



Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der Autor dieses Artikels, Xiao Zhenzhong, ist Doktorand am Max-Planck-Institut für Intelligente Systeme und der Universität Tübingen in Deutschland, und Robert Bamler ist Doktorand an der Universität Tübingen, Professor für maschinelles Lernen an der Universität, Bernhard Schölkopf ist Direktor des Max-Planck-Instituts für Intelligente Systeme und Liu Weiyang ist Forscher im Max-Planck-Institut für Cambridge Joint Project.

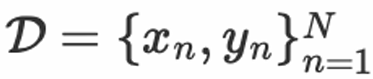 , ein Funktionsmodell
, ein Funktionsmodell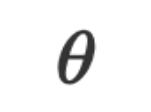 durch Optimierung von Parametern
durch Optimierung von Parametern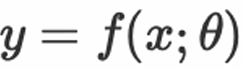 genau zu beschreiben die Beziehung zwischen
genau zu beschreiben die Beziehung zwischen 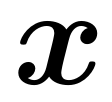 und
und 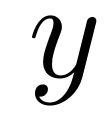 im Trainingssatz und Testsatz. Darunter ist
im Trainingssatz und Testsatz. Darunter ist 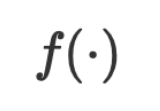 eine Funktion, die auf numerischen Werten basiert. Ihre Parameter
eine Funktion, die auf numerischen Werten basiert. Ihre Parameter  sind normalerweise numerische Vektoren oder Matrizen im kontinuierlichen Raum. Der Optimierungsalgorithmus aktualisiert iterativ, indem er den numerischen Gradienten berechnet, um den Lerneffekt zu erzielen.
sind normalerweise numerische Vektoren oder Matrizen im kontinuierlichen Raum. Der Optimierungsalgorithmus aktualisiert iterativ, indem er den numerischen Gradienten berechnet, um den Lerneffekt zu erzielen.  im natürlichen Sprachraum, und die Daten
im natürlichen Sprachraum, und die Daten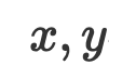 und Parameter
und Parameter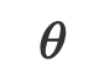 sind beide Strings im natürlichen Sprachraum. Bei der Inferenz können wir die gegebenen Eingabedaten
sind beide Strings im natürlichen Sprachraum. Bei der Inferenz können wir die gegebenen Eingabedaten 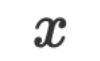 und Parameter
und Parameter  an LLM übermitteln, und die Antwort des LLM ist die Antwort auf die Inferenz
an LLM übermitteln, und die Antwort des LLM ist die Antwort auf die Inferenz 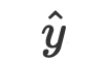 .
.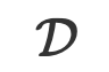 , wie bekommen wir ? Beim traditionellen maschinellen Lernen basierend auf numerischen Werten aktualisieren wir die vorhandenen Modellparameter in Richtung abnehmender Verluste, indem wir den Gradienten der Verlustfunktion berechnen und so die Optimierungsfunktion von erhalten:
, wie bekommen wir ? Beim traditionellen maschinellen Lernen basierend auf numerischen Werten aktualisieren wir die vorhandenen Modellparameter in Richtung abnehmender Verluste, indem wir den Gradienten der Verlustfunktion berechnen und so die Optimierungsfunktion von erhalten: 
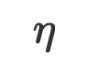 und
und 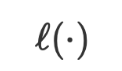 die Lernrate bzw. die Verlustfunktion sind.
die Lernrate bzw. die Verlustfunktion sind.  und Parameter in der VML-Umgebung beide Zeichenfolgen sind und LLM als Black-Box-Inferenz-Engine betrachtet wird, können wir nicht durch numerische Berechnungen optimieren. Aber da wir LLM als allgemeine Näherungsfunktion im Raum natürlicher Sprache verwendet haben, um die Modellfunktion anzunähern, und der Optimierer von auch eine Funktion ist, warum verwenden wir nicht auch LLM, um sie anzunähern? Daher kann die verbale
und Parameter in der VML-Umgebung beide Zeichenfolgen sind und LLM als Black-Box-Inferenz-Engine betrachtet wird, können wir nicht durch numerische Berechnungen optimieren. Aber da wir LLM als allgemeine Näherungsfunktion im Raum natürlicher Sprache verwendet haben, um die Modellfunktion anzunähern, und der Optimierer von auch eine Funktion ist, warum verwenden wir nicht auch LLM, um sie anzunähern? Daher kann die verbale 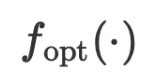 -Optimierungsfunktion als
-Optimierungsfunktion als 
 sind und
sind und 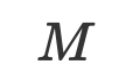 die Parameter der Optimierungsfunktion sind (dasselbe gilt für natürliche Sprache).
die Parameter der Optimierungsfunktion sind (dasselbe gilt für natürliche Sprache). 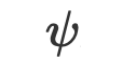
 Abbildung 1: Trainingsalgorithmus von VML.
Abbildung 1: Trainingsalgorithmus von VML.
und der Optimierer  in der Regressionsaufgabe.
in der Regressionsaufgabe. 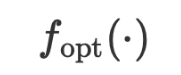


während des Trainingsprozesses automatisch die Funktionsfamilie des Modells auswählen. (3) Die Optimierungsfunktion liefert für jede Aktualisierung der Modellparameter eine Erklärung und Begründung in natürlicher Sprache Die Modelle sind ebenfalls natürlichsprachlich und erklärbar. einen größeren Wertebereich als  eine nichtlineare Beziehung besteht und
eine nichtlineare Beziehung besteht und  , daher wurde beschlossen, das Modell auf eine quadratische Funktion zu aktualisieren.
, daher wurde beschlossen, das Modell auf eine quadratische Funktion zu aktualisieren.

 sind beide als zweite Klassifizierung von Bildern definiert, aber eines von ihnen fügte einen Satz hinzu: „Als Eingabe wird ein Röntgenbild verwendet.“ zur Lungenentzündungserkennung.“ der induktiven Vorspannung von vornherein. Nach fünfzig Trainingsschritten erreichten beide Modelle eine Genauigkeit von etwa 75 %, wobei das Modell mit Prior etwas genauer war.
sind beide als zweite Klassifizierung von Bildern definiert, aber eines von ihnen fügte einen Satz hinzu: „Als Eingabe wird ein Röntgenbild verwendet.“ zur Lungenentzündungserkennung.“ der induktiven Vorspannung von vornherein. Nach fünfzig Trainingsschritten erreichten beide Modelle eine Genauigkeit von etwa 75 %, wobei das Modell mit Prior etwas genauer war. 
Das obige ist der detaillierte Inhalt vonKann maschinelles Lernen allein durch Sprechen ohne numerische Berechnungen durchgeführt werden? Ein neues ML-Paradigma, das auf natürlicher Sprache basiert, steht vor der Tür. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie HTML-Dateien
So öffnen Sie HTML-Dateien
 Tutorial zur Linux-Systeminstallation
Tutorial zur Linux-Systeminstallation
 Analyse der ICP-Münzaussichten
Analyse der ICP-Münzaussichten
 Thunder VIP-Patch
Thunder VIP-Patch
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
 So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Virtuelle Währungsumtauschplattform
Virtuelle Währungsumtauschplattform








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



