


… oder mit anderen Worten, der dümmste Weg, in eingebettete Systeme einzusteigen.
Sehen Sie es sich hier in Aktion an!
Das Ziel war einfach. Schreiben Sie Code in C oder C++ und führen Sie ihn in Scratch aus. Ehrlich gesagt fand ich die Idee einfach ziemlich lustig: eine der schnellsten Programmiersprachen in einer der langsamsten. Ich hatte das Gefühl, dass es möglich war, aber ich war mir nicht ganz sicher, wie. Dabei habe ich viel mehr über Assemblersprachen, Prozessspeicher und ausführbare Dateien gelernt, als ich erwartet hatte, und ich hoffe, dass Sie etwas Neues lernen, während ich von meiner Reise erzähle.
Meine erste Idee bestand darin, den Code, den ich in C geschrieben habe, in Teile zu zerlegen und diese Teile dann mit Scratch wieder zusammenzusetzen. Beispielsweise könnte eine while-Schleife in C zu einem Wiederholungsblock in Scratch:
werden
Damit ein C-Compiler Code verstehen kann, muss er zunächst einen AST (abstrakten Syntaxbaum) generieren, bei dem es sich um eine Baumdarstellung jedes wichtigen Symbols im Quellcode handelt. Beispielsweise könnten eine öffnende Klammer, der Name einer Variablen oder das Schlüsselwort „return“ jeweils in unterschiedliche Knoten umgewandelt werden. Nachdem ich mir jedoch den AST für ein einfaches Fibonacci-Zahlenprogramm angesehen habe …
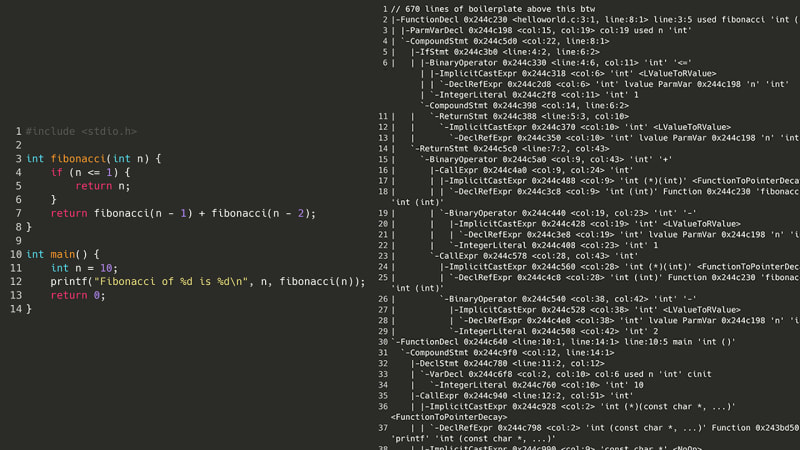
Okay, das kam also nicht in Frage. Aber was wäre, wenn wir, anstatt zu versuchen, den Quellcode neu zu kompilieren, einen Schritt nach unten gehen würden: die Assemblierung? Damit ein Programm ausgeführt werden kann, muss es zunächst in eine Assembly kompiliert werden. Auf meinem Computer ist das x86-64asm. Da Assembly keine komplizierten verschachtelten Strukturen, Klassen oder gar Variablen hat, sollte der Versuch, eine Liste von Assembleranweisungen zu analysieren, (theoretisch) einfacher sein als der Versuch, das Spaghetti-Monster eines AST wie das obige zu analysieren. Hier ist das gleiche Fibonacci-Programm, aber in x86-Assembly.
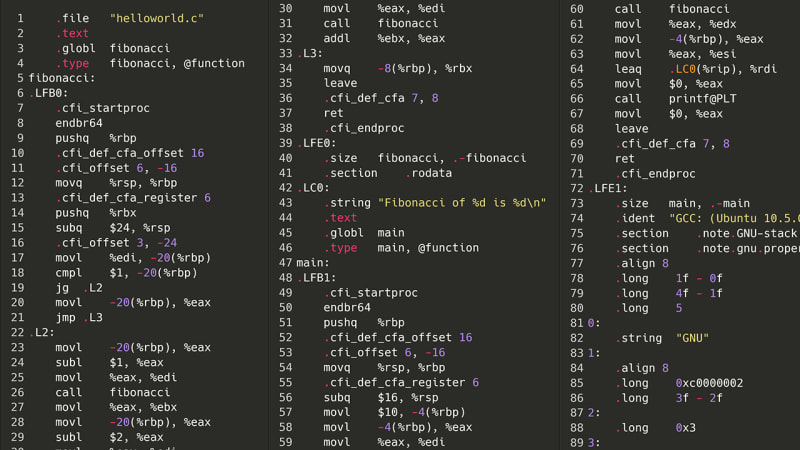
Oh, Bruder. Okay, vielleicht ist es nicht so schlimm. Wie viele Anleitungen gibt es insgesamt?
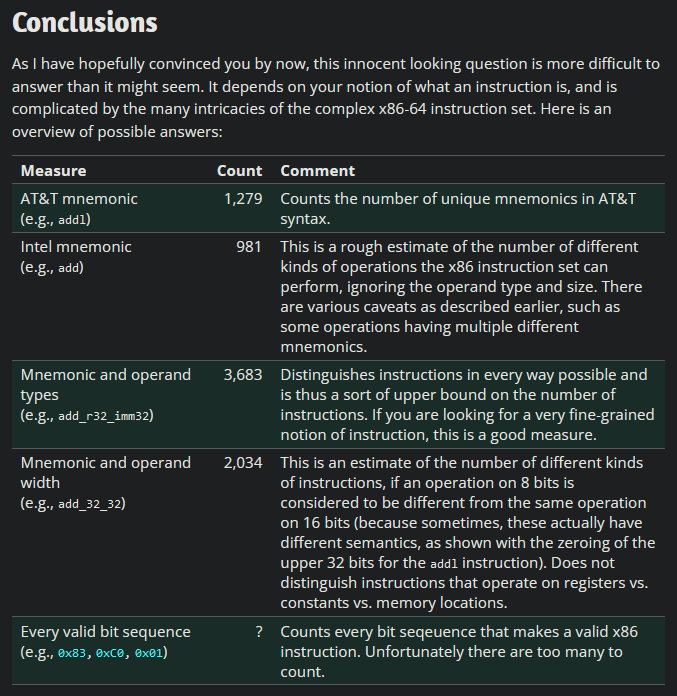
Zum Glück ist x86 nicht die einzige Assemblersprache, die es gibt. Als Teil eines College-Kurses lernte ich etwas über MIPS, eine Art Assemblersprache (zu stark vereinfachend), die in den 90er- bis frühen 2000er-Jahren in einigen Videospielkonsolen und Supercomputern verwendet wurde und auch heute noch Verwendung findet. Durch den Wechsel von x86 zu MIPS sinkt der Befehlszähler von *unbekannt* auf etwa 50.
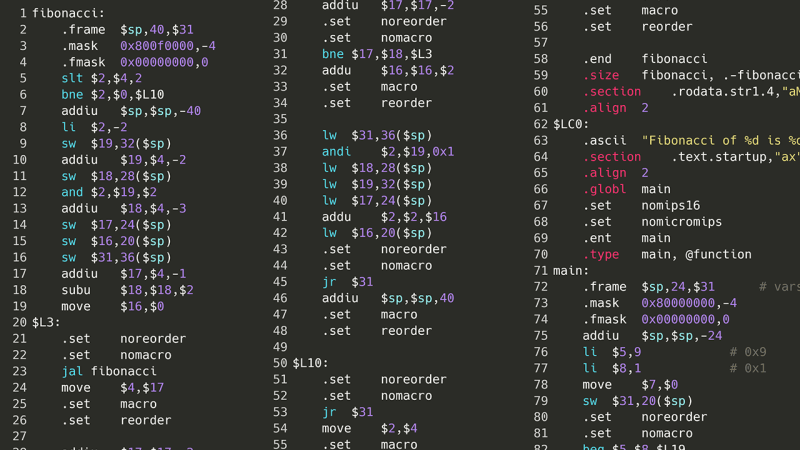
Mit einer 32-Bit-Version von MIPS kann dieser Assemblercode dann in Maschinencode umgewandelt werden, wobei jede Anweisung in eine 32-Bit-Ganzzahl umgewandelt wird, die der Prozessor verstehen kann, basierend auf Richtlinien, die von der Architektur des Prozessors festgelegt werden. Es gibt online ein Buch über die MIPS-Befehlssatzarchitektur. Wenn ich also den Maschinencode nehme und dann genau nachmache, was ein MIPS-Prozessor tun würde, sollte ich meinen C-Code in Scratch ausführen können!

Da das nun geklärt ist, können wir loslegen.
Nun, es gibt bereits ein Problem. Wenn Sie eine ganze Zahl haben und daraus eine Reihe von Bits extrahieren möchten, berechnen Sie normalerweise num & mask, wobei mask eine ganze Zahl ist, in der jedes wichtige Bit 1 und jedes unwichtige Bit 0,
ist001000 01001 01000 1111111111111100 & 000000 00000 00000 1111111111111111 -------------------------------------- 000000 0000 000000 1111111111111100
Das Problem? In Scratch.
gibt es keinen &-OperatorJetzt *könnte* ich einfach beide Zahlen Stück für Stück durchgehen und jede der vier möglichen Kombinationen von zwei Bits überprüfen, aber das wäre verschwenderisch langsam; Schließlich muss dies für *jede *Anweisung mehrmals durchgeführt werden. Stattdessen habe ich mir einen besseren Plan ausgedacht.
Zuerst habe ich ein schnelles Python-Skript geschrieben, um x und y für jedes x und jedes y zwischen 0 und 255 zu berechnen.
for x in range(256): for y in range(256): print(x & y) 0 (0 & 0 == 0) 0 (0 & 1 == 0) 0 (0 & 2 == 0) ... 0 (0 & 255 == 0) 0 (1 & 0 == 0) 1 (1 & 1 == 1) 0 (1 & 2 == 0) ... 254 (255 & 254 == 254) 255 (255 & 255 == 255)
Um nun beispielsweise x und y für zwei 32-Bit-Ganzzahlen zu berechnen, können wir Folgendes tun:
Split x and y into four 8-bit integers (or bytes).
Check what first_byte_in_x & first_byte_in_y is by looking in the table generated from the Python script.
Similarly, look up what second_byte_in_x & second_byte_in_y is, and the third bytes, and the fourth bytes.
Take the results of each of these calculations, and put them together to get the result of x & y .

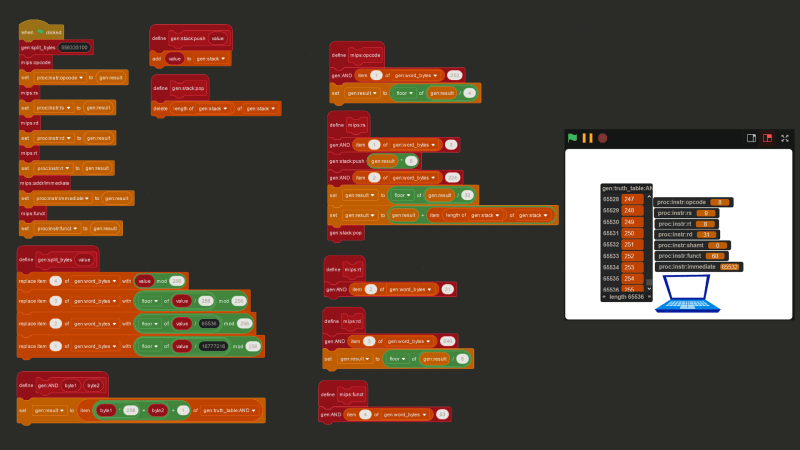
However, once a MIPS instruction has been cut up into four bytes, we’ll only & the bytes we need. For example, if we only need data from the first byte, we won’t even look at the bottom three. But how do we know which bytes we need? Based on the opcode (i.e. the “type”) of an instruction, MIPS will try to split up the bits of an instruction in one of three ways.

Putting everything together, below is the Scratch code to extract opcode, $rs, $rt, $rd, shamt, funct, and immediate for any instruction.
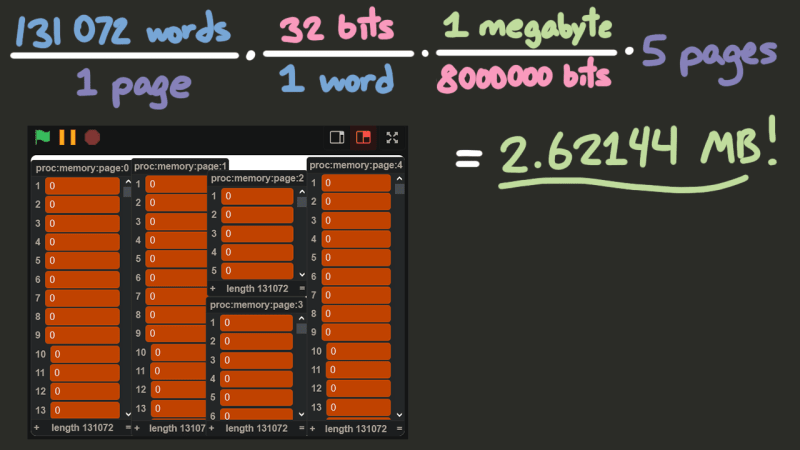
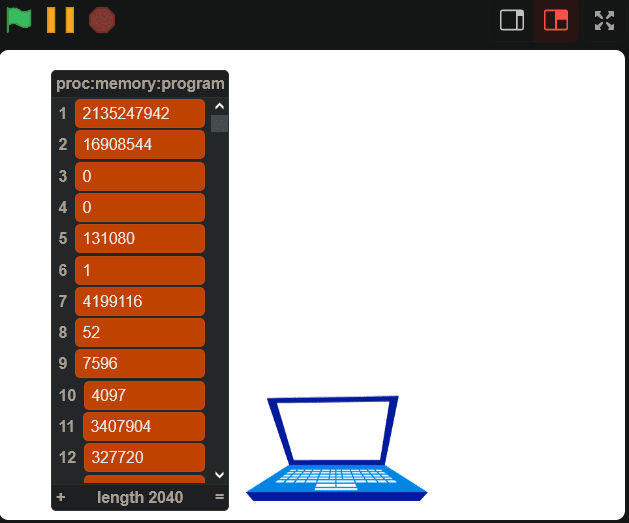
So, how much memory should our processor actually have? And how should we store it? Well, minimum, MIPS processors have 31 general-purpose registers, and one $zero register that is meant to store the number 0 at all times. A register is a location in memory that a processor can access quickly. We can represent these 32 registers as a list with 32 items in Scratch. As for the rest of the memory, simulating a processor moving chunks of data in and out of its cache in Scratch would be pretty pointless and would actually slow things down, rather than speed them up. So instead, the physical memory will be represented as five lists containing 131,072 elements each, where each element will be a 32-bit integer, giving us about 2.6MB of memory. A contiguous block of memory like these lists is usually called a “page”, and the size of the data that the instruction set works with (in this case 32 bits) is usually called a “word”.
So, how do we get machine code in here? We can’t just import a file into Scratch. But we *can *import text! So, I wrote a program in C to take a binary executable file, and convert every 32 bytes of the file into an integer. C, by default, was reading each byte in little-endian, so I had to introduce a function to flip the endianness. Then, I can save the machine code of a program as a text file (a list of integers), and then import it into my proc:memory:program variable.
#includeunsigned int flip_endian(unsigned int value) { return ((value >> 24) & 0xff) | ((value >> 8) & 0xff00) | ((value << 8) & 0xff0000) | ((value << 24) & 0xff000000); } int main(int argc, char* argv[]) { if (argc != 3 && argc != 2) { printf("Usage: %s
Okay, so now that we can import the data into Scratch, we can just set the program counter (the integer keeping track of the current instruction) to the top of the list, and start executing instructions, right?
Wrong.
I didn’t realize this going into this project, but the first several bytes of an executable file *aren’t *instructions, but a header identifying what type of executable file it is. On Windows, it’ll usually be the PE, or Portable Executable, format, and on UNIX-based systems (the version we’ll be using) it’ll be the ELF format. So, how do we actually know where the code starts? On Linux, we can use the builtin readelf utility to actually see what’s in the ELF header, and the Linux Foundation has a page detailing the ELF header standard. So, we can use the LF page to figure out which bytes mean what, and the readelf command to “check our work”.
$ readelf -h fibonacci ELF Header: Magic: 7f 45 4c 46 01 02 01 00 00 00 00 00 00 00 00 00 Class: ELF32 Data: 2's complement, big endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: MIPS R3000 Version: 0x1 Entry point address: 0x4012cc Start of program headers: 52 (bytes into file) Start of section headers: 7596 (bytes into file) Flags: 0x1001, noreorder, o32, mips1 Size of this header: 52 (bytes) Size of program headers: 32 (bytes) Number of program headers: 5 Size of section headers: 40 (bytes) Number of section headers: 14 Section header string table index: 13
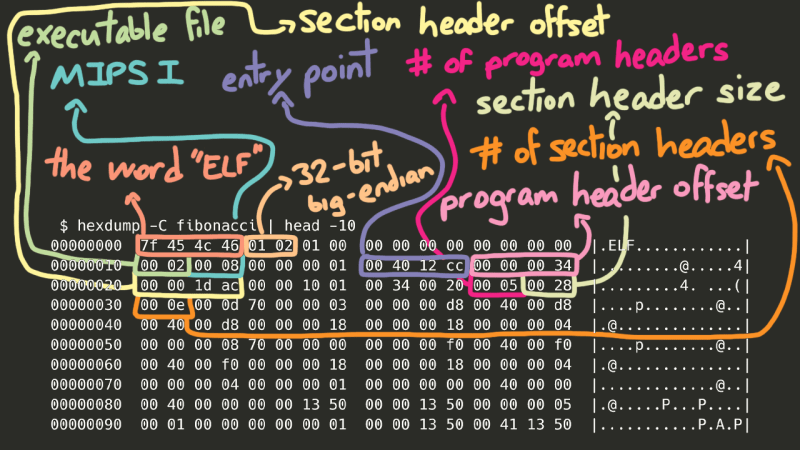
Now, there’s a lot of really interesting stuff here, but to save some time, the *really *important data here (besides the entry point, of course) are the section headers. Oversimplifying greatly, in order for our program to run correctly, we need to take certain chunks of the file and place them in certain parts of memory so our code can access them.

Using the readelf utility, we can actually see all of the sections in the file:
$ readelf -S fibonacci There are 14 section headers, starting at offset 0x1dac: Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .MIPS.abiflags MIPS_ABIFLAGS 004000d8 0000d8 000018 18 A 0 0 8 [ 2] .reginfo MIPS_REGINFO 004000f0 0000f0 000018 18 A 0 0 4 [ 3] .note.gnu.build-i NOTE 00400108 000108 000024 00 A 0 0 4 [ 4] .text PROGBITS 00400130 000130 001200 00 AX 0 0 16 [ 5] .rodata PROGBITS 00401330 001330 000020 00 A 0 0 16 [ 6] .bss NOBITS 00411350 001350 000010 00 WA 0 0 16 [ 7] .comment PROGBITS 00000000 001350 000029 01 MS 0 0 1 [ 8] .pdr PROGBITS 00000000 00137c 000440 00 0 0 4 [ 9] .gnu.attributes GNU_ATTRIBUTES 00000000 0017bc 000010 00 0 0 1 [10] .mdebug.abi32 PROGBITS 00000000 0017cc 000000 00 0 0 1 [11] .symtab SYMTAB 00000000 0017cc 000380 10 12 14 4 [12] .strtab STRTAB 00000000 001b4c 0001db 00 0 0 1 [13] .shstrtab STRTAB 00000000 001d27 000085 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), I (info), L (link order), O (extra OS processing required), G (group), T (TLS), C (compressed), x (unknown), o (OS specific), E (exclude), p (processor specific)
Going through all the details of the ELF format could be its own multi-part write-up, but using the Linux Foundation page on section headers, I was able to decipher the section header bytes of the program, and copy all the important bytes from the proc:memory:program variable to the correct places in memory, by checking whether or not the section header had the ALLOCATE flag set.
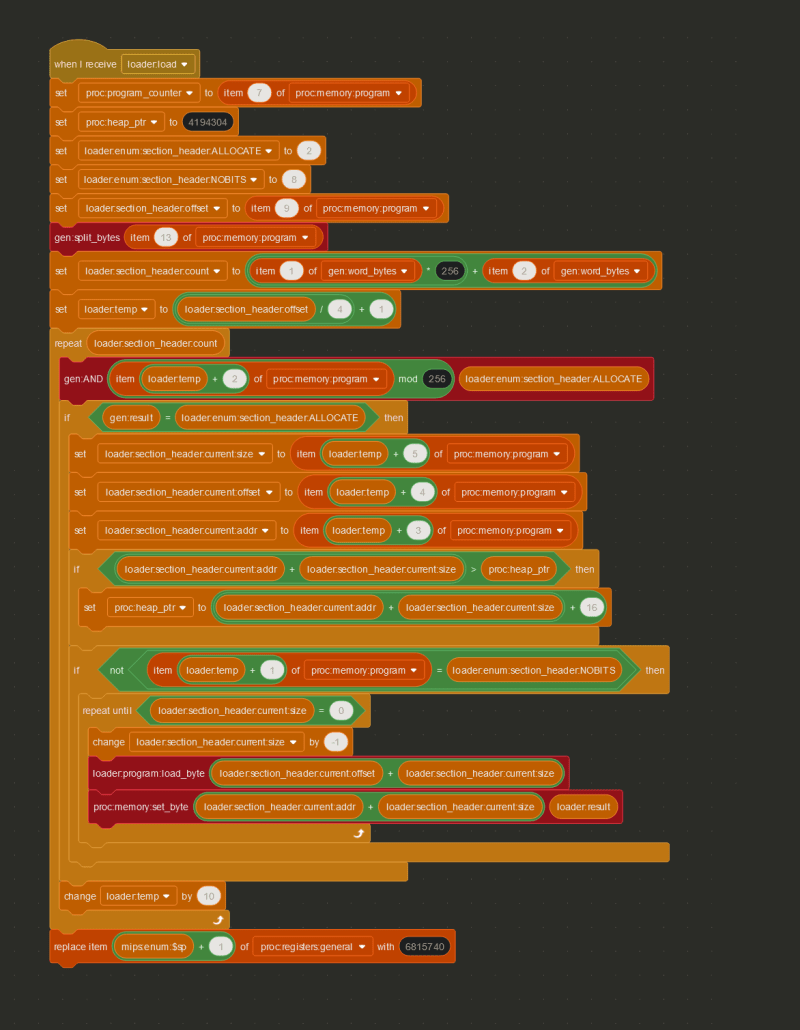
Fast-forwarding about a week to the point where all of the important instructions have been implemented, let’s take a look at the steps the processor (or really, any processor) needs to take in order to understand just one instruction, using 0x8D02002A (2365718570) as an example.
The first step is called **INSTRUCTION FETCH. **The current instruction is retrieved from the address stored in the proc:program_counter variable.
The next step isINSTRUCTION DECODE, where the instruction is decoded into its separate parts (see Step 1).
Finally, we reachEXECUTE, which, in my Scratch processor, is pretty much just a big if statement.
In this case, theINSTRUCTION DECODEstep revealed that the opcode is 35, which means 0x8D02002A is a lw (load word) instruction. Therefore, based off the values in proc:instr:rs, proc:instr:rt, and proc:instr:immediate, the instruction 0x8D02002A actually means lw $2, 0x2a($8) , or in other words, lw $v0, 42($t0).
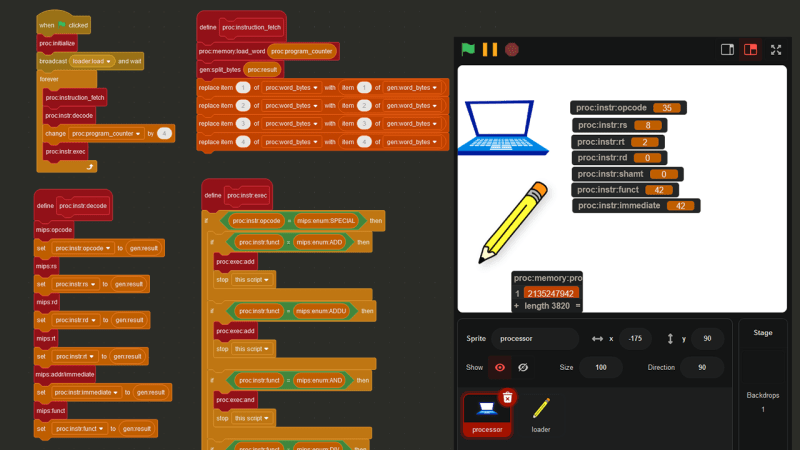
And here is the code that handles the lw instruction:
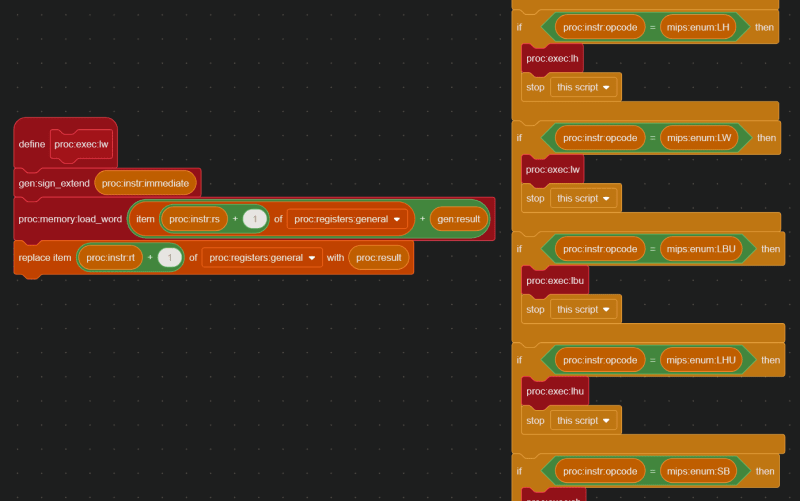
Okay, home stretch. Now, we just need to be able to do the bare minimum and create a “Hello, World” program in C, and run it in Scratch, and the last two weeks of my life will have been validated.
So, will this work?
#includeint main() { printf("Hello, world!"); return 0; }
Three changes. First of all, the MIPS linker usesstart to find the entry point of the program, much the same way you use main in C, or "main__" in Python. So, that’s an easy fix.
#includeint __start() { printf("Hello, world!"); return 0; }
Next, we need some way to actually see this output in Scratch. We *could *make some intricate array of text sprites, but the simpler solution is just to use a list.
Finally, we can’t use stdio.h.
Yeah, basically, implementing floating point registers and multiprocessor instructions would have been more trouble than it was worth, so I skipped it, but the standard library kind of expects all that to be there. So, we need to make printf ourselves.
Putting the complications of variadic arguments and text formatting aside, how can you actually print a string using MIPS? The TL;DR is you put the address of the string in a certain register, and then a special “print string” value in another register, and then execute the syscall (“system call”) instruction, and let the OS/CPU handle the rest.
The exact special values and registers to use are implementation-dependent, and can be implemented pretty much any way you see fit, but I chose to replicate MARS’ (a very popular MIPS simulator) implementation. With MARS, the address of the string goes in $a0, and the value 4 goes in $v0 to say “hey, I want to print a string!”
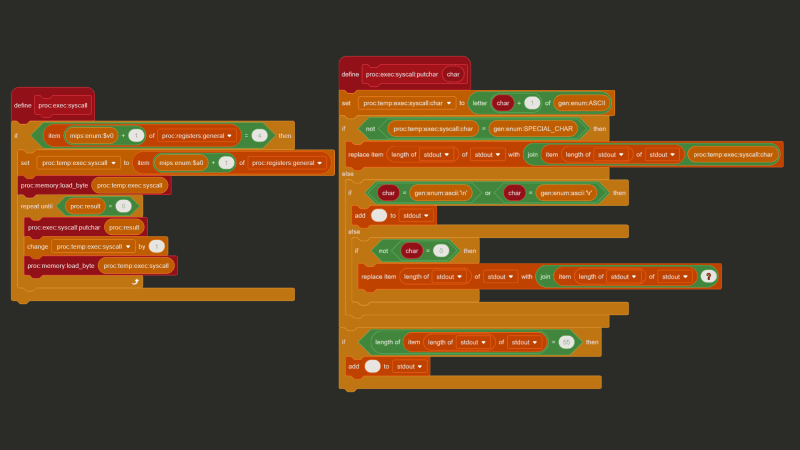
And with C, we can use a feature called “inline assembly” to inject assembly code directly into our compiled output. Putting it all together we get this:
#define puts _puts void _puts(const char *s) { __asm__( "li $v0, 4\n" "syscall\n" : : "a"(s) ); } int __start() { puts("Hello, World!\n"); return 0; }
And when we run it, we get this:
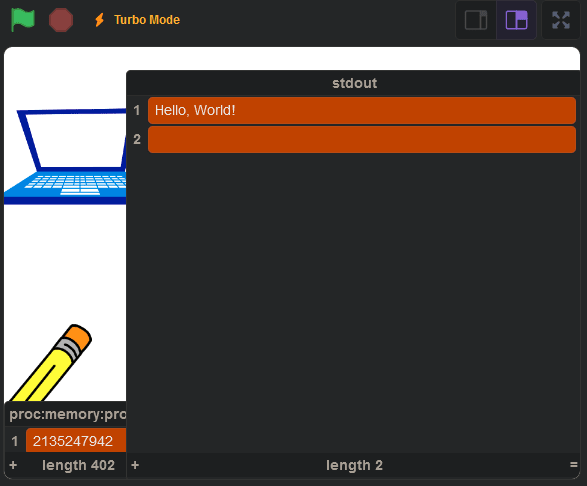
You can view the final product here: https://scratch.mit.edu/projects/1000840481/.
I wanted to keep this read under 15 minutes, so I had to skip over **a lot **of details. Some parts of the Scratch code had to be cut out of the screenshots for simplicity’s sake and I ran into a lot of silly and not-so-silly mistakes. If you’re curious how I was able to get Connect Four working (with minimax and alpha-beta pruning), the source code is on my Github. Here’s a quick list of some of the other problems I ran into in development:
* The fact that my computer is little-endian, but MIPS is big-endian caused more issues than I'd like to admit * The `mult` instruction in MIPS is 32-bit multiplication, and multiplying two 32-bit integers can result in a 64-bit integer. Javascript (and as a result, Scratch) is incapable of storing a 64-bit integer without losing precision. * The `u` in the `addu` instruction and the `u` in the `sltu` instruction both stand for "unsigned", but mean completely different things. * As you may have noticed, functions in Scratch don't have return values. This was quite annoying. * Any branch instruction (like "jump", "jump register", "branch on equals") in MIPS will also execute the instruction immediately after it, **regardless** of if the branch was taken or not. So, instead of updating the program count directly, the next address needs to be put in the "branch delay slot" and the program counter should only be updated after the *next* instruction. * Lists in Scratch are one-indexed. * All of a sudden, Scratch stopped letting me save the project to the cloud. It took awhile before I realized that lists filled with over 100,000 items wasn't something Scratch's servers were particularly excited to store. * I had to design my own `malloc` in C, which was fun, but also very difficult to debug in Scratch. * When I tried making syscalls that asked the user for input, all of the letters ended up capitalized. It turns out that in Scratch a lowercase `"a"` and a capital `"A"` are considered equal. I thought this was an unsolvable problem for awhile, before I realized that the names of sprites' costumes in Scratch are actually case-sensitive. So every time I try to convert a character to its ASCII value, I tell the processor sprite to switch to, for example, the `"a"` costume or the `"A"` costume, and then retrieve the costume number. * I made another syscall to print emojis to the `stdout`, but some emojis are considered two characters long and other emojis are considered one character long. * Compiling any code that calls `malloc` with -O1 crashes the CPU. I still have no idea why this is the case. * Endianness is really hard to get right. I know I said this in the beginning of the list, but it's worth repeating.
With all that said, I’m really happy with the way this project turned out. If you found this interesting, please check outsharc, my graphics engine built completely in Typescript: https://www.sharcjs.org. Because clearly, if there’s one thing I know how to make, it’s questionable decisions.
Das obige ist der detaillierte Inhalt vonEinen Computer in einer Programmiersprache für Kinder bauen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche virtuellen Währungen könnten im Jahr 2024 stark ansteigen?
Welche virtuellen Währungen könnten im Jahr 2024 stark ansteigen? So stellen Sie den Zigarettenkopf im WIN10-System ein, vgl
So stellen Sie den Zigarettenkopf im WIN10-System ein, vgl So verwandeln Sie zwei Seiten in ein Word-Dokument
So verwandeln Sie zwei Seiten in ein Word-Dokument Was bedeutet Chrom?
Was bedeutet Chrom? Was ist der Unterschied zwischen j2ee und springboot?
Was ist der Unterschied zwischen j2ee und springboot? xenserver
xenserver Wie lautet der chinesische Name der Fil-Münze?
Wie lautet der chinesische Name der Fil-Münze? So stellen Sie Daten nach der Formatierung wieder her
So stellen Sie Daten nach der Formatierung wieder her
























