Im Bereich der KI sind Skalierungsgesetze ein leistungsstarkes Werkzeug zum Verständnis von LM-Skalierungstrends. Sie bieten eine Richtlinie für Forscher. Dieses Gesetz bietet einen wichtigen Leitfaden für das Verständnis, wie sich die Leistung von Sprachmodellen mit der Skalierung ändert. Aber leider ist die Skalierungsanalyse in vielen Benchmarking- und Post-Training-Studien nicht üblich, da die meisten Forscher nicht über die Rechenressourcen verfügen, um Skalierungsgesetze von Grund auf zu erstellen, und die Trainingsskalen offener Modelle zu gering sind, um sie zuverlässig zu machen Expansionsprognosen. Forscher der Stanford University, der University of Toronto und anderen Institutionen haben eine alternative Beobachtungsmethode vorgeschlagen: Observational Scaling Laws, die die Funktionen von Sprachmodellen (LM) mit der Leistung über mehrere Modellfamilien hinweg kombiniert, anstatt nur innerhalb eines einzelne Reihen, wie es bei standardmäßigen rechnerischen Erweiterungsgesetzen der Fall ist. Diese Methode umgeht das Modelltraining und erstellt stattdessen Skalierungsgesetze basierend auf etwa 80 öffentlich verfügbaren Modellen. Dies führt jedoch zu einem weiteren Problem. Die Konstruktion eines einzelnen Expansionsgesetzes aus mehreren Modellfamilien stellt aufgrund der großen Unterschiede in der Trainingsrecheneffizienz und den Fähigkeiten zwischen verschiedenen Modellen große Herausforderungen dar. Dennoch zeigt die Studie, dass diese Änderungen mit einem einfachen, verallgemeinerten Skalierungsgesetz vereinbar sind, bei dem die Leistung des Sprachmodells eine Funktion des niedrigdimensionalen Fähigkeitsraums ist und sich die gesamte Modellfamilie nur in der Effizienz der Konvertierung unterscheidet Berechnungen in Fähigkeiten umwandeln. Mit der oben genannten Methode demonstriert diese Studie die erstaunliche Vorhersagbarkeit vieler anderer Arten von Erweiterungsstudien. Sie fanden heraus, dass: einige aufkommende Phänomene einem glatten Sigmoidalverhalten folgen und anhand kleiner Modelle wie der GPT-4-Agentenleistung vorhergesagt werden können von kann aus einfacheren Nicht-Agent-Benchmarks genau vorhergesagt werden. Darüber hinaus zeigt die Studie, wie sich die Auswirkungen von Interventionen nach dem Training wie Denkketten auf das Modell vorhersagen lassen. Untersuchungen zeigen, dass beobachtbare Expansionsgesetze, selbst wenn sie nur mit einem kleinen Sub-GPT-3-Modell angepasst werden, komplexe Phänomene wie Emergenzkapazität, Agentenleistung und Erweiterung von Post-Training-Methoden (z. B. Denkkette) genau vorhersagen.
- Papieradresse: https://arxiv.org/pdf/2405.10938
- Papiertitel: Observational Scaling Laws and the Predictability of Language Model Performance
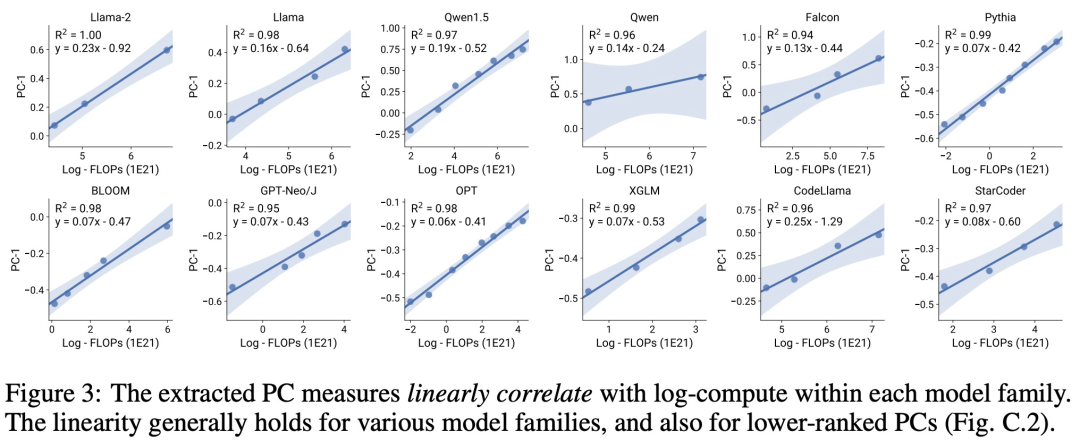
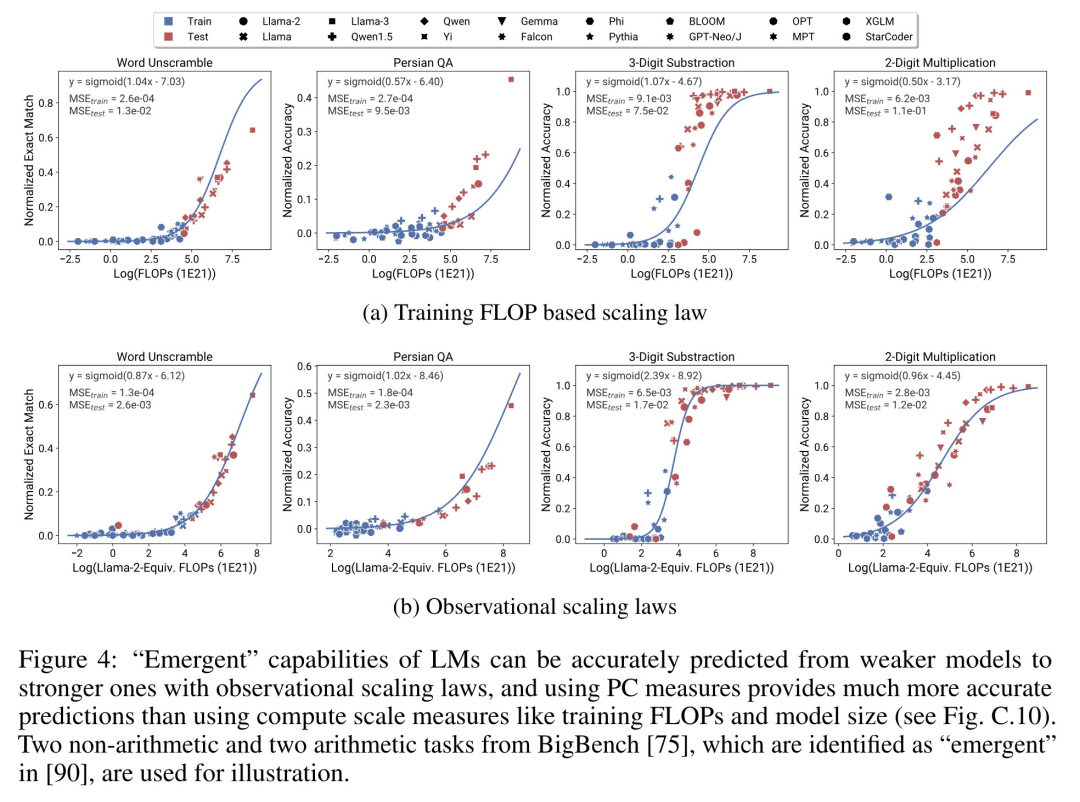
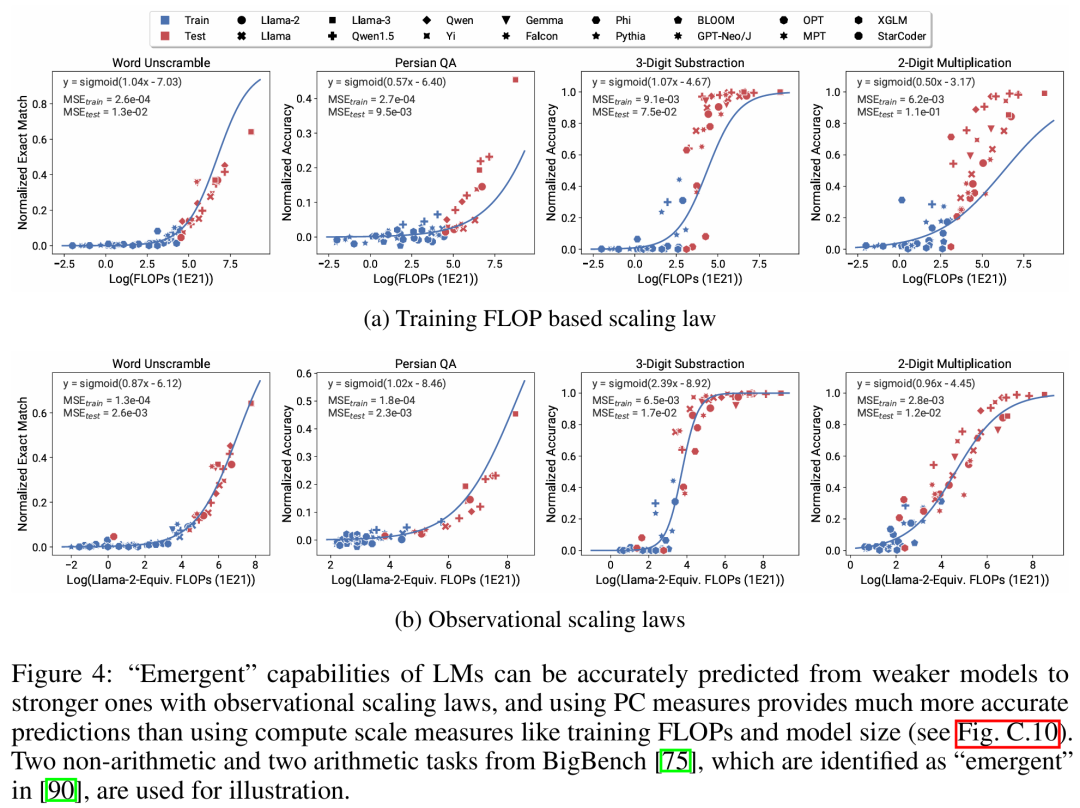
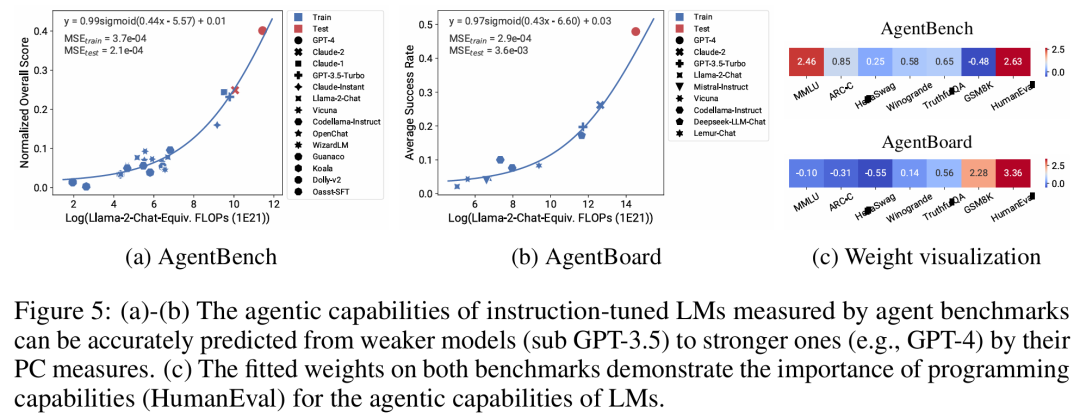
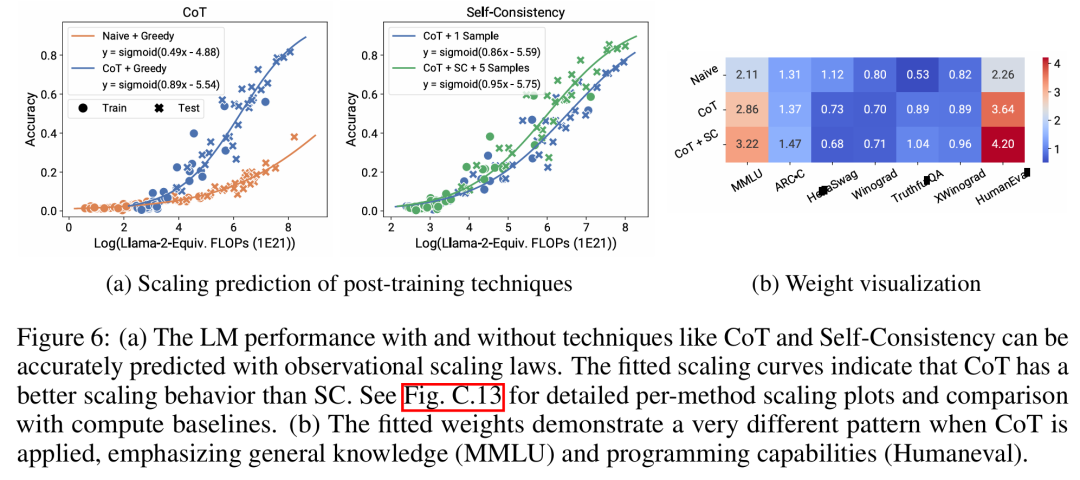
Es gibt drei Autoren s von Der Artikel, unter dem Yangjun Ruan ein chinesischer Autor ist, schloss sein Studium an der Zhejiang-Universität ab. Dieser Artikel erhielt auch einen weitergeleiteten Kommentar von Jason Wei, dem Antragsteller der Denkkette, der sagte, dass ihm diese Forschung sehr gut gefallen habe. Die Studie ergab, dass derzeit Hunderte von offenen Modellen mit unterschiedlichen Maßstäben und Fähigkeiten existieren. Allerdings können Forscher diese Modelle nicht direkt zur Berechnung von Expansionsgesetzen verwenden (da die Recheneffizienz des Trainings zwischen den Modellfamilien stark variiert), aber die Forscher hoffen, dass es ein allgemeineres Expansionsgesetz gibt, das für Modellfamilien gilt. In diesem Artikel wird insbesondere davon ausgegangen, dass die Downstream-Leistung von LMs eine Funktion des niederdimensionalen Fähigkeitsraums ist (z. B. Verständnis natürlicher Sprache, Argumentation und Codegenerierung) und dass sich Modellfamilien nur in ihrer Effizienz unterscheiden bei der Umwandlung von Trainingsberechnungen in diese Fähigkeiten. Wenn diese Beziehung wahr ist, würde dies bedeuten, dass es eine logarithmisch lineare Beziehung von niedrigdimensionalen Fähigkeiten zu nachgelagerten Fähigkeiten über Modellfamilien hinweg gibt (was es Forschern ermöglichen würde, Skalierungsgesetze anhand vorhandener Modelle festzulegen) (Abbildung 1). Diese Studie erhielt kostengünstige, hochauflösende Erweiterungsvorhersagen unter Verwendung von fast 80 öffentlich verfügbaren LMs (rechts). 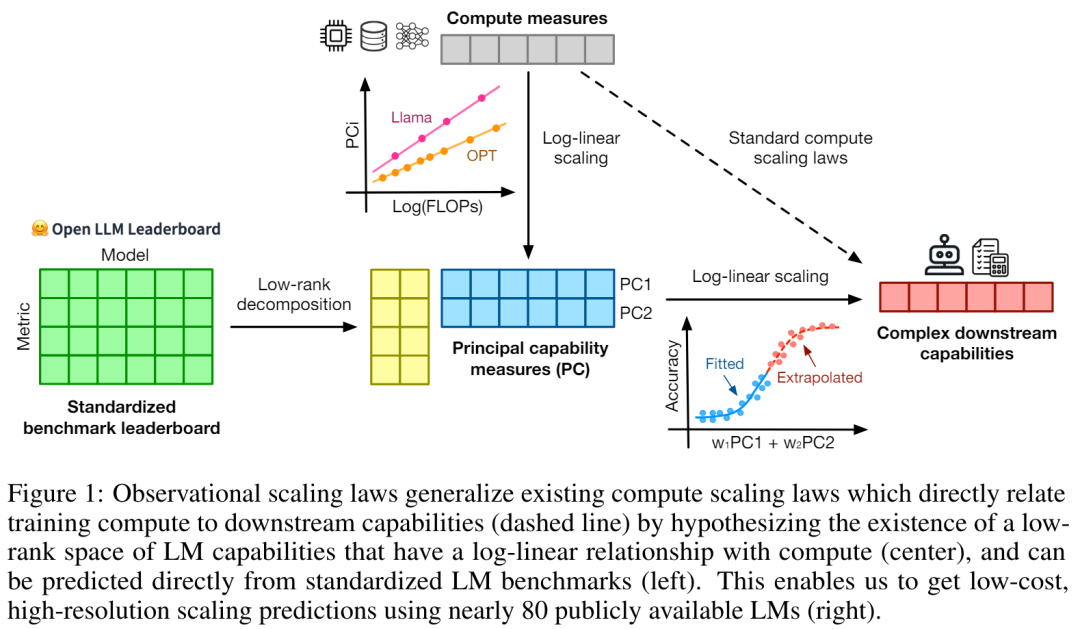 Durch die Analyse standardmäßiger LM-Benchmarks (z. B. Open LLM Leaderboard) haben Forscher einige solcher Fähigkeitsmaße entdeckt, die in einem Expansionsgesetz mit dem Rechenaufwand innerhalb der Modellfamilie zusammenhängen (R^2 > 0,9) (siehe Abbildung 3 unten), und dieser Zusammenhang besteht auch zwischen verschiedenen Modellfamilien und nachgelagerten Indikatoren. Dieser Artikel nennt diese Expansionsbeziehung das beobachtbare Expansionsgesetz. Abschließend zeigt diese Studie, dass die Verwendung beobachtbarer Expansionsgesetze kostengünstig und einfach ist, da es einige Modellreihen gibt, die ausreichen, um viele der Kernergebnisse der Studie zu reproduzieren. Mit diesem Ansatz stellte die Studie fest, dass Skalierungsvorhersagen für Interventionen zu Beginn und nach dem Training leicht durch die Auswertung von nur 10–20 Modellen erreicht werden können.Es gab eine hitzige Debatte darüber, ob LM bei bestimmten Rechenschwellen diskontinuierliche „aufkommende“ Fähigkeiten hat und ob diese Fähigkeiten mithilfe kleiner Modelle vorhergesagt werden können. Beobachtbare Expansionsgesetze legen nahe, dass einige dieser Phänomene glatten S-förmigen Kurven folgen und mithilfe kleiner Sub-Llama-2-7B-Modelle genau vorhergesagt werden können. Diese Studie zeigt, dass LM als fortgeschrittenere und komplexere Fähigkeiten eines Agenten, gemessen mit AgentBench und AgentBoard, mithilfe beobachtbarer Expansionsgesetze vorhergesagt werden kann. Durch beobachtbare Skalierungsgesetze sagt die Studie die Leistung von GPT-4 genau voraus, indem nur ein schwächeres Modell (unter GPT-3.5) verwendet wird, und identifiziert Programmierfähigkeit als einen Faktor, der die Agentenleistung antreibt. Post-Training-Methodenerweiterung Diese Studie zeigt, dass das Expansionsgesetz Post-Training-Methoden zuverlässig vorhersagen kann, selbst wenn es an ein schwächeres Modell (sub Llama-2 7B) angepasst wird. Vorteile wie Chain -des-Gedankens, Selbstkonsistenz usw. Insgesamt besteht der Beitrag dieser Studie darin, ein beobachtbares Skalierungsgesetz vorzuschlagen, das vorhersehbare logarithmisch-lineare Beziehungen zwischen Berechnungen, einfachen Fähigkeitsmaßen und komplexen nachgelagerten Indikatoren nutzt. Verifizierung beobachtbarer ExpansionsgesetzeForscher haben die Nützlichkeit dieser Expansionsgesetze durch Experimente überprüft. Darüber hinaus haben die Forscher nach der Veröffentlichung des Papiers auch Vorhersagen für zukünftige Modelle vorab registriert, um zu testen, ob das Expansionsgesetz dem aktuellen Modell zu gut entspricht. Der relevante Code zum Implementierungsprozess und zur Datenerfassung wurde auf GitHub veröffentlicht: GitHub-Adresse: https://github.com/ryoungj/ObsScalingVorhersagbarkeit neu entstehender Fähigkeiten Abbildung 4 unten zeigt die Vorhersageergebnisse mithilfe der PC-Messung (Hauptfähigkeit) und die Basisergebnisse der Vorhersageleistung basierend auf Trainings-FLOPs. Es zeigt sich, dass diese Fähigkeiten mithilfe unserer PC-Metrik genau vorhergesagt werden können, selbst wenn nur ein Modell mit schlechter Leistung verwendet wird. Im Gegensatz dazu führt die Verwendung von Trainings-FLOPs zu einer deutlich schlechteren Extrapolation auf dem Testsatz und einer deutlich schlechteren Passform auf dem Trainingssatz, wie höhere MSE-Werte zeigen. Diese Unterschiede können durch das Training von FLOPs für verschiedene Modellfamilien verursacht werden. Vorhersagbarkeit der Agentenfähigkeit Abbildung 5 unten zeigt die Vorhersageergebnisse des beobachtbaren Expansionsgesetzes unter Verwendung der PC-Metrik. Es zeigt sich, dass bei beiden Agenten-Benchmarks die Leistung des Hold-out-Modells (GPT-4 oder Claude-2) unter Verwendung der PC-Metrik anhand des Modells mit schwächerer Leistung (mehr als 10 % Lücke) genau vorhergesagt werden kann. Dies zeigt, dass die komplexeren Agentenfähigkeiten von LMs eng mit ihren zugrunde liegenden Modellfähigkeiten zusammenhängen und auf dieser Grundlage Vorhersagen treffen können. Dies zeigt auch, dass LM-basierte Agentenfunktionen gute Skalierbarkeitseigenschaften aufweisen, da Backbone-LMs immer größer werden. Auswirkung von Post-Training-TechnikenAbbildung 6a unten zeigt die Expansionsvorhersageergebnisse von CoT und SC (Selbstkonsistenz, Selbstkonsistenz) unter Verwendung beobachtbarer Expansionsgesetze. Es kann festgestellt werden, dass die Leistung stärkerer, größerer Modelle, die CoT und CoT+SC ohne (naive) Post-Training-Techniken verwenden, aus den schwächeren Modellen mit kleinerem Rechenmaßstab (wie Modellgröße und Trainings-FLOPs) genau vorhergesagt werden kann. Es ist erwähnenswert, dass die Skalierungstrends zwischen den beiden Technologien unterschiedlich sind, wobei CoT einen offensichtlicheren Skalierungstrend aufweist als die Verwendung der Selbstkonsistenz von CoT.Weitere technische Details finden Sie im Originalpapier.
Durch die Analyse standardmäßiger LM-Benchmarks (z. B. Open LLM Leaderboard) haben Forscher einige solcher Fähigkeitsmaße entdeckt, die in einem Expansionsgesetz mit dem Rechenaufwand innerhalb der Modellfamilie zusammenhängen (R^2 > 0,9) (siehe Abbildung 3 unten), und dieser Zusammenhang besteht auch zwischen verschiedenen Modellfamilien und nachgelagerten Indikatoren. Dieser Artikel nennt diese Expansionsbeziehung das beobachtbare Expansionsgesetz. Abschließend zeigt diese Studie, dass die Verwendung beobachtbarer Expansionsgesetze kostengünstig und einfach ist, da es einige Modellreihen gibt, die ausreichen, um viele der Kernergebnisse der Studie zu reproduzieren. Mit diesem Ansatz stellte die Studie fest, dass Skalierungsvorhersagen für Interventionen zu Beginn und nach dem Training leicht durch die Auswertung von nur 10–20 Modellen erreicht werden können.Es gab eine hitzige Debatte darüber, ob LM bei bestimmten Rechenschwellen diskontinuierliche „aufkommende“ Fähigkeiten hat und ob diese Fähigkeiten mithilfe kleiner Modelle vorhergesagt werden können. Beobachtbare Expansionsgesetze legen nahe, dass einige dieser Phänomene glatten S-förmigen Kurven folgen und mithilfe kleiner Sub-Llama-2-7B-Modelle genau vorhergesagt werden können. Diese Studie zeigt, dass LM als fortgeschrittenere und komplexere Fähigkeiten eines Agenten, gemessen mit AgentBench und AgentBoard, mithilfe beobachtbarer Expansionsgesetze vorhergesagt werden kann. Durch beobachtbare Skalierungsgesetze sagt die Studie die Leistung von GPT-4 genau voraus, indem nur ein schwächeres Modell (unter GPT-3.5) verwendet wird, und identifiziert Programmierfähigkeit als einen Faktor, der die Agentenleistung antreibt. Post-Training-Methodenerweiterung Diese Studie zeigt, dass das Expansionsgesetz Post-Training-Methoden zuverlässig vorhersagen kann, selbst wenn es an ein schwächeres Modell (sub Llama-2 7B) angepasst wird. Vorteile wie Chain -des-Gedankens, Selbstkonsistenz usw. Insgesamt besteht der Beitrag dieser Studie darin, ein beobachtbares Skalierungsgesetz vorzuschlagen, das vorhersehbare logarithmisch-lineare Beziehungen zwischen Berechnungen, einfachen Fähigkeitsmaßen und komplexen nachgelagerten Indikatoren nutzt. Verifizierung beobachtbarer ExpansionsgesetzeForscher haben die Nützlichkeit dieser Expansionsgesetze durch Experimente überprüft. Darüber hinaus haben die Forscher nach der Veröffentlichung des Papiers auch Vorhersagen für zukünftige Modelle vorab registriert, um zu testen, ob das Expansionsgesetz dem aktuellen Modell zu gut entspricht. Der relevante Code zum Implementierungsprozess und zur Datenerfassung wurde auf GitHub veröffentlicht: GitHub-Adresse: https://github.com/ryoungj/ObsScalingVorhersagbarkeit neu entstehender Fähigkeiten Abbildung 4 unten zeigt die Vorhersageergebnisse mithilfe der PC-Messung (Hauptfähigkeit) und die Basisergebnisse der Vorhersageleistung basierend auf Trainings-FLOPs. Es zeigt sich, dass diese Fähigkeiten mithilfe unserer PC-Metrik genau vorhergesagt werden können, selbst wenn nur ein Modell mit schlechter Leistung verwendet wird. Im Gegensatz dazu führt die Verwendung von Trainings-FLOPs zu einer deutlich schlechteren Extrapolation auf dem Testsatz und einer deutlich schlechteren Passform auf dem Trainingssatz, wie höhere MSE-Werte zeigen. Diese Unterschiede können durch das Training von FLOPs für verschiedene Modellfamilien verursacht werden. Vorhersagbarkeit der Agentenfähigkeit Abbildung 5 unten zeigt die Vorhersageergebnisse des beobachtbaren Expansionsgesetzes unter Verwendung der PC-Metrik. Es zeigt sich, dass bei beiden Agenten-Benchmarks die Leistung des Hold-out-Modells (GPT-4 oder Claude-2) unter Verwendung der PC-Metrik anhand des Modells mit schwächerer Leistung (mehr als 10 % Lücke) genau vorhergesagt werden kann. Dies zeigt, dass die komplexeren Agentenfähigkeiten von LMs eng mit ihren zugrunde liegenden Modellfähigkeiten zusammenhängen und auf dieser Grundlage Vorhersagen treffen können. Dies zeigt auch, dass LM-basierte Agentenfunktionen gute Skalierbarkeitseigenschaften aufweisen, da Backbone-LMs immer größer werden. Auswirkung von Post-Training-TechnikenAbbildung 6a unten zeigt die Expansionsvorhersageergebnisse von CoT und SC (Selbstkonsistenz, Selbstkonsistenz) unter Verwendung beobachtbarer Expansionsgesetze. Es kann festgestellt werden, dass die Leistung stärkerer, größerer Modelle, die CoT und CoT+SC ohne (naive) Post-Training-Techniken verwenden, aus den schwächeren Modellen mit kleinerem Rechenmaßstab (wie Modellgröße und Trainings-FLOPs) genau vorhergesagt werden kann. Es ist erwähnenswert, dass die Skalierungstrends zwischen den beiden Technologien unterschiedlich sind, wobei CoT einen offensichtlicheren Skalierungstrend aufweist als die Verwendung der Selbstkonsistenz von CoT.Weitere technische Details finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonKonstruktion eines Skalierungsgesetzes aus 80 Modellen: eine neue Arbeit eines chinesischen Doktoranden, die vom Autor der Denkkette wärmstens empfohlen wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!






 So entfernen Sie die Firefox-Sicherheitssperre
So entfernen Sie die Firefox-Sicherheitssperre
 So kündigen Sie die automatische Verlängerung der Taobao Money Saving Card
So kündigen Sie die automatische Verlängerung der Taobao Money Saving Card
 Was bedeutet Apple LTE-Netzwerk?
Was bedeutet Apple LTE-Netzwerk?
 vscode erstellt eine HTML-Dateimethode
vscode erstellt eine HTML-Dateimethode
 Einschaltkennwort in XP aufheben
Einschaltkennwort in XP aufheben
 Netzwerkrahmen
Netzwerkrahmen
 Einführung in das Dokument in JS
Einführung in das Dokument in JS
 Was sind die Befehle zum Herunterfahren von Linux?
Was sind die Befehle zum Herunterfahren von Linux?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



