Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns bereits zahlreiche synthetische Bilder und Videos im Internet die Kraft der Verbreitung gezeigt Modelle.
Kürzlich hat ein Forschungsteam am MIT CSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Funktionen des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Training und eine Probenahme vorgeschlagen Paradigma: Diffusion Forcing (DF).
Papiertitel: Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Papieradresse: https://arxiv.org/pdf/2407.01392
Projektwebsite: https:/ /arxiv.org/pdf/2407.01392 /boyuan.space/diffusion-forcing
Codeadresse: https://github.com/buoyancy99/diffusion-forcing
Wie unten gezeigt, übertrifft der Diffusionsantrieb die Gesamtleistung deutlich Begriffe Konsistenz und Stabilität Zwei Methoden sind Sequenzdiffusion und Erzwingen durch Lehrer.

In diesem Rahmen ist jedem Token ein zufälliger, unabhängiger Rauschpegel zugeordnet, und ein gemeinsames Vorhersagemodell für den nächsten Token oder ein Vorhersagemodell für den nächsten Token kann gemäß einem beliebigen, unabhängigen Schema pro Token verwendet werden. Denoise den Token entrauschen.
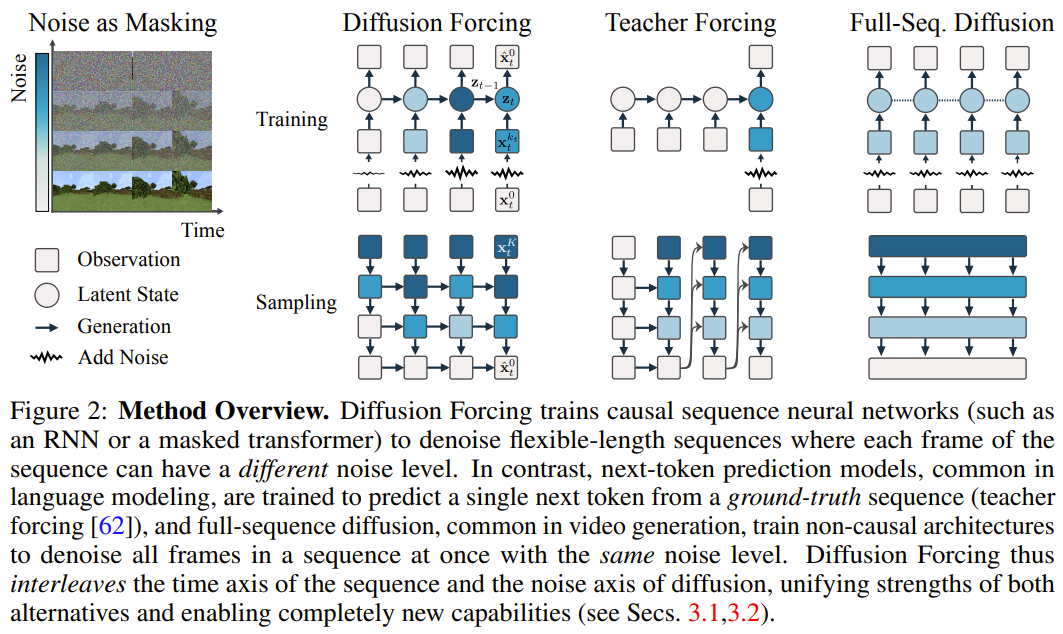
Die Forschungsinspiration dieser Methode stammt aus dieser Beobachtung: Der Prozess des Hinzufügens von Rauschen zum Token ist eine Form eines teilweisen Maskierungsprozesses – Null Rauschen bedeutet, dass der Token nicht maskiert ist, während vollständiges Rauschen den Token vollständig maskiert. Daher zwingt DF das Modell dazu, eine Maske zu lernen, die alle variablen Sätze verrauschter Token entfernt (Abbildung 2).
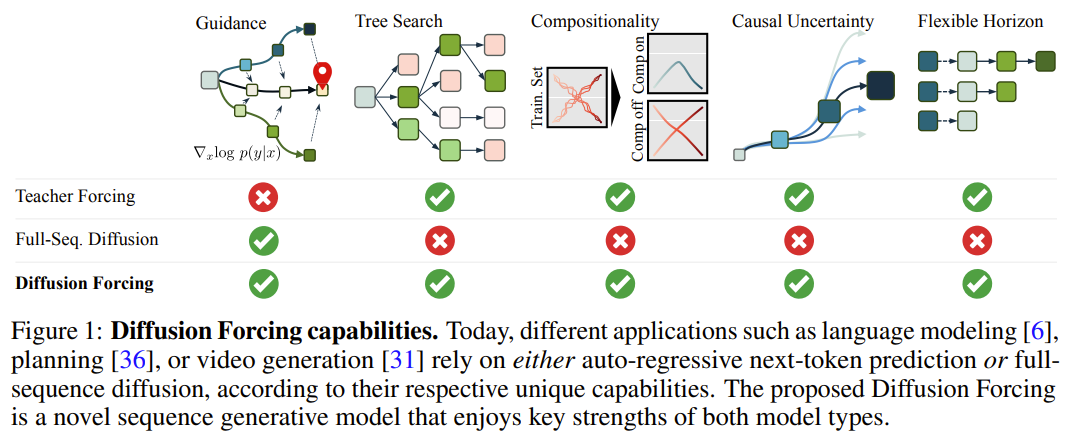
Gleichzeitig kann das System durch die Parametrisierung der Vorhersagemethode als Kombination mehrerer Next-Token-Vorhersagemodelle flexibel Sequenzen unterschiedlicher Länge generieren und auf kombinatorische Weise auf neue Trajektorien verallgemeinern (Abbildung 1).
Das Team implementierte den für die Sequenzgenerierung verwendeten DF in Causal Diffusion Forcing (CDF), bei dem zukünftige Token durch eine kausale Architektur von vergangenen Token abhängen. Sie trainierten das Modell, um alle Token einer Sequenz (wobei jeder Token einen unabhängigen Rauschpegel hat) auf einmal zu entrauschen.
Während des Samplings entrauscht CDF schrittweise eine Folge von Gaußschen Rauschrahmen in saubere Samples, wobei unterschiedliche Rahmen bei jedem Entrauschungsschritt unterschiedliche Rauschpegel aufweisen können. Ähnlich wie das Next-Token-Vorhersagemodell kann CDF Sequenzen variabler Länge generieren. Im Gegensatz zur Next-Token-Vorhersage ist die Leistung von CDF sehr stabil – unabhängig davon, ob das nächste Token, Tausende von Token in der Zukunft oder sogar kontinuierliche Token vorhergesagt werden.
Darüber hinaus kann es, ähnlich wie bei der vollständigen Sequenzdiffusion, auch Führung erhalten, was eine hohe Belohnungsgenerierung ermöglicht. Durch die gemeinsame Nutzung von Kausalität, flexiblem Umfang und variabler Geräuschplanung ermöglicht CDF eine neue Funktion: Monte Carlo Tree Guidance (MCTG). Im Vergleich zum nicht-kausalen Vollsequenz-Diffusionsmodell kann MCTG die Abtastrate der Generierung hoher Belohnungen erheblich verbessern. Abbildung 1 gibt einen Überblick über diese Funktionen. Diffusionserzwingung (Diffusionserzwingung) oder nicht) als eine geordnete Sammlung, indiziert durch t. Dann kann die Verwendung von Lehrerzwang zum Trainieren der Vorhersage des nächsten Tokens so interpretiert werden, dass jedes Token x_t zum Zeitpunkt t ausgeblendet und auf der Grundlage des vergangenen x_{1:t−1} vorhergesagt wird.
Für Sequenzen kann dieser Vorgang wie folgt beschrieben werden: Durchführen einer Maskierung entlang der Zeitachse. Wir können uns die vollständige Vorwärtsdiffusion (d. h. den Prozess des schrittweisen Hinzufügens von Rauschen zu den Daten
) als eine Art teilweiser Maskierung vorstellen, die als „Durchführen einer Maskierung entlang der Rauschachse“ bezeichnet werden kann
Nach dem Hinzufügen von Rauschen in K-Schritten ist
(wahrscheinlich) weißes Rauschen, und es gibt keine Informationen mehr über die Originaldaten. Wie in Abbildung 2 gezeigt, hat das Team eine einheitliche Perspektive für die Betrachtung der Kanten dieser beiden Achsen erstellt .
2. Verschiedene Token haben unterschiedliche Rauschpegel
Das Diffusionsforcing (DF)-Framework kann zum Trainieren und Abtasten verrauschter Token beliebiger Sequenzlänge
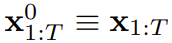 verwendet werden Der Rauschpegel k_t jedes Tokens ändert sich mit der Zeit.
Dieser Artikel konzentriert sich auf Zeitreihendaten, sodass sie DF durch eine kausale Architektur instanziieren und somit einen kausalen Diffusionsantrieb erhalten Minimale Implementierung, die mithilfe eines grundlegenden rekurrenten neuronalen Netzwerks (RNN) erhalten wird. Ein RNN mit Gewicht θ behält einen verborgenen Zustand z_t bei, der über den Einfluss vergangener Token informiert wird. Er entwickelt sich entsprechend der Dynamik
verwendet werden Der Rauschpegel k_t jedes Tokens ändert sich mit der Zeit.
Dieser Artikel konzentriert sich auf Zeitreihendaten, sodass sie DF durch eine kausale Architektur instanziieren und somit einen kausalen Diffusionsantrieb erhalten Minimale Implementierung, die mithilfe eines grundlegenden rekurrenten neuronalen Netzwerks (RNN) erhalten wird. Ein RNN mit Gewicht θ behält einen verborgenen Zustand z_t bei, der über den Einfluss vergangener Token informiert wird. Er entwickelt sich entsprechend der Dynamik
 durch eine Schleifenschicht.Wenn eine Beobachtung des Eingangsrauschens
durch eine Schleifenschicht.Wenn eine Beobachtung des Eingangsrauschens
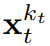 erhalten wird, wird der verborgene Zustand auf Markovsche Weise aktualisiert.
Wenn k_t=0, ist dies die hintere Aktualisierung in der Bayes'schen Filterung; und wenn k_t=K (reines Rauschen, keine Informationen), entspricht dies der Modellierung der "posterioren Verteilung" p_θ(z_t | z_{ t−1}).
Angesichts des verborgenen Zustands z_t besteht das Ziel des Beobachtungsmodells p_θ(x_t^0 | z_t) darin, x_t vorherzusagen; das Eingabe-Ausgabe-Verhalten dieser Einheit ist das gleiche wie beim Standardmodell der bedingten Diffusion: mit Bedingungsvariable z_{t−1 } und verrauschtes Token als Eingabe, sagen das geräuschlose x_t=x_t^0 voraus und sagen dadurch indirekt das Rauschen ε^{k_t} durch affine Neuparametrisierung voraus. Daher können wir das klassische Diffusionsziel direkt verwenden, um den (kausalen) Diffusionsantrieb zu trainieren. Gemäß dem Rauschvorhersageergebnis ε_θ kann die obige Einheit parametrisiert werden. Dann werden die Parameter θ gefunden, indem der folgende Verlust minimiert wird:
erhalten wird, wird der verborgene Zustand auf Markovsche Weise aktualisiert.
Wenn k_t=0, ist dies die hintere Aktualisierung in der Bayes'schen Filterung; und wenn k_t=K (reines Rauschen, keine Informationen), entspricht dies der Modellierung der "posterioren Verteilung" p_θ(z_t | z_{ t−1}).
Angesichts des verborgenen Zustands z_t besteht das Ziel des Beobachtungsmodells p_θ(x_t^0 | z_t) darin, x_t vorherzusagen; das Eingabe-Ausgabe-Verhalten dieser Einheit ist das gleiche wie beim Standardmodell der bedingten Diffusion: mit Bedingungsvariable z_{t−1 } und verrauschtes Token als Eingabe, sagen das geräuschlose x_t=x_t^0 voraus und sagen dadurch indirekt das Rauschen ε^{k_t} durch affine Neuparametrisierung voraus. Daher können wir das klassische Diffusionsziel direkt verwenden, um den (kausalen) Diffusionsantrieb zu trainieren. Gemäß dem Rauschvorhersageergebnis ε_θ kann die obige Einheit parametrisiert werden. Dann werden die Parameter θ gefunden, indem der folgende Verlust minimiert wird:
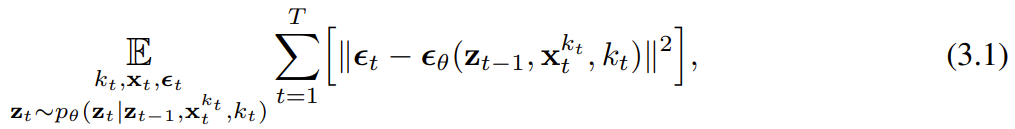 Algorithmus 1 gibt den Pseudocode an. Der Punkt ist, dass dieser Verlust Schlüsselelemente der Bayes'schen Filterung und der bedingten Diffusion erfasst. Das Team hat außerdem gängige Techniken, die beim Diffusionsmodelltraining für den Diffusionsantrieb verwendet werden, weiter neu abgeleitet, wie im Anhang des Originalpapiers beschrieben. Sie kamen auch zu einem informellen Theorem.
Satz 3.1 (informell). Das diffusionserzwungene Trainingsverfahren (Algorithmus 1) ist eine Neugewichtung, die die Evidenzuntergrenze (ELBO) für die erwartete Log-Likelihood
Algorithmus 1 gibt den Pseudocode an. Der Punkt ist, dass dieser Verlust Schlüsselelemente der Bayes'schen Filterung und der bedingten Diffusion erfasst. Das Team hat außerdem gängige Techniken, die beim Diffusionsmodelltraining für den Diffusionsantrieb verwendet werden, weiter neu abgeleitet, wie im Anhang des Originalpapiers beschrieben. Sie kamen auch zu einem informellen Theorem.
Satz 3.1 (informell). Das diffusionserzwungene Trainingsverfahren (Algorithmus 1) ist eine Neugewichtung, die die Evidenzuntergrenze (ELBO) für die erwartete Log-Likelihood
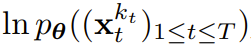 optimiert, wobei der erwartete Wert über den Rauschpegel gemittelt wird und
optimiert, wobei der erwartete Wert über den Rauschpegel gemittelt wird und
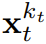 gemäß einem Vorwärtsprozess verrauscht ist. Darüber hinaus kann die Optimierung von (3.1) unter geeigneten Bedingungen auch die untere Wahrscheinlichkeitsgrenze aller Rauschpegelsequenzen gleichzeitig maximieren.
Diffusionserzwungene Probenahme und die daraus resultierende Fähigkeit
Algorithmus 2 beschreibt den Probenahmeprozess, der definiert ist als: in einem zweidimensionalen M × T-Gitter K ∈ [K]^{M×T } gibt den Lärmplan an; die Spalten entsprechen den Zeitschritten t und die mit m indizierten Zeilen bestimmen den Lärmpegel.
Um die gesamte Sequenz der Länge T zu generieren, wird Token x_{1:T} zunächst auf weißes Rauschen initialisiert, entsprechend dem Rauschpegel k = K. Anschließend wird das Raster Zeile für Zeile durchlaufen und Spalte für Spalte von links nach rechts entrauscht, bis der Rauschpegel K erreicht. Bis m = 0 in der letzten Zeile ist das Rauschen des Tokens beseitigt, d. h. der Rauschpegel beträgt K_{0,t} ≡ 0.
Dieses Sampling-Paradigma wird die folgenden neuen Funktionen mit sich bringen:
gemäß einem Vorwärtsprozess verrauscht ist. Darüber hinaus kann die Optimierung von (3.1) unter geeigneten Bedingungen auch die untere Wahrscheinlichkeitsgrenze aller Rauschpegelsequenzen gleichzeitig maximieren.
Diffusionserzwungene Probenahme und die daraus resultierende Fähigkeit
Algorithmus 2 beschreibt den Probenahmeprozess, der definiert ist als: in einem zweidimensionalen M × T-Gitter K ∈ [K]^{M×T } gibt den Lärmplan an; die Spalten entsprechen den Zeitschritten t und die mit m indizierten Zeilen bestimmen den Lärmpegel.
Um die gesamte Sequenz der Länge T zu generieren, wird Token x_{1:T} zunächst auf weißes Rauschen initialisiert, entsprechend dem Rauschpegel k = K. Anschließend wird das Raster Zeile für Zeile durchlaufen und Spalte für Spalte von links nach rechts entrauscht, bis der Rauschpegel K erreicht. Bis m = 0 in der letzten Zeile ist das Rauschen des Tokens beseitigt, d. h. der Rauschpegel beträgt K_{0,t} ≡ 0.
Dieses Sampling-Paradigma wird die folgenden neuen Funktionen mit sich bringen:
-
Stabile autoregressive Generation
-
Halten Sie die Zukunft ungewiss
-
Langfristige Führungsfähigkeit
Nutzen Sie Diffusion Forcing für flexible Reihenfolgeentscheidungen
Die neue Fähigkeit des Diffusion Forcing bringt auch neue Möglichkeiten mit sich. Auf dieser Grundlage entwarf das Team ein neues Framework für die Sequenzentscheidung (SDM) und wendete es erfolgreich auf die Bereiche Roboter und autonome Agenten an.
Zuerst definieren Sie einen Markov-Entscheidungsprozess mit dynamischem p (s_{t+1}|s_t, a_t), Beobachtung p (o_t|s_t) und Belohnung p (r_t|s_t, a_t). Das Ziel besteht hier darin, eine Richtlinie π(a_t|o_{1:t}) zu trainieren, um die erwartete kumulative Belohnung der Flugbahn
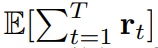 zu maximieren. Hier wird der Token x_t = [a_t, r_t, o_{t+1}] zugewiesen. Eine Trajektorie ist eine Folge x_{1:T}, deren Länge variabel sein kann; die Trainingsmethode ist wie in Algorithmus 1 gezeigt.
Bei jedem Schritt t des Ausführungsprozesses gibt es einen verborgenen Zustand z_{t-1}, der das vergangene rauschfreie Token x_{1:t-1} zusammenfasst.Basierend auf diesem verborgenen Zustand wird ein Plan
zu maximieren. Hier wird der Token x_t = [a_t, r_t, o_{t+1}] zugewiesen. Eine Trajektorie ist eine Folge x_{1:T}, deren Länge variabel sein kann; die Trainingsmethode ist wie in Algorithmus 1 gezeigt.
Bei jedem Schritt t des Ausführungsprozesses gibt es einen verborgenen Zustand z_{t-1}, der das vergangene rauschfreie Token x_{1:t-1} zusammenfasst.Basierend auf diesem verborgenen Zustand wird ein Plan
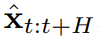 gemäß Algorithmus 2 erstellt, wobei
gemäß Algorithmus 2 erstellt, wobei
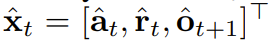 vorhergesagte Aktionen, Belohnungen und Beobachtungen enthält. H ist ein Vorwärtsbeobachtungsfenster, ähnlich den zukünftigen Vorhersagen in der modellprädiktiven Steuerung. Nachdem die geplante Aktion ausgeführt wurde, erhält die Umgebung eine Belohnung und die nächste Beobachtung und damit den nächsten Token. Der verborgene Zustand kann gemäß dem hinteren p_θ(z_t|z_{t−1}, x_t, 0) aktualisiert werden.
Das Framework kann sowohl als Strategie als auch als Planer verwendet werden. Zu seinen Vorteilen gehören:
vorhergesagte Aktionen, Belohnungen und Beobachtungen enthält. H ist ein Vorwärtsbeobachtungsfenster, ähnlich den zukünftigen Vorhersagen in der modellprädiktiven Steuerung. Nachdem die geplante Aktion ausgeführt wurde, erhält die Umgebung eine Belohnung und die nächste Beobachtung und damit den nächsten Token. Der verborgene Zustand kann gemäß dem hinteren p_θ(z_t|z_{t−1}, x_t, 0) aktualisiert werden.
Das Framework kann sowohl als Strategie als auch als Planer verwendet werden. Zu seinen Vorteilen gehören:
-
mit flexiblen Planungshorizonten
-
ermöglicht eine flexible Belohnungsführung
-
kann Monte erreicht werden Carlo Tree Guidance (MCTG), um zukünftige Unsicherheit zu erreichen
Das Team bewertete die Vorteile des Diffusionsantriebs als generatives Sequenzmodell, das Video- und Zeitreihenvorhersage, Planung und Nachahmungslernen umfasst andere Anwendungen.
Videovorhersage: konsistente und stabile Sequenzgenerierung und unendliche Erweiterung
Für die Video-generative Modellierungsaufgabe trainierten sie ein Faltungs-RNN zur Durchsetzung der kausalen Diffusion basierend auf Minecraft-Spielvideos und DMLab-Navigation.
Abbildung 3 zeigt die qualitativen Ergebnisse des Diffusionsantriebs im Vergleich zum Ausgangswert.
Es ist ersichtlich, dass sich der Diffusionsantrieb auch außerhalb seines Trainingsbereichs stabil entfalten kann, während der Lehrerantrieb und die Diffusions-Benchmarks der vollständigen Sequenz schnell auseinanderlaufen.
Diffusionsplanung: MCTG, kausale Unsicherheit, flexible Umfangskontrolle
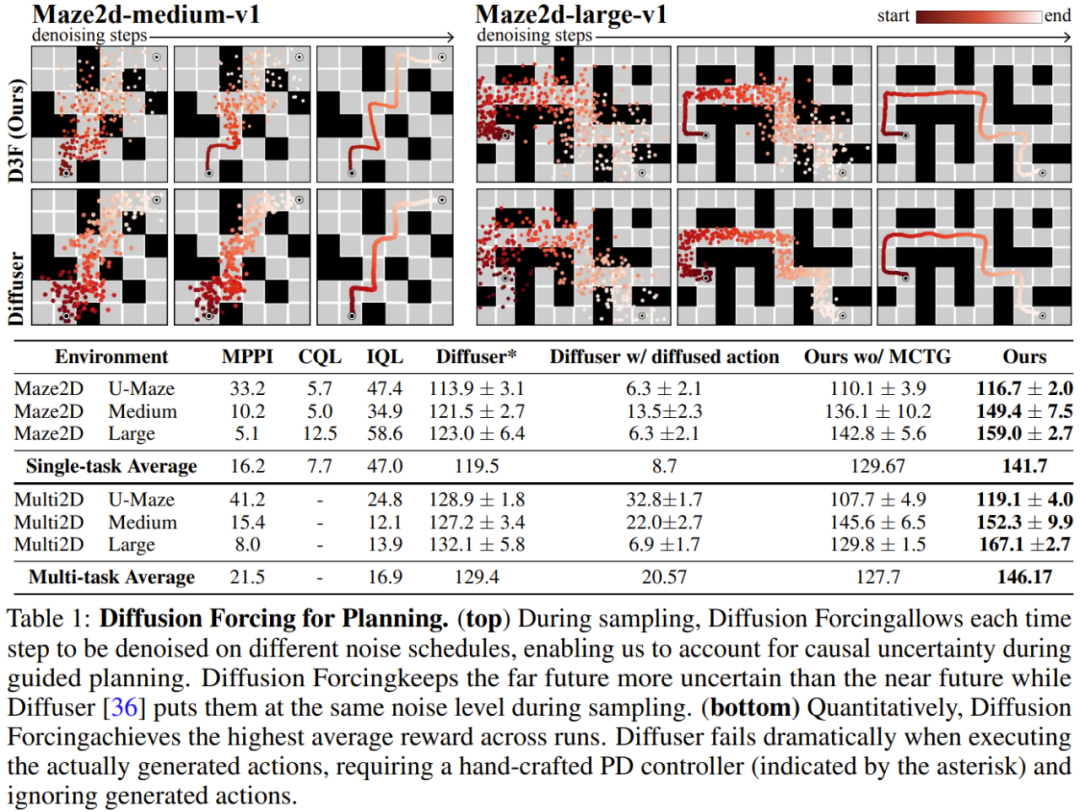
Die Fähigkeit zur diffusen Erzwingung kann einzigartige Vorteile für die Entscheidungsfindung bringen. Das Team bewertete das neu vorgeschlagene Entscheidungsrahmenwerk mithilfe von D4RL, einem standardmäßigen Offline-Lernrahmen zur Verstärkung.
Tabelle 1 gibt die qualitativen und quantitativen Bewertungsergebnisse wieder. Wie man sehen kann, übertrifft Diffusion Enforcement Diffuser und alle Baselines in allen 6 Umgebungen.
Kontrollierbare Sequenzkombinationsgenerierung
Das Team stellte fest, dass es möglich war, Teilsequenzen von zur Trainingszeit beobachteten Sequenzen flexibel zu kombinieren, indem einfach das Stichprobenschema geändert wurde.
Sie führten Experimente mit einem 2D-Trajektoriendatensatz durch: Auf einer quadratischen Ebene beginnen alle Trajektorien an einer Ecke und enden an der gegenüberliegenden Ecke und bilden so eine Art Kreuzform.
Wie in Abbildung 1 oben gezeigt, kann DF, wenn kein Kombinationsverhalten erforderlich ist, gestattet werden, den vollständigen Speicher beizubehalten und die Verteilung des Kreuzes zu reproduzieren. Wenn eine Kombination erforderlich ist, kann das Modell verwendet werden, um mithilfe von MPC gedächtnislos kürzere Pläne zu erstellen und dabei die Untertrajektorien dieses Kreuzes zusammenzufügen, um eine V-förmige Trajektorie zu erhalten.
Roboter: Fernimitationslernen und robuste visuelle Bewegungssteuerung
Diffusionserzwingung bietet auch neue Möglichkeiten für die visuelle Bewegungssteuerung realer Roboter.
Imitationslernen ist eine häufig verwendete Robotersteuerungstechnik, die Zuordnungen beobachteter Aktionen lernt, die von Experten demonstriert werden. Allerdings erschwert ein Mangel an Gedächtnis oft das Nachahmungslernen bei weitreichenden Aufgaben. DF kann diesen Mangel nicht nur lindern, sondern auch das Nachahmungslernen robuster machen.
Verwenden Sie das Gedächtnis für Nachahmungslernen. Durch die Fernsteuerung des Franka-Roboters sammelte das Team einen Video- und Bewegungsdatensatz. Wie in Abbildung 4 dargestellt, besteht die Aufgabe darin, die Positionen von Äpfeln und Orangen mithilfe der dritten Position zu vertauschen. Die Ausgangsposition der Frucht ist zufällig, es gibt also zwei mögliche Zielzustände.
Wenn sich außerdem eine Frucht an der dritten Position befindet, kann das gewünschte Ergebnis nicht aus der aktuellen Beobachtung abgeleitet werden – die Strategie muss sich die anfängliche Konfiguration merken, um zu entscheiden, welche Frucht verschoben werden soll.Im Gegensatz zu häufig verwendeten Methoden zum Klonen von Verhalten kann DF Erinnerungen auf natürliche Weise in seinen eigenen verborgenen Zustand integrieren. Es wurde festgestellt, dass DF eine Erfolgsquote von 80 % erreichte, während die Diffusionsstrategie (derzeit der beste Algorithmus für gedächtnisloses Imitationslernen) fehlschlug.
 Darüber hinaus kann DF auch robuster mit Lärm umgehen und das Vortraining des Roboters erleichtern.
Zeitreihenvorhersage: Diffusionserzwingung ist ein ausgezeichnetes allgemeines Sequenzmodell
Für multivariate Zeitreihenvorhersageaufgaben zeigt die Forschung des Teams, dass DF ausreicht, um mit früheren Diffusionsmodellen und transformatorbasierten Modellen zu konkurrieren vergleichbar.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Darüber hinaus kann DF auch robuster mit Lärm umgehen und das Vortraining des Roboters erleichtern.
Zeitreihenvorhersage: Diffusionserzwingung ist ein ausgezeichnetes allgemeines Sequenzmodell
Für multivariate Zeitreihenvorhersageaufgaben zeigt die Forschung des Teams, dass DF ausreicht, um mit früheren Diffusionsmodellen und transformatorbasierten Modellen zu konkurrieren vergleichbar.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonUnbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!









 So vergrößern Sie den Webstorm
So vergrößern Sie den Webstorm Einführung in die Repeater-Verschachtelungsmethode
Einführung in die Repeater-Verschachtelungsmethode Objekt orientierte Programmierung
Objekt orientierte Programmierung Was ist der Unterschied zwischen RabbitMQ und Kafka?
Was ist der Unterschied zwischen RabbitMQ und Kafka? So integrieren Sie Ideen in Tomcat
So integrieren Sie Ideen in Tomcat So geben Sie doppelte Anführungszeichen in Latex ein
So geben Sie doppelte Anführungszeichen in Latex ein Eine Sammlung häufig verwendeter Computerbefehle
Eine Sammlung häufig verwendeter Computerbefehle Kostenlose ERP-Software
Kostenlose ERP-Software
























