


Die Erkennung von 3D-Punktwolkenobjekten ist für die Wahrnehmung beim autonomen Fahren von entscheidender Bedeutung. Das effiziente Erlernen der Merkmalsdarstellung aus spärlichen Punktwolkendaten ist eine zentrale Herausforderung im Bereich der 3D-Punktwolkenobjekterkennung . In diesem Artikel stellen wir das vom Team in NeurIPS 2023 veröffentlichte HEDNet und das in CVPR 2024 veröffentlichte SAFDNet vor. HEDNet konzentriert sich auf die Lösung des Problems, dass bestehende spärliche Faltungs-Neuronale Netze die Abhängigkeiten zwischen Langstreckenmerkmalen nur schwer erfassen können, während SAFDNet aufgebaut ist Basierend auf HEDNet. Reiner Detektor für spärliche Punktwolken. Bei der Erkennung von Punktwolkenobjekten basieren herkömmliche Methoden häufig auf manuell entwickelten Merkmalsextraktoren, die bei der Verarbeitung spärlicher Punktwolkendaten nur begrenzt wirksam sind. In den letzten Jahren haben Deep-Learning-basierte Methoden in diesem Bereich erhebliche Fortschritte gemacht. HEDNet verwendet Faltungs-Neuronale Netze, um Merkmale aus spärlichen Punktwolkendaten zu extrahieren, und löst Schlüsselprobleme in spärlichen Punktwolkendaten durch eine spezifische Netzwerkstruktur, z. B. die Erfassung der Abhängigkeiten zwischen Merkmalen über große Entfernungen. Diese Methode ist in der Arbeit von NeurIPS 2023 enthalten. Die meisten existierenden spärlichen Faltungsnetze werden hauptsächlich durch Stapeln von Submanifold-Mannigfaltigkeitsmodulen (SSR) aufgebaut. Jedes SSR-Modul enthält zwei Submanifold-Faltungen unter Verwendung kleiner Faltungskerne (Submanifold Sparse, SS). Allerdings erfordert die Untermannigfaltigkeitsfaltung, dass die Sparsität der Eingabe- und Ausgabe-Feature-Maps konstant bleibt, was das Modell daran hindert, die Abhängigkeiten zwischen entfernten Features zu erfassen. Eine mögliche Lösung besteht darin, die Untermannigfaltigkeitsfaltung im SSR-Modul durch eine reguläre Sparse-Faltung (RS) zu ersetzen. Mit zunehmender Netzwerktiefe führt dies jedoch zu einer Spärlichkeit niedrigerer Feature-Maps, was zu einem erheblichen Anstieg der Rechenkosten führt. Einige Forschungsversuche versuchen, spärliche Faltungs-Neuronale Netze oder Transformatoren auf Basis großer Faltungskerne zu verwenden, um die Abhängigkeiten zwischen Merkmalen über große Entfernungen zu erfassen. Diese Methoden bringen jedoch entweder keine Verbesserung der Genauigkeit oder erfordern höhere Rechenkosten. Zusammenfassend fehlt uns noch eine Methode, mit der die Abhängigkeiten zwischen entfernten Features effizient erfasst werden können.
Um die Modelleffizienz zu verbessern, verwenden die meisten vorhandenen 3D-Punktwolken-Objektdetektoren eine spärliche Faltung, um Merkmale zu extrahieren. Die spärliche Faltung umfasst hauptsächlich die RS-Faltung und die SS-Faltung. Durch die RS-Faltung werden spärliche Features während des Berechnungsprozesses auf benachbarte Bereiche verteilt, wodurch die Sparsität der Feature-Map verringert wird. Im Gegensatz dazu bleibt bei der SS-Faltung die Sparsität der Eingabe- und Ausgabe-Feature-Maps unverändert. Aufgrund des Rechenaufwands der RS-Faltung durch Reduzierung der Sparsität von Feature-Maps wird die RS-Faltung in bestehenden Methoden normalerweise nur für das Downsampling von Feature-Maps verwendet. Andererseits bauen die meisten elementbasierten Methoden spärliche Faltungs-Neuronale Netze auf, indem sie SSR-Module stapeln, um Punktwolkenmerkmale zu extrahieren. Jedes SSR-Modul enthält zwei SS-Faltungen und eine Sprungverbindung, die Eingabe- und Ausgabefunktionen zusammenführt.
Das Designziel des SED-Moduls besteht darin, die Einschränkungen des SSR-Moduls zu überwinden. Das SED-Modul verkürzt den räumlichen Abstand zwischen entfernten Features durch Feature-Downsampling und stellt gleichzeitig die verlorenen Detailinformationen durch Multiskalen-Feature-Fusion wieder her. Abbildung 1(c) zeigt ein Beispiel eines SED-Moduls mit zwei Merkmalsskalen. Dieses Modul verwendet zunächst eine 3x3-RS-Faltung mit einem Schritt von 3 für das Feature-Downsampling (Down). Nach dem Feature-Downsampling werden die getrennten effektiven Features in der unteren Feature-Map in die mittlere Feature-Map und angrenzende effektive Features integriert. Anschließend wird die Interaktion zwischen effektiven Features erreicht, indem ein SSR-Modul verwendet wird, um Features auf der Zwischen-Feature-Map zu extrahieren. Schließlich werden die Zwischen-Feature-Maps einem Upsampling (UP) unterzogen, um sie an die Auflösung der Eingabe-Feature-Maps anzupassen. Es ist zu beachten, dass hier nur die Beispielmerkmale auf die Regionen hochgerechnet werden, die gültigen Merkmalen in der Eingabe-Feature-Karte entsprechen. Daher kann das SED-Modul die Sparsamkeit von Feature-Maps beibehalten. Das Designziel des SED-Moduls besteht darin, die Einschränkungen des SSR-Moduls zu überwinden. Das SED-Modul verkürzt den räumlichen Abstand zwischen entfernten Features durch Feature-Downsampling und stellt gleichzeitig die verlorenen Detailinformationen durch Multiskalen-Feature-Fusion wieder her. Abbildung 1(c) zeigt ein Beispiel eines SED-Moduls mit zwei Merkmalsskalen. Dieses Modul verwendet zunächst eine 3x3-RS-Faltung mit einem Schritt von 3 für das Feature-Downsampling (Down). Nach dem Feature-Downsampling werden die getrennten effektiven Features in der unteren Feature-Map in die mittlere Feature-Map und angrenzende effektive Features integriert. Anschließend wird die Interaktion zwischen effektiven Features erreicht, indem ein SSR-Modul verwendet wird, um Features auf der Zwischen-Feature-Map zu extrahieren. Schließlich werden die Zwischen-Feature-Maps einem Upsampling (UP) unterzogen, um sie an die Auflösung der Eingabe-Feature-Maps anzupassen. Es ist zu beachten, dass hier nur die Beispiel-Features auf die Regionen hochgerechnet werden, die gültigen Features in der Eingabe-Feature-Map entsprechen. Daher kann das SED-Modul die Sparsamkeit von Feature-Maps beibehalten. Das Designziel des SED-Moduls besteht darin, die Einschränkungen des SSR-Moduls zu überwinden. Das SED-Modul zeigt eine spezifische Implementierung des SED-Moduls mit drei charakteristischen Skalen. Die Zahl in Klammern stellt das Verhältnis der Auflösung der entsprechenden Feature-Map zur Auflösung der Eingabe-Feature-Map dar. Das SED-Modul verwendet eine asymmetrische Codec-Struktur, die den Encoder zum Extrahieren von Multiskalenmerkmalen verwendet und die extrahierten Multiskalenmerkmale schrittweise über den Decoder zusammenführt. Das SED-Modul verwendet RS-Faltung als Feature-Downsampling-Schicht und spärliche Dekonvolution als Feature-Upsampling-Schicht. Durch die Verwendung der Encoder-Decoder-Struktur erleichtert das SED-Modul die Informationsinteraktion zwischen getrennten Merkmalen im Raum und ermöglicht so dem Modell, die Abhängigkeiten zwischen entfernten Merkmalen zu erfassen.
Abbildung 2 SED- und DED-Modulstrukturen Andererseits verlassen sich die aktuellen gängigen 3D-Punktwolkendetektoren zur Vorhersage hauptsächlich auf Objektzentrumsmerkmale, in der vom spärlichen Faltungsnetzwerk extrahierten Merkmalskarte kann jedoch der Objektzentrumsbereich verwendet werden Vor allem in großen Objekten gibt es Löcher. Um dieses Problem zu lösen, schlagen wir das DED-Modul vor, dessen Struktur in Abbildung 2(b) dargestellt ist. Das DED-Modul hat die gleiche Struktur wie das SED-Modul, es ersetzt das SSR-Modul im SED-Modul durch ein Dense Residual (DR)-Modul und ersetzt die für das Feature-Downsampling verwendete RS-Faltung durch DR mit einem Schritt von 2 Modulen und ersetzt Sparse Dekonvolution für Feature-Upsampling mit dichter Dekonvolution. Diese Designs ermöglichen es dem DED-Modul, spärliche Merkmale effektiv in Richtung des zentralen Bereichs des Objekts zu verteilen.
Andererseits verlassen sich die aktuellen gängigen 3D-Punktwolkendetektoren zur Vorhersage hauptsächlich auf Objektzentrumsmerkmale, in der vom spärlichen Faltungsnetzwerk extrahierten Merkmalskarte kann jedoch der Objektzentrumsbereich verwendet werden Vor allem in großen Objekten gibt es Löcher. Um dieses Problem zu lösen, schlagen wir das DED-Modul vor, dessen Struktur in Abbildung 2(b) dargestellt ist. Das DED-Modul hat die gleiche Struktur wie das SED-Modul, es ersetzt das SSR-Modul im SED-Modul durch ein Dense Residual (DR)-Modul und ersetzt die für das Feature-Downsampling verwendete RS-Faltung durch DR mit einem Schritt von 2 Modulen und ersetzt Sparse Dekonvolution für Feature-Upsampling mit dichter Dekonvolution. Diese Designs ermöglichen es dem DED-Modul, spärliche Merkmale effektiv in Richtung des zentralen Bereichs des Objekts zu verteilen.

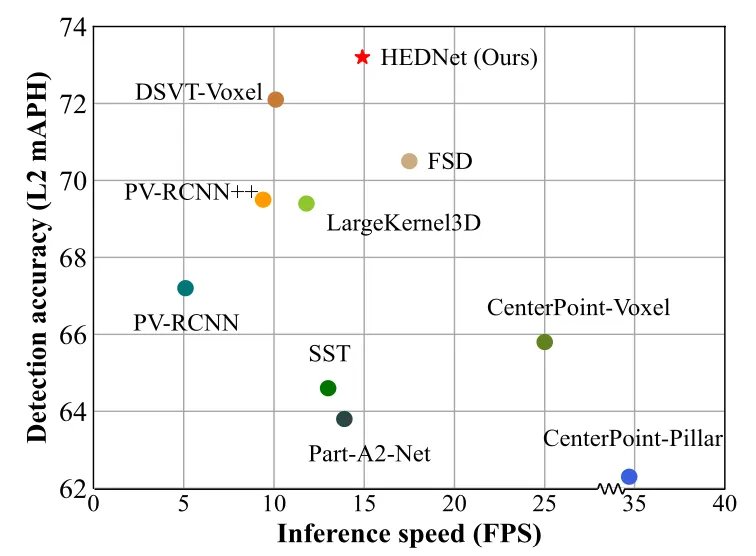
Abbildung 4 Umfassender Leistungsvergleich des Waymo Open-Datensatzes
Voxelbasierte Methoden konvertieren normalerweise spärliche Voxel-Features in dichte Feature-Maps und übergeben dann dichte Faltungsneuronale Netzwerke extrahieren Merkmale zur Vorhersage. Wir nennen diesen Detektortyp einen Hybriddetektor, und seine Struktur ist in Abbildung 5(a) dargestellt. Diese Art von Methode eignet sich gut für Erkennungsszenarien mit geringer Reichweite (<75 Meter), aber mit zunehmender Erfassungsreichweite steigen die Rechenkosten für die Verwendung dichter Feature-Maps dramatisch an, was ihre Verwendung bei Erkennungsszenarien mit großer Reichweite (>200 Meter) einschränkt. Erkennungsszenarien. Eine mögliche Lösung besteht darin, einen „reinen spärlichen Detektor“ zu bauen, indem die dichten Feature-Maps in vorhandenen Hybriddetektoren entfernt werden. Dies führt jedoch zu einer erheblichen Verschlechterung der Erkennungsleistung des Modells, da die meisten Hybriddetektoren derzeit auf Objektzentren basieren Wird zur Vorhersage verwendet, um Merkmale mit geringer Dichte zu extrahieren, ist der zentrale Bereich großer Objekte normalerweise leer. Dies ist das Problem des „fehlenden Objektzentrums“. Daher ist das Erlernen geeigneter Objektdarstellungen für den Aufbau rein spärlicher Detektoren von entscheidender Bedeutung.
Abbildung 5 Strukturvergleich von Hybriddetektor, FSDv1 und SAFDNet Um das Problem fehlender Objektzentrumsmerkmale zu lösen, unterteilt FSDv1 (Abbildung 5(b)) zunächst die ursprüngliche Punktwolke in Vordergrundpunkte und Hintergrundpunkte , und dann durch Der Mittelpunkt-Voting-Mechanismus gruppiert die Vordergrundpunkte und extrahiert Instanzmerkmale aus jedem Cluster für die anfängliche Vorhersage, die durch den Gruppenkorrekturkopf weiter verfeinert wird. Um die induktive Verzerrung zu reduzieren, die durch die manuelle Extraktion von Instanzmerkmalen entsteht, verwendet FSDv2 ein virtuelles Voxelisierungsmodul, um den Instanz-Clustering-Vorgang in FSDv1 zu ersetzen. Die FSD-Methodenreihe unterscheidet sich erheblich von weit verbreiteten Erkennungsframeworks wie CenterPoint und führt eine große Anzahl von Hyperparametern ein, was den Einsatz dieser Methoden in realen Szenarien schwierig macht. Im Gegensatz zur FSD-Methodenreihe prognostiziert VoxelNeXt direkt basierend auf den Voxelmerkmalen, die der Mitte des Objekts am nächsten liegen, beeinträchtigt jedoch die Erkennungsgenauigkeit.
Um das Problem fehlender Objektzentrumsmerkmale zu lösen, unterteilt FSDv1 (Abbildung 5(b)) zunächst die ursprüngliche Punktwolke in Vordergrundpunkte und Hintergrundpunkte , und dann durch Der Mittelpunkt-Voting-Mechanismus gruppiert die Vordergrundpunkte und extrahiert Instanzmerkmale aus jedem Cluster für die anfängliche Vorhersage, die durch den Gruppenkorrekturkopf weiter verfeinert wird. Um die induktive Verzerrung zu reduzieren, die durch die manuelle Extraktion von Instanzmerkmalen entsteht, verwendet FSDv2 ein virtuelles Voxelisierungsmodul, um den Instanz-Clustering-Vorgang in FSDv1 zu ersetzen. Die FSD-Methodenreihe unterscheidet sich erheblich von weit verbreiteten Erkennungsframeworks wie CenterPoint und führt eine große Anzahl von Hyperparametern ein, was den Einsatz dieser Methoden in realen Szenarien schwierig macht. Im Gegensatz zur FSD-Methodenreihe prognostiziert VoxelNeXt direkt basierend auf den Voxelmerkmalen, die der Mitte des Objekts am nächsten liegen, beeinträchtigt jedoch die Erkennungsgenauigkeit.
Wie sieht also der reine, spärliche Punktwolkendetektor aus, den wir wollen? Erstens sollte die Struktur einfach sein, damit sie direkt in praktische Anwendungen eingesetzt werden kann. Zweitens besteht eine intuitive Idee darin, minimale Änderungen vorzunehmen, um einen reinen Sparse-Detektor basierend auf der derzeit weit verbreiteten Hybrid-Detektorarchitektur zu erstellen Die Leistung muss mindestens mit den aktuell führenden Hybriddetektoren mithalten und auf verschiedene Bereiche von Erkennungsszenarien anwendbar sein.
Einführung in die MethodeDa die von Lidar erzeugte Punktwolke hauptsächlich auf der Oberfläche des Objekts verteilt ist, besteht bei der Verwendung eines reinen spärlichen Detektors zum Extrahieren von Features für die Vorhersage das Problem, dass Features in der Objektmitte fehlen. Kann der Detektor also Merkmale extrahieren, die näher am oder in der Mitte des Objekts liegen, und gleichzeitig die Merkmalssparsamkeit so weit wie möglich beibehalten? Eine intuitive Idee besteht darin, spärliche Merkmale auf benachbarte Voxel zu verteilen. Abbildung 6(a) zeigt ein Beispiel einer spärlichen Feature-Map. Der rote Punkt in der Abbildung stellt die Mitte des Objekts dar. Die dunkelorangen Quadrate sind nicht leere Voxel, deren geometrische Zentren innerhalb des Begrenzungsrahmens liegen Die dunkelblauen Quadrate sind nicht leere Voxel, deren geometrisches Zentrum außerhalb des Begrenzungsrahmens des Objekts liegt, und die weißen Quadrate sind leere Voxel. Jedes nicht leere Voxel entspricht einem nicht leeren Merkmal. Abbildung 7(b) wird durch gleichmäßige Diffusion der nicht leeren Merkmale in Abbildung 7(a) in die Umgebung von KxK (K ist 5) erhalten. Diffuse, nicht leere Voxel werden in hellorange oder hellblau angezeigt.
 Abbildung 7 Schematische Darstellung der einheitlichen Merkmalsdiffusion und der adaptiven Merkmalsdiffusion
Abbildung 7 Schematische Darstellung der einheitlichen Merkmalsdiffusion und der adaptiven Merkmalsdiffusion
Durch die Analyse der Ausgabe der spärlichen Feature-Map des 3D-Backbone-Netzwerks mit geringer Dichte stellen wir fest, dass: (a) weniger als 10 % der Voxel in den Begrenzungsrahmen fallen des Objekts; (b) Kleine Objekte haben normalerweise Nicht-Null-Merkmale in der Nähe oder auf ihrem zentralen Voxel. Diese Beobachtung legt nahe, dass die Verteilung aller Nicht-Null-Merkmale in einen Bereich gleicher Größe möglicherweise unnötig ist, insbesondere für Voxel innerhalb kleiner Objektbegrenzungsrahmen und in Hintergrundregionen. Daher schlagen wir eine adaptive Merkmalsdiffusionsstrategie vor, die den Diffusionsbereich basierend auf der Position von Voxelmerkmalen dynamisch anpasst. Wie in Abbildung 7(c) dargestellt, bringt diese Strategie Voxelmerkmale innerhalb des Begrenzungsrahmens großer Objekte näher an die Objektmitte, indem diesen Merkmalen ein größerer Diffusionsbereich zugewiesen wird, während gleichzeitig Voxelmerkmale innerhalb des Begrenzungsrahmens von zugewiesen werden kleinen Objekten und im Hintergrundbereich wird Voxelmerkmalen ein kleinerer Diffusionsbereich zugewiesen, um die Merkmalssparsamkeit so weit wie möglich beizubehalten. Um diese Strategie umzusetzen, ist eine Voxelklassifizierung (Voxelklassifizierung) erforderlich, um zu bestimmen, ob der geometrische Mittelpunkt eines nicht leeren Voxels innerhalb des Begrenzungsrahmens einer bestimmten Objektkategorie liegt oder zum Hintergrundbereich gehört. Weitere Einzelheiten zur Voxelklassifizierung finden Sie im Dokument. Durch die Verwendung einer adaptiven Merkmalsdiffusionsstrategie ist der Detektor in der Lage, die Merkmalssparsität so weit wie möglich aufrechtzuerhalten und so von einer effizienten Berechnung dünner Merkmale zu profitieren.
Wir haben die umfassende Leistung von SAFDNet mit den vorherigen besten Methoden verglichen und die Ergebnisse sind in Abbildung 8 dargestellt. Beim Waymo Open-Datensatz mit einem kleineren Erkennungsbereich erreichte SAFDNet eine vergleichbare Erkennungsgenauigkeit mit dem bisher besten reinen Sparse-Detektor FSDv2 und unserem vorgeschlagenen Hybriddetektor HEDNet, aber die Inferenzgeschwindigkeit von SAFDNet ist 2-mal so hoch wie die von FSDv2 und HEDNet 1,2-mal. Im Argoverse2-Datensatz mit großem Erkennungsbereich verbesserte SAFDNet den Indikator mAP um 2,1 % und erreichte im Vergleich zum Hybriddetektor HEDNet das 1,3-fache der Indikatorgeschwindigkeit mAP stieg um 2,6 % und die Inferenzgeschwindigkeit erreichte das 2,1-fache der von HEDNet. Darüber hinaus ist der Speicherverbrauch des Hybriddetektors HEDNet bei großem Erkennungsbereich viel größer als der des reinen Sparse-Detektors. Zusammenfassend lässt sich sagen, dass SAFDNet für verschiedene Erkennungsszenarien geeignet ist und eine hervorragende Leistung aufweist.

Abbildung 8 Wichtigste experimentelle Ergebnisse
SAFDNet ist eine Lösung für den Detektor für reine, spärliche Punktwolken. Gibt es also Probleme? Tatsächlich ist SAFDNet nur ein Zwischenprodukt unserer Idee eines reinen Sparse-Detektors. Der Autor ist der Meinung, dass es zu gewalttätig und nicht prägnant und elegant genug ist. Seien Sie gespannt auf unsere Folgearbeiten!
Die Codes von HEDNet und SAFDNet sind Open Source und jeder ist herzlich eingeladen, sie zu verwenden. Hier ist der Link: https://github.com/zhanggang001/HEDNet
Das obige ist der detaillierte Inhalt vonCVPR\'24 Oral |. Ein Blick auf die Vergangenheit und Gegenwart des reinen Punktwolkendetektors SAFDNet!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was macht Python?
Was macht Python?
 Wie lautet die Inschrift in der Blockchain?
Wie lautet die Inschrift in der Blockchain?
 Binäre Darstellung negativer Zahlen
Binäre Darstellung negativer Zahlen
 So überprüfen Sie den Speicher
So überprüfen Sie den Speicher
 Der Edge-Browser kann nicht suchen
Der Edge-Browser kann nicht suchen
 E-O Exchange herunterladen
E-O Exchange herunterladen
 Wie kann das Problem gelöst werden, dass für die Laptop-Netzwerkfreigabe keine Berechtigungen vorhanden sind?
Wie kann das Problem gelöst werden, dass für die Laptop-Netzwerkfreigabe keine Berechtigungen vorhanden sind?
 flac-Format
flac-Format








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



