


Wenn Sie ungenutzte Geräte haben, können Sie es vielleicht einmal versuchen.
Dieses Mal kann das Hardwaregerät in Ihrer Hand auch im Bereich KI seine Muskeln spielen lassen.
Durch die Kombination von iPhone, iPad und Macbook können Sie eine „heterogene Cluster-Inferenzlösung“ zusammenstellen und dann das Llama3-Modell reibungslos ausführen.

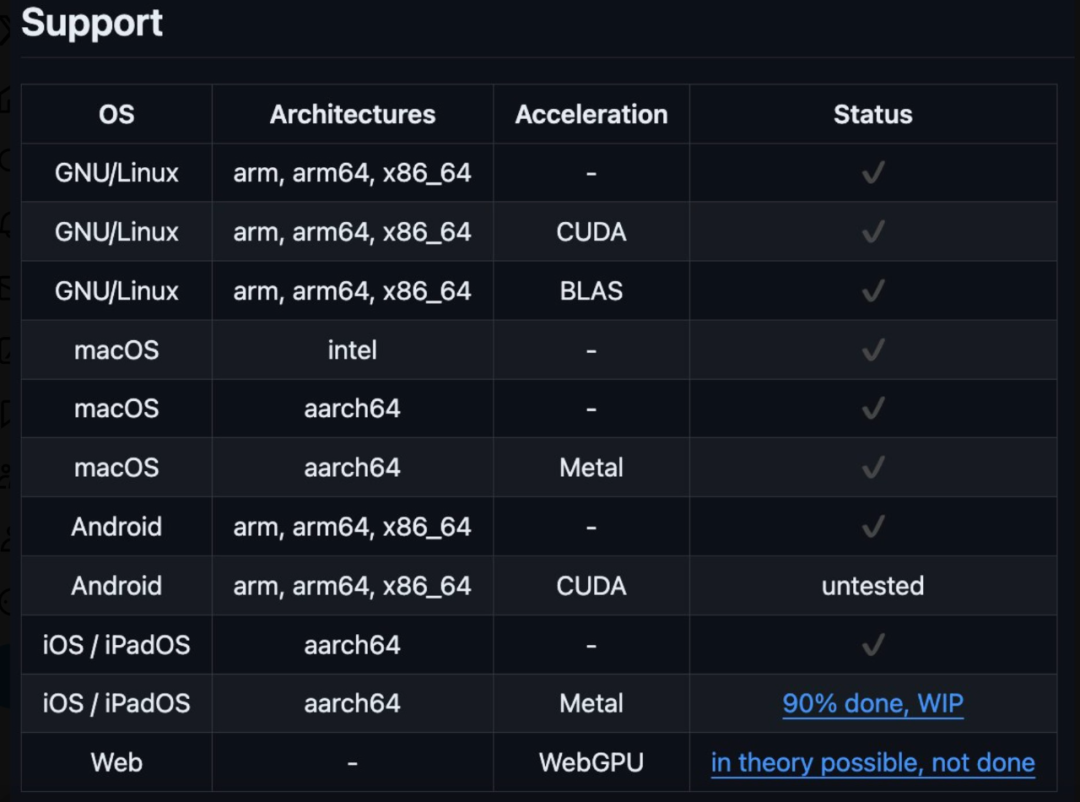
Es ist erwähnenswert, dass dieser heterogene Cluster ein Windows-, Linux- oder iOS-System sein kann und die Unterstützung für Android bald verfügbar sein wird. Der heterogene Cluster wird ausgeführt.
 Laut dem Projektautor @evilsocket umfasst dieser heterogene Cluster iPhone 15 Pro Max, iPad Pro, MacBook Pro (M1 Max), NVIDIA GeForce 3080, 2x NVIDIA Titan X Pascal. Der gesamte Code wurde auf GitHub hochgeladen. Als die Internetnutzer dies sahen, äußerten sie, dass dieser alte Mann tatsächlich nicht einfach sei.
Laut dem Projektautor @evilsocket umfasst dieser heterogene Cluster iPhone 15 Pro Max, iPad Pro, MacBook Pro (M1 Max), NVIDIA GeForce 3080, 2x NVIDIA Titan X Pascal. Der gesamte Code wurde auf GitHub hochgeladen. Als die Internetnutzer dies sahen, äußerten sie, dass dieser alte Mann tatsächlich nicht einfach sei.
Einige Internetnutzer beginnen jedoch, sich Sorgen über den Energieverbrauch zu machen. Unabhängig von der Geschwindigkeit kann die Stromrechnung nicht bezahlt werden. Das Hin- und Herschieben von Daten verursacht zu viel Verlust.


Projektadresse: https://github.com/evilsocket/cake
Die Hauptidee von Cake besteht darin, Transformatorblöcke auf mehrere Geräte aufzuteilen, um Inferenzen auf Modelle ausführen zu können, die normalerweise nicht hineinpassen der GPU-Speicher eines einzelnen Geräts. Der Rückschluss auf aufeinanderfolgende Transformatorblöcke im selben Arbeitsthread erfolgt stapelweise, um durch die Datenübertragung verursachte Verzögerungen zu minimieren. 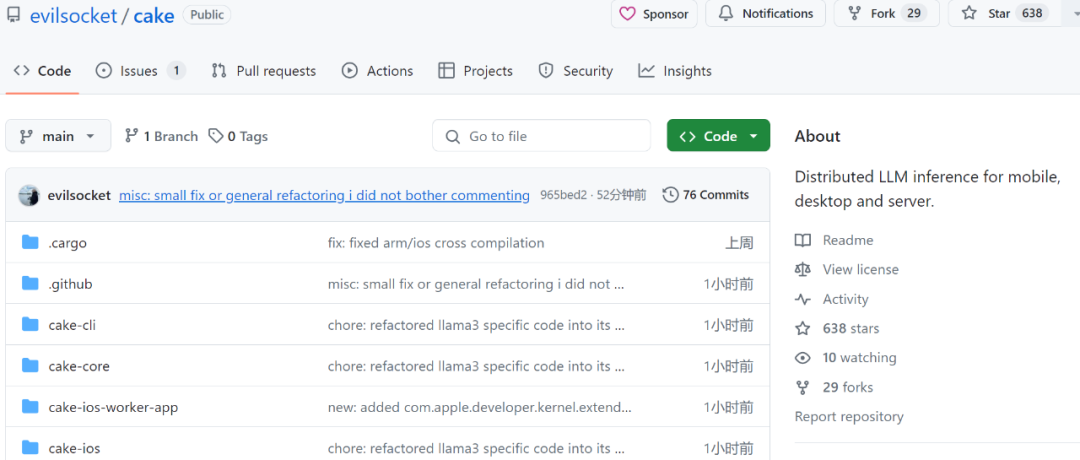
cargo build --release
Nach dem Login kopieren
make ios
Verwenden Sie
, um den Worker-Knoten auszuführen:cake-cli --model /path/to/Meta-Llama-3-8B \ # model path, read below on how to optimize model size for workers --mode worker \# run as worker --name worker0 \ # worker name in topology file --topology topology.yml \# topology --address 0.0.0.0:10128 # bind address
Nach dem Login kopieren
cake-cli --model /path/to/Meta-Llama-3-8B \ --topology topology.yml
linux_server_1:host: 'linux_server.host:10128'description: 'NVIDIA Titan X Pascal (12GB)'layers:- 'model.layers.0-5'linux_server_2:host: 'linux_server2.host:10128'description: 'NVIDIA GeForce 3080 (10GB)'layers:- 'model.layers.6-16'iphone:host: 'iphone.host:10128'description: 'iPhone 15 Pro Max'layers:- 'model.layers.17'ipad:host: 'ipad.host:10128'description: 'iPad'layers:- 'model.layers.18-19'macbook:host: 'macbook.host:10128'description: 'M1 Max'layers: - 'model.layers.20-31'
cake-split-model --model-path path/to/Meta-Llama-3-8B \ # source model to split --topology path/to/topology.yml \# topology file --output output-folder-name
Das obige ist der detaillierte Inhalt vonso cool! Alte iPhone-, iPad- und MacBook-Geräte bilden einen heterogenen Cluster und können Llama 3 ausführen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Software ist Xiaohongshu?
Welche Software ist Xiaohongshu?
 Was ist C#?
Was ist C#?
 HTML-Online-Editor
HTML-Online-Editor
 Tutorial zur Verschlüsselung von Word-Dokumenten
Tutorial zur Verschlüsselung von Word-Dokumenten
 So reinigen Sie das zu volle Laufwerk C des Computers
So reinigen Sie das zu volle Laufwerk C des Computers
 Wie ist die Leistung von thinkphp?
Wie ist die Leistung von thinkphp?
 Anleitung zur Herstellung beschrifteter Münzen
Anleitung zur Herstellung beschrifteter Münzen
 Was bedeutet es, eine Verbindung zu Windows herzustellen?
Was bedeutet es, eine Verbindung zu Windows herzustellen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



