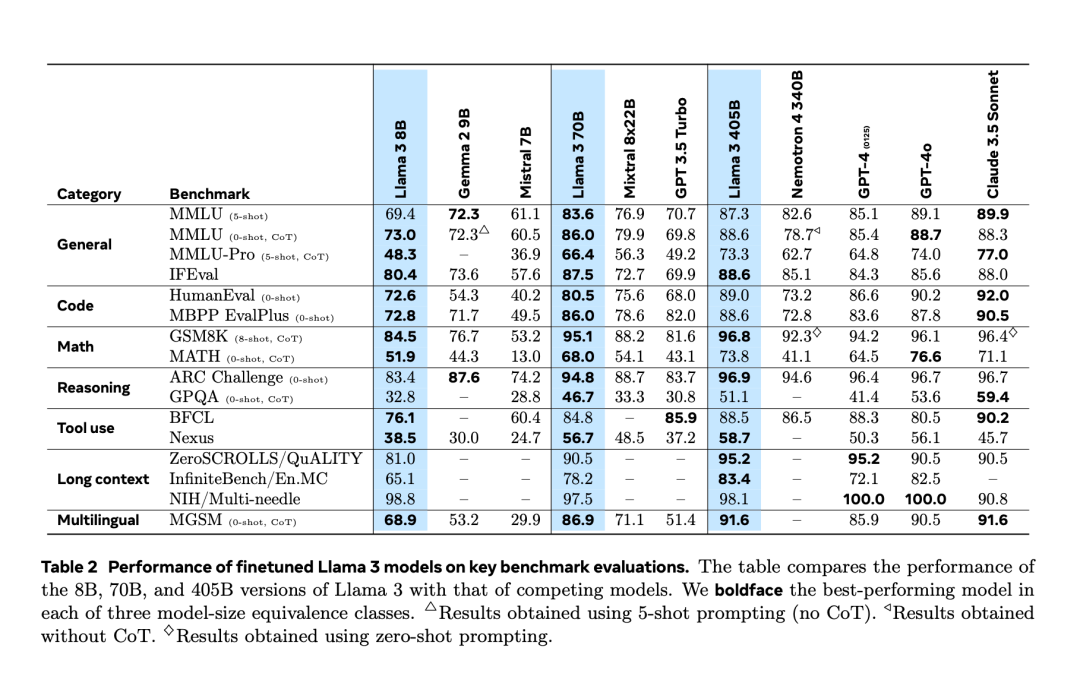
Nachdem es zwei Tage zuvor zu einem „versehentlichen Leak“ kam, wurde Llama 3.1 gestern Abend endlich offiziell veröffentlicht. Llama 3.1 erweitert die Kontextlänge auf 128 KB und ist in den Versionen 8B, 70B und 405B erhältlich, wodurch die Messlatte für den Wettbewerb auf großen Modellstrecken noch einmal im Alleingang höher gelegt wird. Für die KI-Community besteht die wichtigste Bedeutung von Llama 3.1 405B darin, dass es die Obergrenze der Fähigkeiten des Open-Source-Basismodells aktualisiert. Meta-Beamte sagten, dass seine Leistung bei einer Reihe von Aufgaben mit der besten geschlossenen Version vergleichbar sei Quellmodell. Die folgende Tabelle zeigt, wie die aktuellen Modelle der Llama 3-Serie bei wichtigen Benchmarks abschneiden. Es ist ersichtlich, dass die Leistung des 405B-Modells der von GPT-4o sehr nahe kommt.
Gleichzeitig veröffentlichte Meta das Papier „The Llama 3 Herd of Models“, in dem die bisherigen Forschungsdetails der Modelle der Llama 3-Serie enthüllt wurden.

to B verwendet eine Kontextlänge von 8 KB. Nach dem Vortraining wird ein kontinuierliches Training mit einer Kontextlänge von 128 KB durchgeführt, wodurch mehrere Sprachen und die Verwendung von Tools unterstützt werden.
Meta verbessert die Vorverarbeitung des Llama-Modells und der Kurationspipelines von Daten vor dem Training sowie die Qualitätssicherungs- und Filtermethoden von Daten nach dem Training.
Meta ist davon überzeugt, dass es drei Schlüsselhebel für die Entwicklung hochwertiger zugrunde liegender Modelle gibt: Daten-, Skalen- und Komplexitätsmanagement.
-
- Daten:
Meta hat im Vergleich zu früheren Llama-Versionen sowohl Quantität als auch Qualität der Daten vor und nach dem Training verbessert. Llama 3 ist auf einem Korpus von etwa 15 Billionen mehrsprachigen Token vorab trainiert, während Llama 2 nur 1,8 Billionen Token verwendet.
Maßstab:
Trainierte Modelle sind viel größer als frühere Llama-Modelle: Das Flaggschiff-Sprachmodell verwendet 3,8 x 10^25 Gleitkommaoperationen (FLOPs) für das Vortraining und übertrifft damit die größte Version von Llama 2 um fast das 50-fache. -
Komplexitätsmanagement:
Nach dem Skalierungsgesetz hat Metas Flaggschiffmodell ungefähr die optimale Größe berechnet, aber die Trainingszeit kleinerer Modelle hat die berechnete optimale Zeit bei weitem überschritten. Die Ergebnisse zeigen, dass diese kleineren Modelle rechnerisch optimale Modelle bei gleichem Inferenzbudget übertreffen. In der Post-Training-Phase nutzt Meta das 405B-Flaggschiffmodell, um die Qualität kleinerer Modelle wie 70B und 8B weiter zu verbessern. - Das Vortraining von 405B auf 15,6T-Tokens (3,8x10^25 FLOPs) war eine große Herausforderung. Meta optimierte den gesamten Trainingsstack und verwendete über 16.000 H100-GPUs.
Wie PyTorch-Gründer und Meta Distinguished Engineer Soumith Chintala sagte, enthüllt das Llama3-Papier viele coole Details, darunter den Aufbau der Infrastruktur.
- 1. Während des Trainings verbessert Meta das Chat-Modell durch mehrere Ausrichtungsrunden, einschließlich überwachter Feinabstimmung (SFT), Ablehnungsstichprobe und direkter Präferenzoptimierung. Die meisten SFT-Proben werden aus synthetischen Daten generiert.
- Para penyelidik membuat beberapa pilihan dalam reka bentuk untuk memaksimumkan kebolehskalaan proses pembangunan model. Sebagai contoh, seni bina model Transformer padat standard dipilih dengan hanya pelarasan kecil dan bukannya campuran pakar untuk memaksimumkan kestabilan latihan. Begitu juga, prosedur pasca latihan yang agak mudah diguna pakai, berdasarkan penalaan halus (SFT), pensampelan penolakan (RS), dan pengoptimuman keutamaan langsung (DPO), berbanding algoritma pembelajaran pengukuhan yang lebih kompleks, yang cenderung kurang stabil. dan Pelanjutan yang lebih sukar.
- Sebagai sebahagian daripada proses pembangunan Llama 3, pasukan Meta turut membangunkan sambungan pelbagai mod model, memberikannya keupayaan dalam pengecaman imej, pengecaman video dan pemahaman pertuturan. Model-model ini masih dalam pembangunan aktif dan belum bersedia untuk dikeluarkan, tetapi kertas kerja membentangkan hasil percubaan awal dengan model multimodal ini.
- Meta telah mengemas kini lesennya untuk membenarkan pembangun menggunakan output model Llama untuk mempertingkatkan model lain.
- Di penghujung kertas ini, kami juga melihat senarai panjang penyumbang: fenye1 siri faktor ini akhirnya mencipta siri Llama 3 hari ini.
- Sudah tentu, bagi pembangun biasa, cara menggunakan model Llama berskala 405B adalah satu cabaran dan memerlukan banyak sumber dan kepakaran pengkomputeran.
- Selepas pelancaran, ekosistem Llama 3.1 sudah sedia, dengan lebih 25 rakan kongsi menawarkan perkhidmatan yang berfungsi dengan model terkini, termasuk Amazon Cloud Technologies, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, Snowflake dan banyak lagi .

Untuk butiran lanjut teknikal, sila rujuk kertas asal.
Das obige ist der detaillierte Inhalt vonWie erstellt man ein Open-Source-Modell, das GPT-4o besiegen kann? In Bezug auf Llama 3.1 405B wird Meta in diesem Artikel geschrieben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



