Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail zur Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Richard Sutton hat in „The Bitter Lesson“ diese Bewertung vorgenommen: „Die beste Schlussfolgerung, die aus 70 Jahren Forschung im Bereich der künstlichen Intelligenz gezogen werden kann, ist die Eine wichtige Lektion ist, dass allgemeine Methoden, die Berechnungen nutzen, letztendlich am effizientesten sind und die Vorteile enorm sind. Anfang dieses Jahres schlug das Team von Professor Gu Quanquan an der University of California, Los Angeles (UCLA) ein „Self-Play Fine-Tuning (SPIN)“ vor, das keine zusätzlichen Feinabstimmungsdaten verwendet und setzt nur auf Selbstspiel. Gaming kann die Fähigkeiten von LLM erheblich verbessern.
Kürzlich haben das Team von Professor Gu Quanquan und das Team von Professor Yiming Yang an der Carnegie Mellon University (CMU) zusammengearbeitet, um eine Methode namens „Self-Play Preference Optimization (SPPO)“ zu entwickeln. Ziel dieser neuen Methode ist die Ausrichtungstechnologie das Verhalten großer Sprachmodelle durch ein Selbstspiel-Framework, um menschliche Vorlieben besser anzupassen. Kämpfe von links nach rechts gegeneinander und zeige erneut deine magischen Kräfte!
Papiertitel: Self-Play Preference Optimization for Language Model Alignment
Papierlink: https://arxiv.org/pdf/2405.00675.pdf
Technologie Hintergrund und Herausforderungen
Große Sprachmodelle (LLM) werden zu einer wichtigen treibenden Kraft im Bereich der künstlichen Intelligenz und leisten mit ihren hervorragenden Textgenerierungs- und Textverständnisfähigkeiten bei verschiedenen Aufgaben gute Dienste. Obwohl die Fähigkeiten von LLM beeindruckend sind, ist häufig eine Feinabstimmung durch einen Ausrichtungsprozess erforderlich, um das Ausgabeverhalten dieser Modelle besser an die Anforderungen praktischer Anwendungen anzupassen. Der Schlüssel zu diesem Prozess besteht darin, das Modell so anzupassen, dass es menschliche Vorlieben und Verhaltensnormen besser widerspiegelt. Gängige Methoden sind das Reinforcement Learning auf Basis menschlichen Feedbacks (RLHF) oder die direkte Präferenzoptimierung (Direct Preference Optimization, DPO).
Auf menschlichem Feedback basierendes Verstärkungslernen (RLHF) basiert auf der expliziten Aufrechterhaltung eines Belohnungsmodells, um große Sprachmodelle anzupassen und zu verfeinern. Mit anderen Worten: InstructGPT trainiert beispielsweise zunächst eine Belohnungsfunktion, die dem Bradley-Terry-Modell auf der Grundlage menschlicher Präferenzdaten folgt, und verwendet dann verstärkende Lernalgorithmen wie Proximal Policy Optimization (PPO), um große Sprachmodelle zu optimieren. Letztes Jahr schlugen Forscher die Direct Preference Optimization (DPO) vor.
Im Gegensatz zu RLHF, das ein explizites Belohnungsmodell verwaltet, gehorcht der DPO-Algorithmus implizit dem Bradley-Terry-Modell, kann aber direkt für die Optimierung großer Sprachmodelle verwendet werden. In bestehenden Arbeiten wurde versucht, große Modelle durch die Verwendung von DPO über mehrere Iterationen weiter zu verfeinern (Abbildung 1).
‐ Numerische Punktzahl. Obwohl diese Modelle vernünftige Näherungen an menschliche Vorlieben liefern, können sie die Komplexität menschlichen Verhaltens nicht vollständig erfassen. 
Diese Modelle gehen oft davon aus, dass die Präferenzbeziehung zwischen verschiedenen Entscheidungen monoton und transitiv ist, während empirische Beweise oft die Inkonsistenz und Nichtlinearität der menschlichen Entscheidungsfindung zeigen. Tverskys Studie stellte beispielsweise fest, dass die menschliche Entscheidungsfindung beeinflusst werden kann Eine Vielzahl von Faktoren beeinflussen es und zeigen Inkonsistenzen.
Theoretische Grundlagen und Methode von SPPO两 Abbildung 2. Die beiden Sprachmodelle des Imaginären werden oft gespielt und gespielt.
In diesem Zusammenhang schlägt der Autor ein neues Selbstspiel-Framework SPPO vor, das nicht nur nachweisbare Garantien für die Lösung von Spielen mit konstanter Summe für zwei Spieler bietet, sondern auch große Sprachmodelle effizient verfeinert skaliert im großen Maßstab.
Konkret definiert der Artikel das RLHF-Problem streng als ein Normalsummenspiel für zwei Spieler (Abbildung 2). Ziel dieser Arbeit ist es, Nash-Gleichgewichtsstrategien zu identifizieren, die im Durchschnitt immer eine bevorzugtere Reaktion liefern als jede andere Strategie.
Um die Nash-Gleichgewichtsstrategie näherungsweise zu identifizieren, übernimmt der Autor den klassischen adaptiven Online-Algorithmus mit multiplikativen Gewichten als übergeordneten Rahmenalgorithmus zur Lösung des Zwei-Spieler-Spiels.
Innerhalb jedes Schritts dieses Frameworks kann der Algorithmus multiplikative Gewichtsaktualisierungen durch einen Selbstspielmechanismus approximieren, bei dem sich das große Sprachmodell in jeder Runde an der vorherigen Runde orientiert, die vom Modell Synthesize generiert wurde Anmerkungen zu Daten und Präferenzmodellen zur Optimierung.
Insbesondere generiert das große Sprachmodell auf der Grundlage der Annotation des Präferenzmodells mehrere Antworten. Dadurch kann der Algorithmus eine weitere Feinabstimmung vornehmen Das große Sprachmodell sorgt dafür, dass die Wahrscheinlichkeit, dass Antworten mit einer hohen Gewinnquote erscheinen, höher ist (Abbildung 3).

Experimentelles Design und ErgebnisseIn Im Rahmen des Experiments übernahm das Forschungsteam einen Mistral-7B als Basismodell und nutzte 60.000 Eingabeaufforderungen aus dem UltraFeedback-Datensatz für unbeaufsichtigtes Training. Sie fanden heraus, dass das Modell durch Selbstspielen seine Leistung auf mehreren Bewertungsplattformen wie AlpacaEval 2.0 und MT-Bench deutlich verbessern konnte. Diese Plattformen werden häufig zur Bewertung der Qualität und Relevanz modellgenerierter Texte verwendet. Durch die SPPO-Methode verbessert sich das Modell nicht nur hinsichtlich der Flüssigkeit und Genauigkeit
des generierten Textes, sondern, was noch wichtiger ist: „Es entspricht besser den menschlichen Werten und Vorlieben.“ O Abbildung 4. Die Wirkung des SPPO-Modells auf Alpacaeval 2.0 ist deutlich verbessert und höher als bei anderen Benchmark-Methoden wie ITERATIVE DPO.
Im Test von AlpacaEval 2.0 (Abbildung 4) verbesserte das SPPO-optimierte Modell die Gewinnrate der Längenkontrolle von 17,11 % des Basismodells auf 28,53 %, was eine deutliche Verbesserung seines Verständnisses menschlicher Vorlieben zeigt . Das durch drei SPPO-Runden optimierte Modell ist deutlich besser als die mehrstufige Iteration von DPO, IPO und dem selbstbelohnenden Sprachmodell (Self-Rewarding LM) auf AlpacaEval2.0.
Darüber hinaus übertraf die Leistung des Modells auf MT-Bench auch herkömmliche Modelle, die durch menschliches Feedback optimiert wurden. Dies zeigt die Wirksamkeit von SPPO bei der automatischen Anpassung des Modellverhaltens an komplexe Aufgaben. 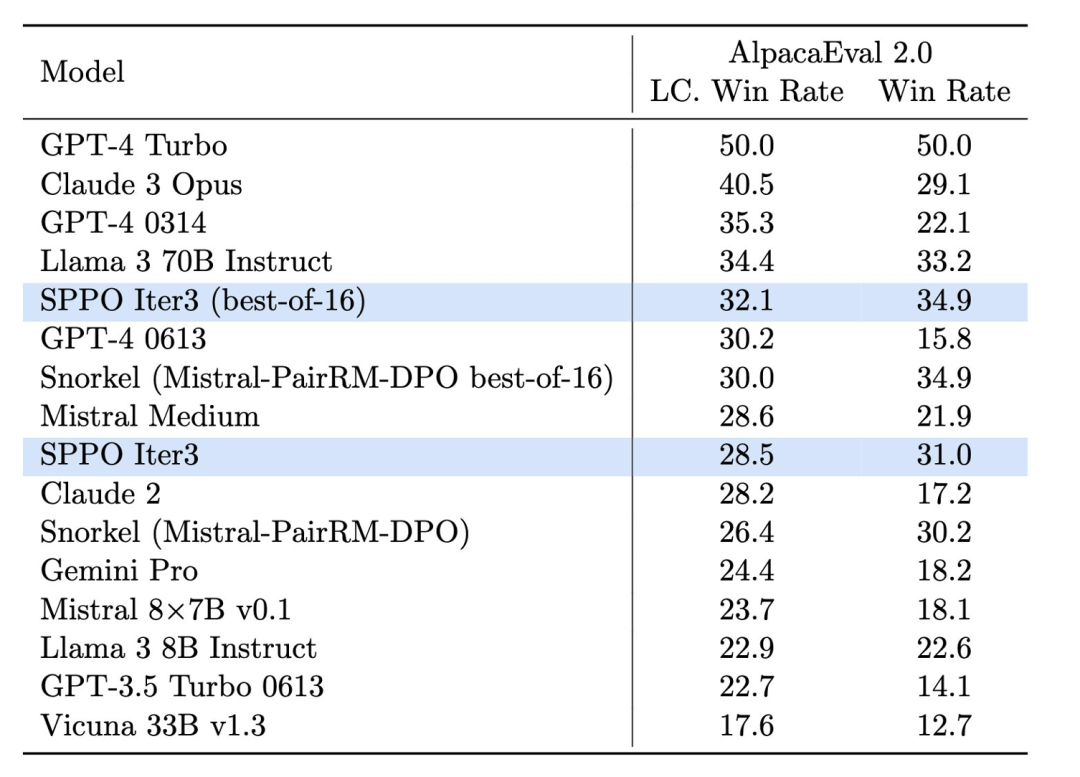
Fazit und Zukunftsaussichten
Self-Playing Preference Optimization (SPPO) bietet einen neuen Optimierungspfad für große Sprachmodelle, der nicht nur die Qualität der Modellgenerierung, sondern, was noch wichtiger ist, verbessert Qualität des Modells. Ausrichtung auf menschliche Vorlieben.
Mit der kontinuierlichen Weiterentwicklung und Optimierung der Technologie wird erwartet, dass SPPO und seine abgeleiteten Technologien eine größere Rolle bei der nachhaltigen Entwicklung und sozialen Anwendung künstlicher Intelligenz spielen und den Weg für den Aufbau intelligenterer und verantwortungsvollerer KI-Systeme ebnen . der Weg. Das obige ist der detaillierte Inhalt vonDie menschliche Präferenz ist der Herrscher! Mit der SPPO-Ausrichtungstechnologie können große Sprachmodelle miteinander und mit sich selbst konkurrieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



