















 PHPz
PHPz批改状态:合格
老师批语:

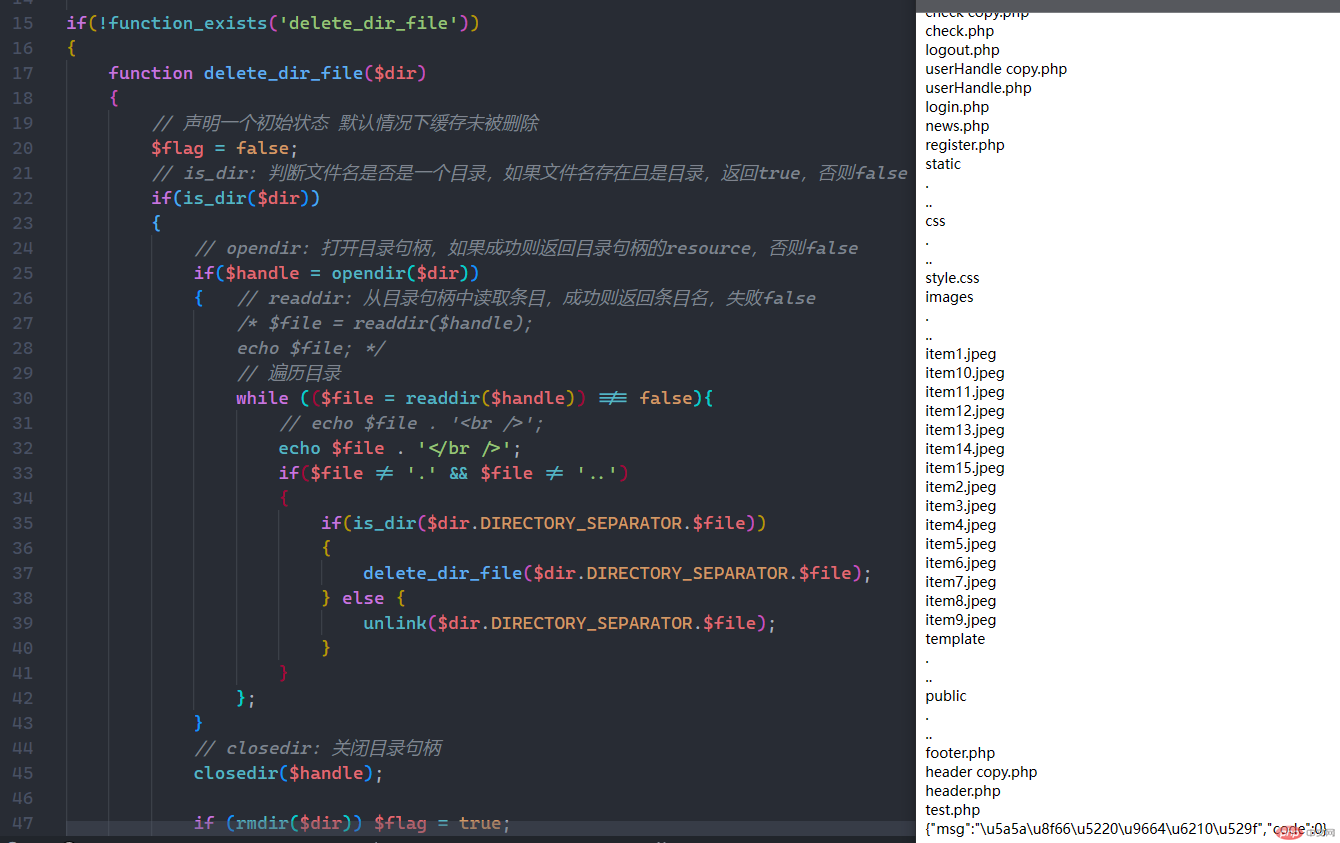
readdir: 从目录句柄中读取条目,成功则返回条目名,失败false;opendir: 打开目录句柄,如果成功则返回目录句柄的resource,否则false;closedir: 关闭目录句柄;
unlink :删除文件,成功true,失败false;is_dir: 判断文件名是否是一个目录,如果文件名存在且是目录,返回true,否则false;rmdir:尝试删除 directory 所指定的目录;
<?php/*** 函数是完成特定功能的代码块*/// 递归函数/*** delete_dir_file 删除指定目录* params: 指定需要删除的目录路径* return: 返回布尔值 成功true 失败false*/if(!function_exists('delete_dir_file')){function delete_dir_file($dir){// 声明一个初始状态 默认情况下缓存未被删除$flag = false;// is_dir: 判断文件名是否是一个目录,如果文件名存在且是目录,返回true,否则falseif(is_dir($dir)){// opendir: 打开目录句柄,如果成功则返回目录句柄的resource,否则falseif($handle = opendir($dir)){ // readdir: 从目录句柄中读取条目,成功则返回条目名,失败false/* $file = readdir($handle);echo $file; */// 遍历目录while (($file = readdir($handle)) !== false){// echo $file . '<br />';echo $file . '</br />';if($file != '.' && $file != '..'){if(is_dir($dir.DIRECTORY_SEPARATOR.$file)){delete_dir_file($dir.DIRECTORY_SEPARATOR.$file);} else {unlink($dir.DIRECTORY_SEPARATOR.$file);}}};}// closedir: 关闭目录句柄closedir($handle);if (rmdir($dir)) $flag = true;return $flag;}}}$del_path = __DIR__ . DIRECTORY_SEPARATOR . 'test';//echo $del_path;if(delete_dir_file($del_path)){echo json_encode(['msg' => '缓存删除成功','code' =>0],320);}else{echo json_encode(['msg' => '缓存删除失败','code' =>1],256);};
用字符串连接数组元素
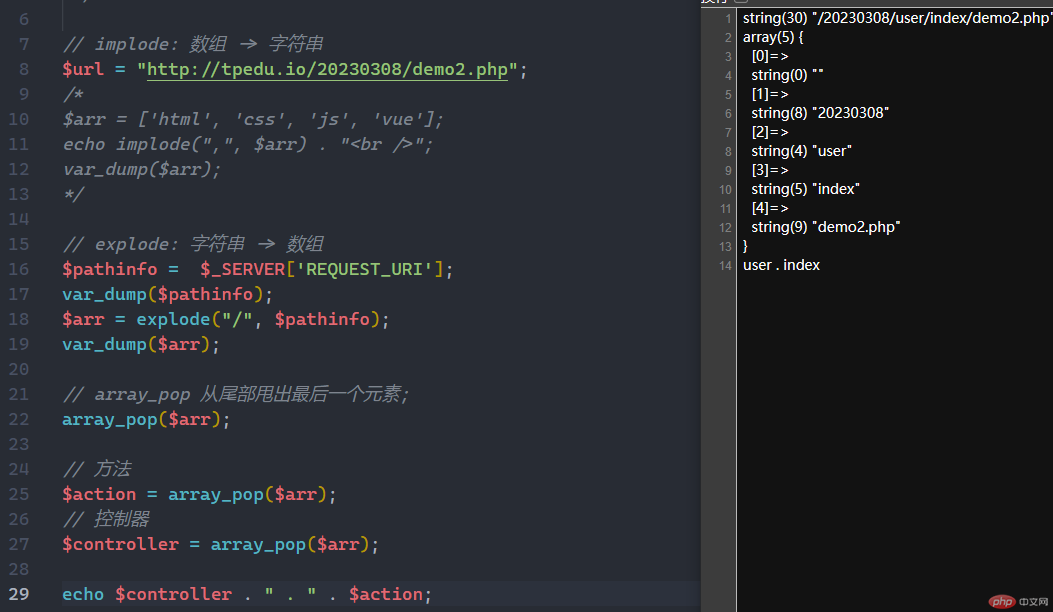
$url = "http://tpedu.io/20230308/demo2.php";$arr = ['html', 'css', 'js', 'vue'];echo implode(",", $arr) . "<br />";var_dump($arr);
使用一个字符串分割另一个字符串
$pathinfo = $_SERVER['REQUEST_URI'];var_dump($pathinfo);$arr = explode("/", $pathinfo);var_dump($arr);// array_pop 从尾部甩出最后一个元素;array_pop($arr);// 方法$action = array_pop($arr);// 控制器$controller = array_pop($arr);echo $controller . " . " . $action;
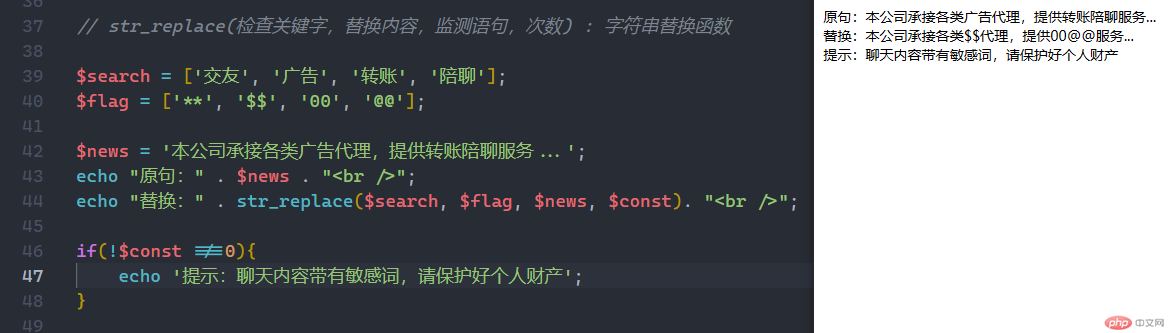
@str_replace(检查关键字,替换内容,监测语句,次数) : 字符串替换函数
$search = ['交友', '广告', '转账', '陪聊'];$flag = ['**', '$$', '00', '@@'];$news = '本公司承接各类广告代理,提供转账陪聊服务...';echo "原句:" . $news . "<br />";echo "替换:" . str_replace($search, $flag, $news, $const). "<br />";if(!$const !==0){echo '提示:聊天内容带有敏感词,请保护好个人财产';}
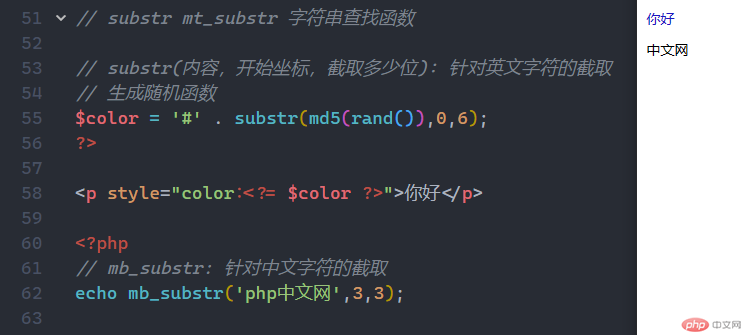
// substr(内容,开始坐标,截取多少位): 针对英文字符的截取// 生成随机函数$color = '#' . substr(md5(rand()),0,6);?><p style="color:<?= $color ?>">你好</p><?php// mb_substr: 针对中文字符的截取echo mb_substr('php中文网',3,3);
解析 URL,返回其组成部分
$url = "https://www.php.net/manual/zh/ref.strings.php?email=9526678@qq.com&id=1&gender=男";var_dump(parse_url($url));var_dump(parse_url($url, PHP_URL_PATH));

生成url-encode之后的请求字符串
$params = ['city' => '苏州', // 要查询的城市'key' => 'uwehqwjuehjbsdsdhk232323'];$paramsString = http_build_query($params);var_dump($paramsString);

urlencode 将字符串编码并将用于 URL 的请求部分
echo urlencode($url);
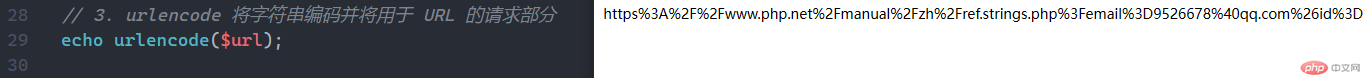
解码已编码的 URL 字符串
echo urldecode('%E8%8B%8F%E5%B7%9E');

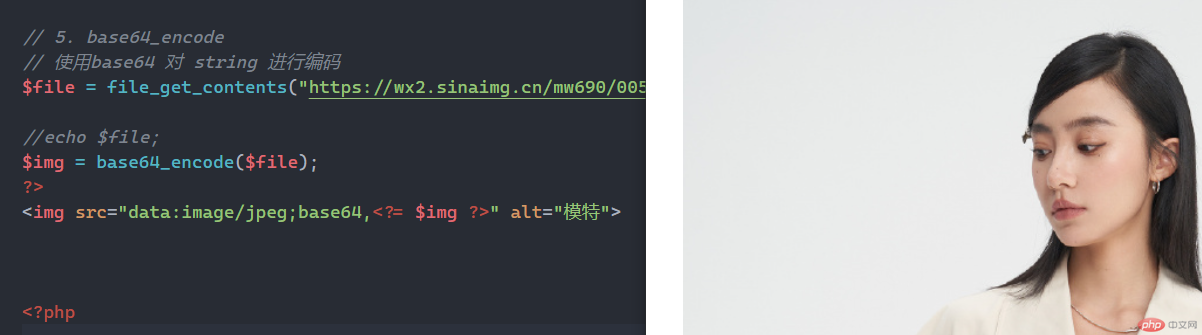
使用base64 对 string 进行编码
$file = file_get_contents("https://wx2.sinaimg.cn/mw690/005OZPj8ly1hbsi593483j31e0230x29.jpg");//echo $file;$img = base64_encode($file);?><img src="data:image/jpeg;base64,<?= $img ?>" alt="模特">
对 base64 编码的 string 进行解码。
base64_decode($img);

Copyright 2014-2025 //m.sbmmt.com/ All Rights Reserved | php.cn | 湘ICP备2023035733号



