


Die Funktionsauswahl ist ein wichtiger Schritt im Prozess der Erstellung eines Modells für maschinelles Lernen. Die Auswahl guter Funktionen für das Modell und die Aufgabe, die wir ausführen möchten, kann die Leistung verbessern.

Wenn es sich um hochdimensionale Datensätze handelt, ist die Auswahl von Features besonders wichtig. Dadurch kann das Modell schneller und besser lernen. Die Idee besteht darin, die optimale Anzahl an Funktionen und die aussagekräftigsten Funktionen zu finden.
In diesem Artikel werden wir eine neue Funktionsauswahl durch Verstärkungslernstrategie vorstellen und implementieren. Wir beginnen mit der Diskussion des verstärkenden Lernens, insbesondere der Markov-Entscheidungsprozesse. Es handelt sich um eine sehr neue Methode im Bereich der Datenwissenschaft, die sich besonders für die Merkmalsauswahl eignet. Anschließend werden die Implementierung und die Installation und Verwendung der Python-Bibliothek (FSRLearning) vorgestellt. Abschließend wird dieser Vorgang anhand eines einfachen Beispiels demonstriert.
Reinforcement Learning (RL)-Techniken können bei der Lösung von Problemen wie dem Lösen von Spielen sehr effektiv sein. Das Konzept des Reinforcement Learning basiert auf dem Markov Decision Process (MDP). Hier geht es nicht darum, eine detaillierte Definition zu geben, sondern darum, ein allgemeines Verständnis dafür zu erlangen, wie es funktioniert und wie es für unser Problem nützlich sein kann. Beim verstärkenden Lernen lernt ein Agent, indem er mit seiner Umgebung interagiert. Es trifft Entscheidungen, indem es den aktuellen Zustand und Belohnungssignale beobachtet, und erhält je nach gewählter Aktion positives oder negatives Feedback. Das Ziel des Agenten besteht darin, die kumulative Belohnung durch das Ausprobieren verschiedener Aktionen zu maximieren. Ein wichtiges Konzept des Reinforcement Learning
Der Gedanke hinter Reinforcement Learning ist, dass der Agent in einer unbekannten Umgebung startet. Sammle Aktionen, um die Mission abzuschließen. Der Agent wird aufgrund seines aktuellen Zustands und zuvor ausgewählter Aktionen eher geneigt sein, bestimmte Aktionen auszuwählen. Jedes Mal, wenn ein neuer Zustand erreicht und eine Aktion ausgeführt wird, erhält der Agent eine Belohnung. Hier sind die Hauptparameter, die wir für die Funktionsauswahl definieren müssen:
Zustand, Aktion, Belohnung, Auswahl der Aktion
Erstens die Teilmenge der im Datensatz vorhandenen Funktionen. Wenn der Datensatz beispielsweise über drei Merkmale (Alter, Geschlecht, Größe) und eine Bezeichnung verfügt, lauten die möglichen Zustände wie folgt:
[] --> Empty set [Age], [Gender], [Height] --> 1-feature set [Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set [Age, Gender, Height] --> All-feature set
In einem Zustand spielt die Reihenfolge der Merkmale keine Rolle, wir müssen nachsehen Dabei erstellen Sie eine Sammlung, keine Liste von Funktionen.
In Bezug auf Aktionen können wir von einer Teilmenge zu einer beliebigen Teilmenge unerforschter Funktionen übergehen. Bei einem Feature-Auswahlproblem besteht die Aktion darin, Features auszuwählen, die im aktuellen Zustand noch nicht erforscht wurden, und sie dem nächsten Zustand hinzuzufügen. Hier sind einige mögliche Aktionen:
[Age] -> [Age, Gender] [Gender, Height] -> [Age, Gender, Height]
Hier ist ein Beispiel für eine unmögliche Aktion:
[Age] -> [Age, Gender, Height] [Age, Gender] -> [Age] [Gender] -> [Gender, Gender]
Wir haben den Zustand und die Aktion definiert, noch nicht die Belohnung. Die Belohnung ist eine reelle Zahl, die zur Bewertung der Qualität des Staates verwendet wird.
Bei Funktionsauswahlproblemen besteht eine mögliche Belohnung darin, die Genauigkeitsmetrik desselben Modells durch Hinzufügen neuer Funktionen zu verbessern. Hier ist ein Beispiel für die Berechnung der Belohnung:
[Age] --> Accuracy = 0.65 [Age, Gender] --> Accuracy = 0.76 Reward(Gender) = 0.76 - 0.65 = 0.11
Für jeden Staat, den wir zum ersten Mal besuchen, wird ein Klassifikator (Modell) anhand einer Reihe von Funktionen trainiert. Dieser Wert wird im Zustand und im entsprechenden Klassifikator gespeichert. Das Training des Klassifikators ist zeitaufwändig und mühsam, daher trainieren wir ihn nur einmal. Da der Klassifikator die Reihenfolge der Merkmale nicht berücksichtigt, können wir dieses Problem als Diagramm und nicht als Baum behandeln. In diesem Beispiel ist die Belohnung für die Auswahl von „Geschlecht“ als neues Merkmal für das Modell der Unterschied in der Genauigkeit zwischen dem aktuellen Zustand und dem nächsten Zustand.
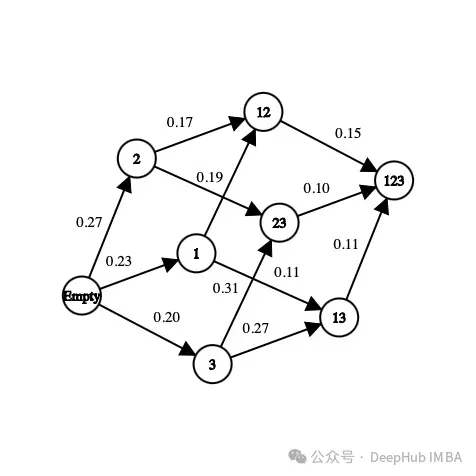
Im Bild oben ist jedes Merkmal einer Zahl zugeordnet („Alter“ ist 1, „Geschlecht“ ist 2 und „Größe“ ist 3). Wie wählen wir aus dem aktuellen Zustand den nächsten aus oder wie erkunden wir die Umgebung?
Wir müssen den optimalen Weg finden, denn wenn wir alle möglichen Feature-Sets in einem Problem mit 10 Features untersuchen, beträgt die Anzahl der Zustände
10! + 2 = 3 628 802
这里的+2是因为考虑一个空状态和一个包含所有可能特征的状态。我们不可能在每个状态下都训练一个模型,这是不可能完成的,而且这只是有10个特征,如果有100个特征那基本上就是无解了。
但是在强化学习方法中,我们不需要在所有的状态下都去训练一个模型,我们要为这个问题确定一些停止条件,比如从当前状态随机选择下一个动作,概率为epsilon(介于0和1之间,通常在0.2左右),否则选择使函数最大化的动作。对于特征选择是每个特征对模型精度带来的奖励的平均值。
这里的贪心算法包含两个步骤:
1、以概率为epsilon,我们在当前状态的可能邻居中随机选择下一个状态
2、选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了减少时间复杂度,可以初始化了一个包含每个特征值的列表。每当选择一个特性时,此列表就会更新。使用以下公式,更新是非常理想的:
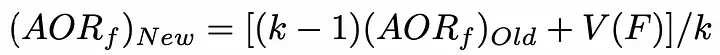
AORf:特征“f”带来的奖励的平均值
K: f被选中的次数
V(F):特征集合F的状态值(为了简单描述,本文不详细介绍)
所以我们就找出哪个特征给模型带来了最高的准确性。这就是为什么我们需要浏览不同的状态,在在许多不同的环境中评估模型特征的最全局准确值。
因为目标是最小化算法访问的状态数,所以我们访问的未访问过的状态越少,需要用不同特征集训练的模型数量就越少。因为从时间和计算能力的角度来看,训练模型以获得精度是最昂贵方法,我们要尽量减少训练的次数。
最后在任何情况下,算法都会停止在最终状态(包含所有特征的集合)而我们希望避免达到这种状态,因为用它来训练模型是最昂贵的。
上面就是我们针对于特征选择的强化学习描述,下面我们将详细介绍在python中的实现。
有一个python库可以让我们直接解决这个问题。但是首先我们先准备数据
我们直接使用UCI机器学习库中的数据:
#Get the pandas DataFrame from the csv file (15 features, 690 rows) australian_data = pd.read_csv('australian_data.csv', header=None) #DataFrame with the features X = australian_data.drop(14, axis=1) #DataFrame with the labels y = australian_data[14]然后安装我们用到的库
pip install FSRLearning
直接导入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL类就可以创建一个特性选择器。我们需要以下的参数
feature_number (integer): DataFrame X中的特性数量
feature_structure (dictionary):用于图实现的字典
eps (float [0;1]):随机选择下一状态的概率,0为贪婪算法,1为随机算法
alpha (float [0;1]):控制更新速率,0表示不更新状态,1表示经常更新状态
gamma (float[0,1]):下一状态观察的调节因子,0为近视行为状态,1为远视行为
nb_iter (int):遍历图的序列数
starting_state (" empty "或" random "):如果" empty ",则算法从空状态开始,如果" random ",则算法从图中的随机状态开始
所有参数都可以机型调节,但对于大多数问题来说,迭代大约100次就可以了,而epsilon值在0.2左右通常就足够了。起始状态对于更有效地浏览图形很有用,但它非常依赖于数据集,两个值都可以测试。
我们可以用下面的代码简单地初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
与大多数ML库相同,训练算法非常简单:
results = fsrl_obj.fit_predict(X, y)
下面是输出的一个例子:
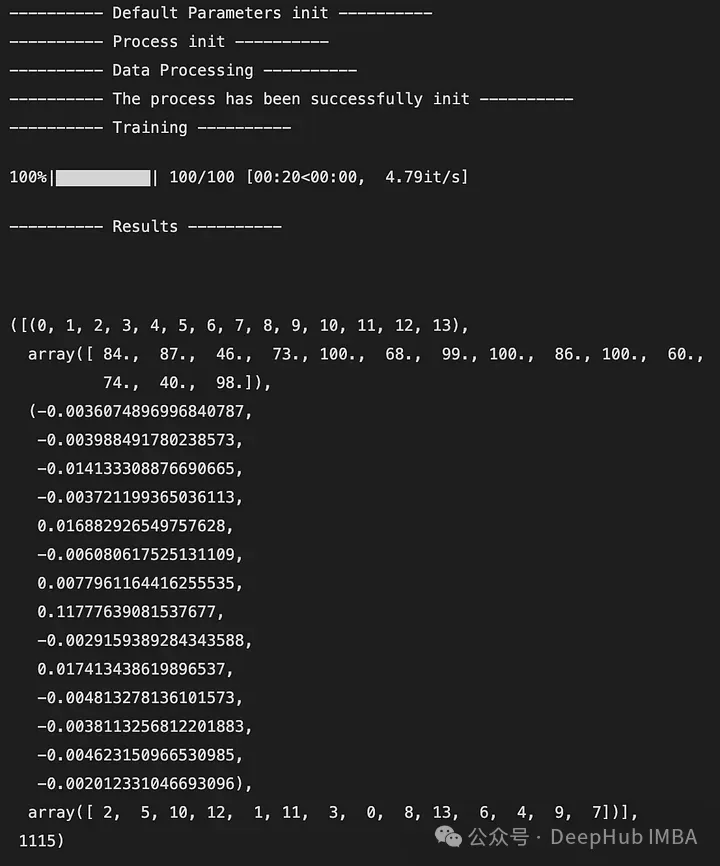
输出是一个5元组,如下所示:
DataFrame X中特性的索引(类似于映射)
特征被观察的次数
所有迭代后特征带来的奖励的平均值
从最不重要到最重要的特征排序(这里2是最不重要的特征,7是最重要的特征)
全局访问的状态数
还可以与Scikit-Learn的RFE选择器进行比较。它将X, y和选择器的结果作为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在RFE和FSRLearning的全局度量的每一步选择之后的结果。它还输出模型精度的可视化比较,其中x轴表示所选特征的数量,y轴表示精度。两条水平线是每种方法的准确度中值。
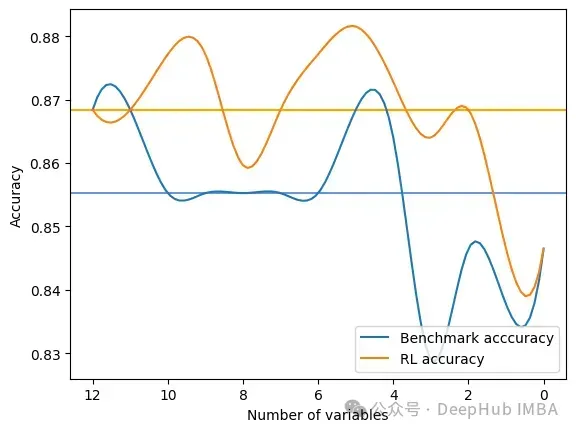
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909 Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579 Probability to get a set of variable with a better metric than RFE : 1.0 Area between the two curves : 0.17105263157894512
可以看到RL方法总是为模型提供比RFE更好的特征集。
另一个有趣的方法是get_plot_ratio_exploration。它绘制了一个图,比较一个精确迭代序列中已经访问节点和访问节点的数量。
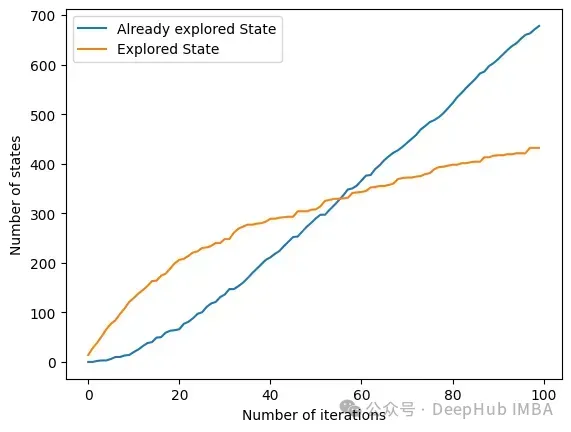
由于设置了停止条件,算法的时间复杂度呈指数级降低。即使特征的数量很大,收敛性也会很快被发现。下面的图表示一定大小的集合被访问的次数。
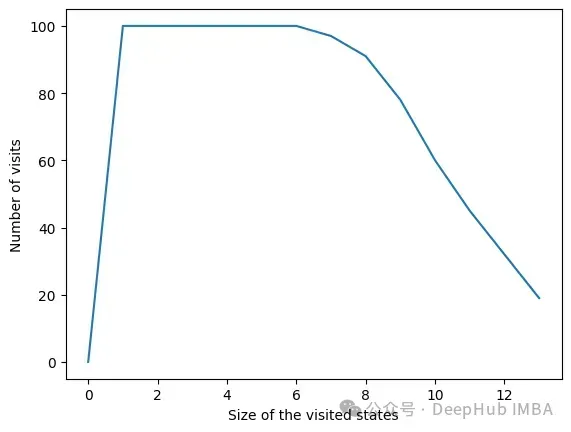
在所有迭代中,算法访问包含6个或更少变量的状态。在6个变量之外,我们可以看到达到的状态数量正在减少。这是一个很好的行为,因为用小的特征集训练模型比用大的特征集训练模型要快。
我们可以看到RL方法对于最大化模型的度量是非常有效的。它总是很快地收敛到一个有趣的特性子集。该方法在使用FSRLearning库的ML项目中非常容易和快速地实现。
Das obige ist der detaillierte Inhalt vonMerkmalsauswahl durch verstärkende Lernstrategien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wie viel entspricht Snapdragon 8gen2 Apple?
Wie viel entspricht Snapdragon 8gen2 Apple?
 So beheben Sie den Anwendungsfehler WerFault.exe
So beheben Sie den Anwendungsfehler WerFault.exe
 absoluteslayout
absoluteslayout
 Mongodb und MySQL sind einfach zu verwenden und empfehlenswert
Mongodb und MySQL sind einfach zu verwenden und empfehlenswert
 Verwendung des Zahlenformats
Verwendung des Zahlenformats
 Konvertierung von RGB in Hexadezimal
Konvertierung von RGB in Hexadezimal
 So erstellen Sie Diagramme und Datenanalysediagramme in PPT
So erstellen Sie Diagramme und Datenanalysediagramme in PPT
 Welche sind die am häufigsten verwendeten Drittanbieter-Bibliotheken in PHP?
Welche sind die am häufigsten verwendeten Drittanbieter-Bibliotheken in PHP?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



