergleichsdaten D_E ⪰ D_{i
wobei σ die logistische Funktion von ist das Bradley-Terry-Präferenzmodell. Bei jedem Update wird das Referenzmodell aus der SFT-Strategie nicht aktualisiert, um eine zu große Abweichung von der Initialisierung zu vermeiden. Ableitung von DITTO in Online-Imitationslernen DITTO kann aus der Perspektive des Online-Imitationslernens abgeleitet werden, wobei eine Kombination aus Expertendemonstrationen und Online-Daten verwendet wird, um die Belohnungsfunktion und -politik gleichzeitig zu lernen. Insbesondere maximiert der Strategiespieler die erwartete Belohnung? (π, r), während der Belohnungsspieler den Verlust min_r L (D^π, r) im Online-Datensatz D^π minimiert Verwenden Sie das Richtlinienziel in (1) und den standardmäßigen Belohnungsmodellierungsverlust, um das Optimierungsproblem zu instanziieren: 
Bei der Ableitung von DITTO besteht der erste Schritt zur Vereinfachung von (3) darin, die internen Richtlinienmaximumprobleme zu lösen. Glücklicherweise stellte das Team auf der Grundlage früherer Untersuchungen fest, dass das politische Ziel ?_KL eine geschlossene Lösung der Form hat, wobei Z (x) die Partitionsfunktion der normalisierten Verteilung ist. Insbesondere entsteht dadurch eine bijektive Beziehung zwischen der Richtlinie und der Belohnungsfunktion, die zur Eliminierung interner Optimierungen genutzt werden kann. Durch Neuanordnung dieser Lösung kann die Belohnungsfunktion wie folgt geschrieben werden: 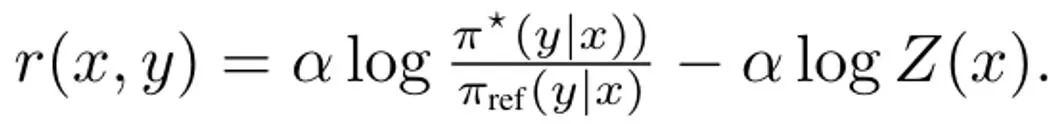 Darüber hinaus haben frühere Untersuchungen gezeigt, dass diese Neuparametrisierung beliebige Belohnungsfunktionen darstellen kann. Daher kann durch Einsetzen in Gleichung (3) die Variable r in π geändert werden, wodurch das DITTO-Ziel erhalten wird:
Darüber hinaus haben frühere Untersuchungen gezeigt, dass diese Neuparametrisierung beliebige Belohnungsfunktionen darstellen kann. Daher kann durch Einsetzen in Gleichung (3) die Variable r in π geändert werden, wodurch das DITTO-Ziel erhalten wird: 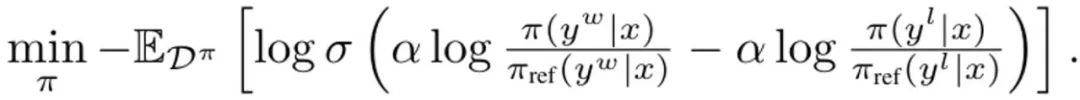 Bitte beachten Sie, dass die Belohnungsfunktion hier ähnlich wie bei DPO implizit geschätzt wird. Der Unterschied zu DPO besteht darin, dass DITTO auf einem Online-Präferenzdatensatz D^π basiert. Warum ist DITTO besser als nur SFT zu verwenden? Ein Grund, warum DITTO besser abschneidet, ist, dass es durch die Generierung von Vergleichsdaten viel mehr Daten verwendet als SFT. Ein weiterer Grund ist, dass Online-Lernmethoden zur Nachahmung in manchen Fällen besser abschneiden als Präsentatoren, wohingegen SFT lediglich Demonstrationen nachahmen kann. Experimentelle ErgebnisseDas Team führte auch empirische Untersuchungen durch, um die Wirksamkeit von DITTO zu beweisen. Die spezifischen Einstellungen des Experiments entnehmen Sie bitte dem Originalpapier. Wir konzentrieren uns hier nur auf die experimentellen Ergebnisse. Forschungsergebnisse basierend auf statischen Benchmarks Für die Auswertung statischer Benchmarks wurde GPT-4 verwendet. Die Ergebnisse sind in Tabelle 1 dargestellt.
Bitte beachten Sie, dass die Belohnungsfunktion hier ähnlich wie bei DPO implizit geschätzt wird. Der Unterschied zu DPO besteht darin, dass DITTO auf einem Online-Präferenzdatensatz D^π basiert. Warum ist DITTO besser als nur SFT zu verwenden? Ein Grund, warum DITTO besser abschneidet, ist, dass es durch die Generierung von Vergleichsdaten viel mehr Daten verwendet als SFT. Ein weiterer Grund ist, dass Online-Lernmethoden zur Nachahmung in manchen Fällen besser abschneiden als Präsentatoren, wohingegen SFT lediglich Demonstrationen nachahmen kann. Experimentelle ErgebnisseDas Team führte auch empirische Untersuchungen durch, um die Wirksamkeit von DITTO zu beweisen. Die spezifischen Einstellungen des Experiments entnehmen Sie bitte dem Originalpapier. Wir konzentrieren uns hier nur auf die experimentellen Ergebnisse. Forschungsergebnisse basierend auf statischen Benchmarks Für die Auswertung statischer Benchmarks wurde GPT-4 verwendet. Die Ergebnisse sind in Tabelle 1 dargestellt. 
平均すると、DITTO は他のすべての手法を上回っています。CMCC では平均勝率 71.67%、CCAT50 では平均勝率 82.50%、全体の平均勝率は 77.09% です。 CCAT50 では、すべての著者のうち、DITTO が総合優勝を達成できなかったのは 1 つの著者だけでした。 CMCC では、すべての著者に対して、DITTO が全面的にベンチマークの半分を上回り、続いて少数ショット プロンプト勝利が 30% も優れています。 SFT は好調でしたが、DITTO はそれに比べて平均勝率を 11.7% 向上させました。 ユーザー調査: 自然なタスクに一般化する能力のテスト全体的に、ユーザー調査の結果は静的ベンチマークの結果と一致しています。表 2 に示すように、DITTO は、調整されたデモの優先度の点で対照的な手法よりも優れています。ここで、DITTO (72.1% 勝率) > SFT (60.1%) > 少数ショット (48.1%) > セルフプロンプト (44.2%) >ゼロショット (25.0%)。 
DITTO を使用する前に、ユーザーはデモの数から言語モデルからサンプリングする必要がある否定例の数まで、いくつかの前提条件を考慮する必要があります。チームはこれらの決定の影響を調査し、CCAT よりも多くのミッションをカバーする CMCC に焦点を当てました。さらに、彼らはデモンストレーションとペアのフィードバックのサンプル効率を分析しました。 チームは、DITTOのコンポーネントについてアブレーション研究を実施しました。 図 2 (左) に示すように、DITTO の反復回数を増やすと、通常、パフォーマンスが向上します。 
反復回数を1から4に増やすと、GPT-4で評価される勝率が31.5%増加することがわかります。この改善は単調ではありません。反復 2 では、パフォーマンスがわずかに低下します (-3.4%)。これは、初期の反復ではノイズの多いサンプルが生成され、パフォーマンスが低下する可能性があるためです。一方、図 2 (中央) に示すように、負の例の数を増加させると、DITTO のパフォーマンスが単調に向上します。さらに、より多くの負の例がサンプリングされるにつれて、DITTO パフォーマンスの分散は減少します。 
また、表 3 に示すように、DITTO に関するアブレーション研究では、コンポーネントのいずれかを除去するとパフォーマンスが低下することがわかりました。 たとえば、オンライン反復サンプリングを放棄した場合、DITTO を使用した場合と比較して、勝率は 70.1% から 57.3% に低下します。また、オンライン プロセス中に π_ref が継続的に更新されると、パフォーマンスが 70.1% から 45.8% に大幅に低下します。研究チームは、その理由として、π_ref の更新が過学習につながる可能性があると推測しています。最後に、表 3 からは、リプレイと戦略間の比較データの重要性もわかります。 DITTO の重要な利点の 1 つは、サンプル効率です。チームはこれを評価し、その結果を図 2 (右) に示します。ここでも正規化された勝率が報告されています。 まず、DITTOの勝率は序盤で急激に上がっていくことが分かります。デモの数が 1 から 3 に増加するにつれて、正規化されたパフォーマンスは増加ごとに大幅に向上します (0% → 5% → 11.9%)。 しかし、デモの数がさらに増加すると、収益の増加は減少し(4 から 7 に増加した場合は 11.9% → 15.39%)、これは、デモの数が増加するにつれて、DITTO のパフォーマンスが飽和することを示しています。 さらに、チームは、デモンストレーションの数が DITTO のパフォーマンスに影響を与えるだけでなく、デモンストレーションの品質にも影響を与えると推測していますが、これは将来の研究に残されています。 DITTO の中核となる前提は、サンプルの効率はデモンストレーションから得られるということです。理論的には、ユーザーが完璧なデモンストレーションのセットを念頭に置いている場合、多数の嗜好データのペアに注釈を付けることで同様の効果を達成できます。 チームは、Compliance Mistral 7B からサンプリングされた出力を使用して綿密な実験を行い、ユーザー調査のデモを提供した著者の 1 人によって注釈が付けられた 500 組の嗜好データも用意しました。 要約すると、彼らはペアごとの選好データセット D_pref = {(x, y^i , y^j )} (y^i ≻ y^j) を構築しました。次に、2 つのモデルからサンプリングされた 20 組の結果の勝率を計算しました。1 つは DITTO を使用して 4 つのデモでトレーニングされ、もう 1 つは DPO のみを使用して {0...500} の嗜好データ ペアでトレーニングされました。 
π_ref からのみペアごとのプリファレンス データをサンプリングすると、生成されたデータ ペアが実証された分布の外側にあることが観察できます。ペアごとのプリファレンスには、ユーザーによって実証された動作が含まれていません (図 3 のベース ポリシーの結果、青色)。ユーザーのデモを使用して π_ref を微調整した場合でも、DITTO のパフォーマンスと一致させるには、依然として 500 ペアを超える設定データが必要でした (図 3 のデモで微調整されたポリシーの結果、オレンジ色)。 Das obige ist der detaillierte Inhalt vonEs sind nur wenige Demonstrationen erforderlich, um große Modelle auszurichten. Das von Yang Diyis Team vorgeschlagene DITTO ist äußerst effizient.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 Welche Auflösung ist 1080p?
Welche Auflösung ist 1080p?
 So führen Sie ein PHPStudy-Projekt aus
So führen Sie ein PHPStudy-Projekt aus
 psrpc.dll keine Lösung gefunden
psrpc.dll keine Lösung gefunden
 Das neueste Ranking der zehn besten Börsen im Währungskreis
Das neueste Ranking der zehn besten Börsen im Währungskreis
 Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
 WLAN zeigt keinen Zugang zum Internet an
WLAN zeigt keinen Zugang zum Internet an
 Einführung in das xmpp-Protokoll
Einführung in das xmpp-Protokoll
 Was ist Funktion?
Was ist Funktion?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



